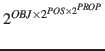Next: Grundlegende Wissensstrukturen Up: Das Große Ganze Previous: Chemische und Biologische Evolution Contents
Für diese Vorlesung werden wir den Ausgangspunkt der Theoriebildung mit der Verfügbarkeit der biologischen Zelle beginnen, und ausgehend von dieser nach und nach immer komplexere Strukturen und Mechanismen betrachten, die dann jenen Verhaltensweisen führen, die am Ende der Einleitung exemplarisch aufgelistet worden sind. Die vielen noch offenen und ungelösten Fragen, die im Rahmen der chemischen Evolution zur Bildung der hoch komplexen Zellen geführt haben, überlassen wir den einschlägigen Disziplinen, allen vorweg der Physik unterstützt von Chemie, Biochemie, Molekularbiolog ie und anderen.
In allem sind es vor allem die folgenden drei Strukturen, die sich wie ein roter Faden durch alle nachfolgenden Detailüberlegungen durchziehen werden: (i) die Struktur des Herstellungsprozesses ('Engineering Process'), innerhalb dessen Ingenieure Probleme in Lösungen überführen, (ii) die evolutionäre Strukturen, die in die technischen Lösungen einfließen können, sowie (iii) die Struktur der Welt, die wir als Standardumgebung für Populationen von lernende intelligente Systeme annehmen.
Engineering Prozess als Rahmen
In dem Masse, wie Erkenntnisse über die Welt in neue Lösungen überführt werden sollen, die als konkrete (technische) Systeme wirksam werden sollen, muss ein Herstellungsprozess organisiert werden, der nach nachvollziehbaren Methoden eine Aufgabenstellung in eine Lösung übersetzt. Dazu haben sich unter dem internationalen Titel 'Systems Engineering' eine Reihe von Methoden und Vorgehensweisen etabliert, die im Folgenden vorausgesetzt werden (siehe für eine weitergehende Beschreibung z.B. Doeben-Henisch [93], Erasmus und Doeben-Henisch [], [113]).
Minimal benötigt man einen Auftraggeber ('stakeholder') ![]() - im Grenzfall man selbst -, der ein Problem
- im Grenzfall man selbst -, der ein Problem ![]() kommuniziert, das gelöst werden soll. In einer ersten Analyse werden alle Anforderungen ('requirements')
kommuniziert, das gelöst werden soll. In einer ersten Analyse werden alle Anforderungen ('requirements') ![]() ermittelt,
die sich aus dem Problem nach aktuellem Wissensstand ergeben. Dies umfasst eine Präzisierung der Aufgaben ('tasks') die
im einzelnen gelöst werden sollen, eine Klärung der Benutzergruppe ('user'), die die Akteure sein sollen sowie eine
Klärung der Systemschnittstelle, auf welche Weise das intendierte technische System den intendierten Akteuren 'helfen'
soll, die Ausführung der Aufgaben zu erleichtern (Alle Komponenten zusammen kann man im Verhaltensmodell
ermittelt,
die sich aus dem Problem nach aktuellem Wissensstand ergeben. Dies umfasst eine Präzisierung der Aufgaben ('tasks') die
im einzelnen gelöst werden sollen, eine Klärung der Benutzergruppe ('user'), die die Akteure sein sollen sowie eine
Klärung der Systemschnittstelle, auf welche Weise das intendierte technische System den intendierten Akteuren 'helfen'
soll, die Ausführung der Aufgaben zu erleichtern (Alle Komponenten zusammen kann man im Verhaltensmodell ![]() zusammenfassen). Dies schließt erste Benutzbarkeitstests ('usability test') der geplanten Systemschnittstelle mit ein.
Ist diese Aufgabe hinreichend gelöst, dann muss man ein logisches Konzept (Designmodell, Lösungsmodell, Entwurf)
zusammenfassen). Dies schließt erste Benutzbarkeitstests ('usability test') der geplanten Systemschnittstelle mit ein.
