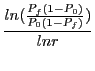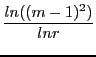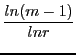Next: Experiments with the fitnes Up: Theoretical Limits and Benchmarks Previous: Pattern Characteristics Contents
As one can see in the preceding empirical experiments the time needed to approach a solution set - a goal - varies depending from different properties of the GA used.
The topic is very large and we can report here only some introductory remarks. For a deeper understanding one has to read the original papers.
Convergence is an important topic for GAs. Convergence is
basically given as the fact that in a sequence of populations
![]() the overall fitness value of the populations
becomes more and more similar and from a certain number of cycles
the overall fitness value of the populations
becomes more and more similar and from a certain number of cycles ![]() onwards it
dos not change any more, or only within a given limit
onwards it
dos not change any more, or only within a given limit ![]() .
.
While Goldberg 1989 [110], Banzhaft et.al. 1998 [], and Eiben et.al. 2003 [81] not explicitly deal with convergence can we found explicit discussions in Ankenbrandt 1991 [6], Rylander et.al 2001 [267], Langdon and Poli 2002 [187], and Fogel 2006 [93].
Ankenbrandt presents the convergence problem in an algorithmic format as follows (cf. [6]:54):
Where convergence is identified as the absence of change between consecutive populations G(t), G(t+1)(cf. [6]:55).3.6
He proves then three different cases of convergence times ![]() :
:
The ![]() describes the convergence time for the worst case of GAs
- binary and non binary strings - while the
describes the convergence time for the worst case of GAs
- binary and non binary strings - while the
![]() and
and
![]() describe the average times for the binary and the
non-binary case.
describe the average times for the binary and the
non-binary case.
In these formulas ![]() denotes the value of the population
denotes the value of the population ![]() at
time
at
time ![]() while
while ![]() denotes the value of the population
denotes the value of the population ![]() at
time
at
time ![]() with
with ![]() as the 'final' time at convergence.
as the 'final' time at convergence.
The ![]() denotes the fitness ratio:
denotes the fitness ratio:
| (3.42) |
with ![]() as the fitness of all individuals with allele
value '1' at a position 'j' in the string. Analogously for
as the fitness of all individuals with allele
value '1' at a position 'j' in the string. Analogously for ![]() with
value '0'. Ankenbrandt assumes
with
value '0'. Ankenbrandt assumes ![]() to be constant. This is motivated
by the results, that the minimum fitness ratio was the best predictor
in GA performance since the GA is not converged until it is converged
along all allele positions.(cf. [6]:55).
to be constant. This is motivated
by the results, that the minimum fitness ratio was the best predictor
in GA performance since the GA is not converged until it is converged
along all allele positions.(cf. [6]:55).
This definition of fitness ratio is to be distinguished from the fitness ratio definition as part of the schema theory where the fitness is computed with regard to a certain schema (see below).
The complete function to compute the worst case convergence time has been realized in scilab as follows:
//*************************************************************
// Computing the worst case convergence time tcw
//
// p := number of parameters between strings left and right (actually p=5)
// l := length of strings ( actually l=5)
// n := number of elements in POP (actually n=4)
// POP := a predefined population (can be done automatically)
//
// f1 := fitness of all individuals with a allele value '1' at a position
// f0 := fitness of all individuals with a allele value '0' at a position
// r = f1/f0
// tcw := worst case convergence time
//
// Assumption: POP has the relativ fitness available at l+3
function[POP,tcw,tcabin,ratio,f1,f0]=ftcw(POP,l,p,n,show)
for i=1:n, v=POP(i,:),
d= vec2dec(v,l), //decimal value
[POP(i,l+1)]= d, //decimal value
end
for i=1:n,[POP(i,l+2)]= fitness1(POP(i,l+1))
end
[FITNESS_ALL]=fitness(POP,l)
[MFITNESS]=maxfitness(POP,l)
[POP,AFITNESS]=rfitness(POP,l,FITNESS_ALL)
[POP,ratio,f1,f0]=fratio10(POP,l,show)
tcw = log((n-1)^2)/log(ratio)
tcabin = log(n-1)/log(ratio)
endfunction