Ist diese Aufgabe hinreichend gelöst, dann muss man ein logisches Konzept (Designmodell, Lösungsmodell, Entwurf) ![]() für eine mögliche Lösung konzipieren, das mindestens die Anforderungen an die
Systemschnittstelle erfüllen kann. Das logische Konzept muss dann implementiert werden als ein implementiertes Modell
für eine mögliche Lösung konzipieren, das mindestens die Anforderungen an die
Systemschnittstelle erfüllen kann. Das logische Konzept muss dann implementiert werden als ein implementiertes Modell
![]() . Das implementierte Modell muss dann einer Evaluation ('validation') unterzogen werden, die als Norm (
Benchmark) das Verhaltensmodell benutzt.
. Das implementierte Modell muss dann einer Evaluation ('validation') unterzogen werden, die als Norm (
Benchmark) das Verhaltensmodell benutzt.
Theoretisches Modell
Im Rahmen eines Herstellungsprozesses dienen die ersten beiden Phasen ![]() und
und ![]() der Klärung der Aufgabenstellu
ng in Form von Anforderungen und einem Verhaltensmodell. In der dritten Phase soll ein theoretisches Modell einer
möglichen Lösung
der Klärung der Aufgabenstellu
ng in Form von Anforderungen und einem Verhaltensmodell. In der dritten Phase soll ein theoretisches Modell einer
möglichen Lösung ![]() formuliert werden. Wie das Schaubild 2.4 zeigt, besteht der Kern
einer Theorie darin, empirische Daten, die im Rahmen einer definierten Fragestellung gemessen worden sind, bezüglich
möglicher allgemeiner Beziehungen in Form einer formalen Theorie so hin zuschreiben, dass es möglich ist, Schlussfolgeru
ngen aus dieser Theorie über mögliche Zustände der empirischen Welt durch weitere Experimente zu überprüfen. In diesem
Kontext benutzt man heute auch verstärkt Simulationen, um das mögliche Verhalten eines Systems im Sinne der Theorie
durch einen Computer 'ausrechnen' zu lassen, da eine Bleistift-Papier-Berechnung rein zeitlich nicht mehr ausreichen
würde. Erste Überblicke zum formalen Theoriebegriff mit Semantik findet man in der Enzyklopädie Wissenschaftstheorie (
1995) [294], hier besonders im Eintrag 'Wissenschaftstheorie', sowie für einen historischen
Überblick zum Statement-View Suppe (1979)[415], und mit praktischen Beispielen zum Non-Statement View
Balzer (1982) [16])(Als wichtigster Initiator des Non-Statement Views gilt Sneed (1979)[388]).
formuliert werden. Wie das Schaubild 2.4 zeigt, besteht der Kern
einer Theorie darin, empirische Daten, die im Rahmen einer definierten Fragestellung gemessen worden sind, bezüglich
möglicher allgemeiner Beziehungen in Form einer formalen Theorie so hin zuschreiben, dass es möglich ist, Schlussfolgeru
ngen aus dieser Theorie über mögliche Zustände der empirischen Welt durch weitere Experimente zu überprüfen. In diesem
Kontext benutzt man heute auch verstärkt Simulationen, um das mögliche Verhalten eines Systems im Sinne der Theorie
durch einen Computer 'ausrechnen' zu lassen, da eine Bleistift-Papier-Berechnung rein zeitlich nicht mehr ausreichen
würde. Erste Überblicke zum formalen Theoriebegriff mit Semantik findet man in der Enzyklopädie Wissenschaftstheorie (
1995) [294], hier besonders im Eintrag 'Wissenschaftstheorie', sowie für einen historischen
Überblick zum Statement-View Suppe (1979)[415], und mit praktischen Beispielen zum Non-Statement View
Balzer (1982) [16])(Als wichtigster Initiator des Non-Statement Views gilt Sneed (1979)[388]).
Ein vollständiges logisches Modell ist also eine empirisch interpretierte formale Theorie, die in ein implementiertes Modell zu übersetzen ist.
Bei der Konzipierung der Systeme kann man den Lösungsansatz unterschiedlich tief wählen: (i) Wenn es um die möglichst direkte Unterstützung bei wohl bekannten Aufgaben geht, dann kann man einen Phänotyp konzipieren, der direkt für die Lösung einer Aufgabe ausgelegt ist, ohne Lernen. (ii) Ist das Lösungsverhalten von vornherein nicht vollständig bekannt, dann muss der Phänotyp zusätzlich über eine 'Lernmöglichkeit' verfügen. Dies impliziert ein geeignetes Präferenzsystem ('besser', 'schlechter'), ohne das kein Lernen möglich ist. Die Verfügbarkeit eines solchen Präferenzsystems und seine genaue Ausgestaltung ist nicht trivial. Im Falle der biologischen Evolution gibt es einen zentralen Wert, und der heißt 'Überleben'; alles, was dazu beiträgt ist 'gut'. Ausgehend von diesem Wert haben sich weitere 'Werte' als 'abgeleitete' Werte ergeben. Z.B. hat sich gezeigt, dass die Verfügbarkeit von Sprache die Überlebensfähigkeit einer Population deutlich steigert. Das gleiche gilt für verschiedene Kulturtechniken. (iii) Da die Vorgabe eines bestimmten Phänotyps das Spektrum möglicher Lösungen von vornherein einschränkt, kann man das Lernverhalten auch auf die Struktur des Phänotypen selbst ausdehnen indem man Phänotypen auf Basis von Genotypen bilden lässt. Dieses Mehr an 'Lösungsraum' benötigt aber auch mehr 'Zeit' und mehr Ressourcen. Zusätzlich ist es riskanter, da die Zeit vom Problem zur Lösung erheblich anwachsen kann.
Vor diesem Hintergrund ist es kein Zufall, dass die Variante (i) die heutige Technik nahezu vollständig dominiert. Variante (ii) gewinnt mit der zunehmenden Rechenleistung an praktischer Bedeutung. Variante (iii) dient eigentlich nur theoretischen Interessen.
Die zentrale Rolle des Präferenzsystems macht deutlich, dass die technischen Lösungen letztlich aber nur 'Sinn' machen können, wenn die Frage der Präferenzen, sprich der 'Werte' geklärt ist. Ohne eine klare Vorstellung von dem zu haben, was 'Gut' bzw. 'Nicht Gut' ist, ist nicht klar, in welche Richtung wir unsere Lösungskapazitäten ausrichten wollen. Das Verfolgen von 'abgeleiteten' Zielen, die möglicherweise dem Ganzen nicht nur nicht helfen, sondern 'schaden', kann daher für eine Population auf lange Sicht 'tödlich' sein. So zeigt sich die 'Wertefrage' als die zentrale Frage der biologischen Evolution, die über das reine Überleben insofern hinaus weist, als es um die Frage geht, WIE das Überleben gestaltet werden soll. So, wie sich die Sprache als ein neues Moment im evolutionären Prozess gezeigt hat, die indirekt sowohl das Überleben als solches wie auch die Art und Weise des Überlebens entscheidend geprägt hat, so kann es (und gibt es) viele andere Prozesseigenschaften, die von großer Bedeutung sein können; letztlich aber auch nur, insoweit sie sich nicht 'verselbständigen', sondern sie einer jeweiligen Mehrheit helfen, den Lebensprozess 'besser' gestalten zu können.
Simulation
Wie im Zusammenhang der Theoriebildung (vgl. Bild 2.4) und im Zusammenhang des Herstellungspro
zesses (vgl. Bild 2.3) deutlich wird, spielt für die Überprüfung einer Theorie die computergestüt
zte Simulation heute eine immer größere Rolle. Im Rahmen dieser Vorlesung wird davon auch intensiver Gebrauch gemacht.
Im Kern beinhalten diese Simulationen die Elemente, die auch im Bild 2.3 anklingen: eine Welt
![]() (
(![]() ) mit Aufgaben
) mit Aufgaben ![]() , verschiedene Akteure als lernende Systeme
, verschiedene Akteure als lernende Systeme ![]() , sowie eine Schnittstelle, über die
die Interaktion zwischen Akteuren und der Welt abgewickelt werden. Vermittelt durch die Welt können die Akteure auch
miteinander interagieren. Die gesamte Simulation muss so ausgelegt sein, dass sich alle Aktivitäten 'messen' lassen.
, sowie eine Schnittstelle, über die
die Interaktion zwischen Akteuren und der Welt abgewickelt werden. Vermittelt durch die Welt können die Akteure auch
miteinander interagieren. Die gesamte Simulation muss so ausgelegt sein, dass sich alle Aktivitäten 'messen' lassen.
Evolutionäre Perspektive
Ein Zusammenhang zwischen dem Engineering Prozess und der biologischen Evolution besteht mindestens zweifach: (i)
einmal ist die heute lebende Gesellschaft der Menschen Teil der biologischen Evolution und unterliegt weiterhin ihren
Gesetzen, zum anderen (ii) können die Ingenieure während des Engineeringprozesses beim Erarbeiten des logischen
Lösungsmodells ![]() Erkenntnisse aus der biologischen Evolution in ihre Lösung einbauen. Als Eckwerte zur
biologischen Evolution sei das Folgende festgehalten:
Erkenntnisse aus der biologischen Evolution in ihre Lösung einbauen. Als Eckwerte zur
biologischen Evolution sei das Folgende festgehalten:
Wir gehen davon aus, dass wir es in der empirischen Welt mit einem Geschehen in der Zeit zu tun haben, die unter
anderem die Erde hervorgebracht hat, die für uns zur Zeit die Standardumgebung ist. Biologische Lebewesen haben sich
auf der Erde auf der Basis der biologischen Zelle entwickelt. Dies beinhaltet ab einem bestimmten Zeitpunkt die
Fähigkeit, dass ein Genotyp ![]() als Teil einer Population
als Teil einer Population ![]() innerhalb eines Wachstumsprozesses
innerhalb eines Wachstumsprozesses ![]() unter
Ausnutzung gewisser Kontexte
unter
Ausnutzung gewisser Kontexte ![]() in einen Phänotyp
in einen Phänotyp ![]() verwandeln kann (
verwandeln kann (
![]() ). Der Phänotyp
kann mit der umgebenden Erde
). Der Phänotyp
kann mit der umgebenden Erde ![]() über Input- und Outputprozesse interagieren. Dabei kann sowohl die Umgebung
über Input- und Outputprozesse interagieren. Dabei kann sowohl die Umgebung ![]() geändert werden wie auch der Phänotyp. Sofern der Phänotyp während seiner Lebenszeit durch Weitergabe des Genotyps
genügend Nachkommen
geändert werden wie auch der Phänotyp. Sofern der Phänotyp während seiner Lebenszeit durch Weitergabe des Genotyps
genügend Nachkommen
![]() erzeugen kann, bleibt die Population
erzeugen kann, bleibt die Population ![]() erhalten oder wächst sogar. Sobald
die Population gegen Null geht, verschwindet diese Lebensform von der Erde.
erhalten oder wächst sogar. Sobald
die Population gegen Null geht, verschwindet diese Lebensform von der Erde.
Ein solcher evolutionärer Prozess setzt die Beschreibbarkeit (Kodierbarkeit) jedes Phänotyps ![]() durch einen Genotyp
durch einen Genotyp
![]() samt Wachstumsoperator
samt Wachstumsoperator ![]() voraus. Der Wachstumsoperator
voraus. Der Wachstumsoperator ![]() wiederum impliziert ein 'Trägersystem'
wiederum impliziert ein 'Trägersystem' ![]() ,
das mindestens die Elemente 'Kontexte'
,
das mindestens die Elemente 'Kontexte' ![]() , Genotyp
, Genotyp ![]() , sowie Wachstumsoperator
, sowie Wachstumsoperator ![]() umfasst, also
umfasst, also
Dabei ist zu beachten, dass der Wachstumsoperator ![]() kein aufzeigbarer Gegenstand ist; er zeigt sich nur in
seinen 'Wirkungen', d.h. wenn es Genotypen
kein aufzeigbarer Gegenstand ist; er zeigt sich nur in
seinen 'Wirkungen', d.h. wenn es Genotypen ![]() gibt, aus denen unter bestimmten Randbedingungen
gibt, aus denen unter bestimmten Randbedingungen ![]() Phänotypen
Phänotypen ![]() hervorgehen, dann repräsentiert der Übergang von
hervorgehen, dann repräsentiert der Übergang von ![]() bei
bei ![]() nach
nach ![]() den Operator
den Operator ![]() . In der empirischen Welt
ist ein Operator immer ein 'theoretisches Konstrukt', eine 'Arbeitshypothese' entsprechend den 'Verben' einer Sprache footnoteIn einer Sprache repräsentieren Verben 'Veränderungen' mit Anfangs und Endzustand, eventuell mit Zwischenzustän
den, ergänzt durch Kontextbedingungen, ohne dass diese Veränderungsaktion 'selbst' ein 'Gegenstand', ein 'Objekt' ist.
Das Verb wird zu einem 'Repräsentanten' für alle die Elemente, die bei einer Veränderung auftreten und als 'relevant'
betrachtet werden.
. In der empirischen Welt
ist ein Operator immer ein 'theoretisches Konstrukt', eine 'Arbeitshypothese' entsprechend den 'Verben' einer Sprache footnoteIn einer Sprache repräsentieren Verben 'Veränderungen' mit Anfangs und Endzustand, eventuell mit Zwischenzustän
den, ergänzt durch Kontextbedingungen, ohne dass diese Veränderungsaktion 'selbst' ein 'Gegenstand', ein 'Objekt' ist.
Das Verb wird zu einem 'Repräsentanten' für alle die Elemente, die bei einer Veränderung auftreten und als 'relevant'
betrachtet werden.
Logische Struktur der Welt
Im Rahmen der oben genannten Voraussetzungen zeigen sich damit als zentrale Begriffe die (potentiell lernende) Akteure
![]() und die diese umgebende Welt
und die diese umgebende Welt ![]() als zentrale Größen, die über Interaktionen
als zentrale Größen, die über Interaktionen ![]() miteinander verknüpft sind. Es
stellt sich damit die Frage, welches die Minimalanforderungen sind, die man an diese Größen zu stellen hat, damit sie
in einer Formalisierung alle jene Eigenschaften bieten, die man für theoretische Zwecke benötigt.
miteinander verknüpft sind. Es
stellt sich damit die Frage, welches die Minimalanforderungen sind, die man an diese Größen zu stellen hat, damit sie
in einer Formalisierung alle jene Eigenschaften bieten, die man für theoretische Zwecke benötigt.
Dabei stellt sich folgendes generelles Problem![]() : die grundsätzlichen Dimensionen des Denkens sind - je nach Kontext - verschieden.
Im Bild 2.8 findet sich eine grobe Skizze, die auf den Erfahrungen des Autors beruht. Streng
genommen wäre dies ein eigenes Forschungsfeld, das vermutlich irgendwo in der Philosophie in Kooperation mit der
Psychologie anzusiedeln wäre.
: die grundsätzlichen Dimensionen des Denkens sind - je nach Kontext - verschieden.
Im Bild 2.8 findet sich eine grobe Skizze, die auf den Erfahrungen des Autors beruht. Streng
genommen wäre dies ein eigenes Forschungsfeld, das vermutlich irgendwo in der Philosophie in Kooperation mit der
Psychologie anzusiedeln wäre.
Im Bereich der Physik als der Fundamentaldisziplin der empirischen Welt wird zwar eine Raum-Zeit angenommen, innerhalb deren es diverse Messpunkte geben kann (die man als elementare Eigenschaften (DIM:VAL) deuten kann), aber es gibt hier keine Objekte. Diese können nur in einer nachfolgenden theoretischen Rekonstruktion entstehen.
Im phänomenologischen Raum des Alltagsdenkens ist es dagegen so, dass das Gehirn die einzelnen sensorischen Daten 'automatisch' zu 'Objekten mit Eigenschaften' 'vor verarbeitet'; mit dem Gehirn sehen wir immer schon Objekte. Dies ist einerseits von großem alltagspraktischen Nutzen, kann aber zu 'Ontologisierungen' führen, die falsch sind. Außerdem nehmen wir Veränderungen in Form von aufeinander folgenden Zuständen war. Diese Veränderungen können bis zu einem gewissen Grad 'kontinuierlich' erscheinen, sind aber alle (wie wir aus psychologischen Experimenten wissen) ' diskret' (kontinuierliche Zeit existiert eigentlich nur in speziellen Kalkülen der Mathematik). Veränderungsereignisse können wir mittels sprachlicher Ausdrücke (Verben, Operatoren) zu einem 'Veränderungsgeschehen' zusammenfassen, indem wir Ausgangspunkt und Endpunkt benennen.
In der Informatik ist die Lage nicht ganz so eindeutig. Die Informatik existiert in einem Kontinuum zwischen zwei Polen: Einerseits die reine Logik und Mathematik berechenbarer Prozesse, andererseits die konkreten Maschinen des Rechnens. Beide Pole vermittelt über das alltägliche denken. Für unseren Kontext relevant ist die Informatik als eine Möglichkeit, Prozesse auf einem Computer zu simulieren. Dazu muss man das zu simulierende Problem (ein theoretisches Modell) mit Hilfe einer Programmiersprache lauffähig machen. In diesem Sinne ist die Programmiersprache die kognitive Schnittstelle zwischen dem theoretischen Modell und der rechnenden Maschine. Im Jahr 2013 wird die Programmierung - bei mehr als 50 verschiedenen Programmiersprachen - einerseits stark geprägt von einem Modellbasierten Vorgehen, andererseits gibt es immer noch eine Mehrheit, die immer noch 'direkt' programmieren. Hier eine eindeutige konzeptuelle Einordnung zu treffen ist schwierig. Ein verbreitetes Paradigma - wenngleich auch nur eines, das nicht alles Programmieren dominiert -, ist das sogenannte objektorientierte Programmieren. Hier werden Programmiersprachen benutzt, die ein objektorientiertes Denken unterstützen. Im objektorientierten programmieren geht man davon aus, dass man 'Objekte' hat, die rudimentäre Eigenschaften besitzen können, die Methoden haben, die diese Eigenschaften 'lokal' verändern können, und die mittels Methoden 'global' miteinander interagieren können. Es gibt kein explizites Zeitmodell (wenngleich diskrete Änderungen angenommen werden), und es gibt ein explizites Raummodell. Ein Raum wird notfalls als eine 'innere Datenstruktur' geschaffen, innerhalb der man dann operieren kann, aber es gibt keinen Raum, innerhalb dessen die Objekte vorkommen.
Schon diese knappe Skizze mag genügend, um zu ahnen, dass ein Denken in einem dieser konzeptuellen Paradigmen nicht so ohne weiteres übersetzbar ist, in das andere Paradigma. Dennoch gibt es mindestens diese drei Denkformen im Alltag nebeneinander.
Zusätzlich gibt es das Problem der benutzten Sprache. Sowohl die Physik wie die phänomenologische Philosophie benutzen
Mathematik, sprich eine mengentheoretische Sprache. Abgesehen davon, dass es verschiedene (!) mengentheoretische
Sprachen gibt, impliziert eine mengentheoretische Sprache auch eine gewisse 'Semantik', sprich ein bestimmtes
konzeptuelles Paradigma. Mir ist keine explizite Untersuchung bekannt, ob und inwieweit die mengentheoretische Sprache
das, was ein Physiker oder ein Philosoph als 'Gegenstand' beschreiben wollen, durch die Eigenheiten der verwendeten
Sprache 'behindert' wird.![]()
Im Folgenden setze ich ein konzeptuelles Paradigma voraus, was primär an der phänomenologischen Psychologie und am Alltagsdenken orientiert ist und benutze zur Darstellung eine mengentheoretische Sprache, die mehr dem Konzept von von Neumann-Bernays-Gödel (NBG)[302] folgt als dem von Zermelo-Fraenkel (ZFC)[483]. Doch kann ich dies an dieser Stelle nur so allgemein sagen. Dies wäre weiter zu präzisieren.
![\includegraphics[scale=.85]{EngineeringProcess2.eps}](img59.png)
![\includegraphics[scale=.85]{Theories_FormalModels_4.5in.eps}](img66.png)
![\includegraphics[scale=.85]{Philosophical_Framework_of_All_Theories.eps}](img68.png)
![\includegraphics[scale=.85]{Simulation2.eps}](img69.png)
![\includegraphics[scale=.85]{EvolutionaryContext.eps}](img74.png)
![\includegraphics[scale=.85]{ConceptualSpaces.eps}](img88.png)