Schätz-Sprachspiel Stufe 1
Figure 4.5:
Minimale cognitive Struktur eines LSS
![\includegraphics[scale=.85]{Zeichenlernen-Interne-Prozesse.eps}](img399.png) |
Unter Voraussetzung der bisherigen Überlegungen soll hier ein erster Entwurf vorgestellt werden, wie ein
Schätz-Sprachspiel ('guessing game') aussehen könnte, durch das eine Population von lernenden Zeichenbenutzern
(lernende semiotische Systeme, LSS) eine beliebige Menge von Namen für eine beliebige Menge von Außenwelt-Objekten
lernen kann. Für die Formulierung des Sprachspiels wird eine spezifische kognitive Struktur vorausgesetzt, wie sie im
Bild 4.5 dargestellt wird. Diese kognitive Struktur ist ganz allgemein für abstrakte Lerner
konzipiert. In einem zweiten Schritt könnte es interessant sein, diese Struktur auf realen Laborrobotern zu
implementieren.
Folgende Annahmen werden gemacht:
- Der Lerner hat mindestens zwei Ziele: seinen Energiehaushalt zu managen und Zeichen zu lernen. Für das Ziel
Energiehaushalt managen greifen wir auf die Arbeiten zurück, wie sie im Kontext von Tolman's
Rattenexperimenten 1948 durchgeführt wurden (siehe
http://www.uffmm.org/EoIESS-TH/gclt/node54.html).
- Für das Ziel Zeichenlernen nehmen wir die minimale kognitive Struktur an, die im vorausgehenden Bild
skizziert ist.
- Es wird angenommen, dass der Systeminput
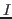 besteht aus 'Klängen' ('sounds') und 'Visuellen Mustern'
('visuals') im sensorischen Speicher
besteht aus 'Klängen' ('sounds') und 'Visuellen Mustern'
('visuals') im sensorischen Speicher 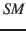 und internen(propriozeptiven) Wahrnehmungen ('internals'),
die Emotionen
und internen(propriozeptiven) Wahrnehmungen ('internals'),
die Emotionen  im weitesten Sinne repräsentieren
im weitesten Sinne repräsentieren![[*]](/usr/share/latex2html/icons/footnote.png) .
.
- Die zyklisch verfügbaren Werte im sensorischen Speicher (inklusive den 'Emotionen') werden im Rahmen eines
Wahrnehmungsprozesses
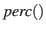 'extrahiert', in 'unterscheidbare Elemente' zerlegt, nach bestimmten Mustern
(z.B. 'räumlich') 'angeordnet', und - gegebenenfalls - aufgrund vorliegender Aufmerksamkeitstrigger
besonders 'ausgezeichnet'.
'extrahiert', in 'unterscheidbare Elemente' zerlegt, nach bestimmten Mustern
(z.B. 'räumlich') 'angeordnet', und - gegebenenfalls - aufgrund vorliegender Aufmerksamkeitstrigger
besonders 'ausgezeichnet'.
- Die so aufbereiteten Elemente stehen dann modalspezifisch im Kurzzeitgedächtnis
 zur Verfügung,
d.h. Laute sind von visuellen Mustern unterschieden, dazu evtl. emotionale Elemente. Aufgrund der Anordnung und
möglichen Aufmerksamkeitselementen stehen die Elemente des Kurzzeitgedächtnis potentiell in diversen Beziehungen.
zur Verfügung,
d.h. Laute sind von visuellen Mustern unterschieden, dazu evtl. emotionale Elemente. Aufgrund der Anordnung und
möglichen Aufmerksamkeitselementen stehen die Elemente des Kurzzeitgedächtnis potentiell in diversen Beziehungen.
- Unterschieden vom Kurzzeitgedächtnis gibt es das Langzeitgedächtnis
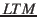 , das in sich noch
deutlich weiter spezifiziert werden kann.
, das in sich noch
deutlich weiter spezifiziert werden kann.
- Hier wird nur angenommen, dass zu jedem Element des Kurzzeitgedächtnisses eine entsprechende Kategorie
 generiert werden kann, die als 'Repräsentant' vieler konkreter Elemente dienen kann. Mindestens werden
unterschiedliche Kategorien für Klangobjekte
generiert werden kann, die als 'Repräsentant' vieler konkreter Elemente dienen kann. Mindestens werden
unterschiedliche Kategorien für Klangobjekte  , für visuelle Objekte
, für visuelle Objekte  und für emotionale
Objekte
und für emotionale
Objekte  angenommen.
angenommen.
- Zwischen diesen Kategorien können dann vielerlei Kategorien-Beziehungen gebildet werden. Z.B.
räumliche Beziehungen, Veränderungs-Beziehungen, oder auch Zeichen-Beziehungen.
- Der Übergang von Elementen des Kurzzeitgedächtnisses zu Kategorien wird durch die Funktion
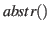 geleistet.
geleistet.
- Die Bekanntgabe der Zugehörigkeit eines Elementes im Kurzzeitgedächtnis zu einer Kategorie wird durch die
Funktion
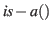 geleistet.
geleistet.
- Liegt ein Objektelement vor, dann liefert die Funktion
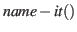 den dazugehörigen sprachlichen Ausdruck,
sofern er schon gelernt worden ist.
den dazugehörigen sprachlichen Ausdruck,
sofern er schon gelernt worden ist.
- Umgekehrt, liegt ein sprachlicher Ausdruck vor, dann liefert die Funktion
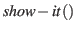 das dazugehörige Objekt,
sofern er schon gelernt worden ist.
das dazugehörige Objekt,
sofern er schon gelernt worden ist.
Mit diesen Voraussetzungen ergibt sich folgender erster Ansatz für ein - gegenüber Vogt [442] -
modifiziertes Schätzspiel in Stufe 1:
- Ein Lerner hört ein Lautereignis
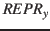 ohne selbst auf ein Objekt zu zeigen. Dazu bildet er eine
Laut-Kategorie
ohne selbst auf ein Objekt zu zeigen. Dazu bildet er eine
Laut-Kategorie  .
.
- Ein Lerner nimmt ein Objekt
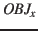 wahr und bildet dazu eine Objekt-Kategorie
wahr und bildet dazu eine Objekt-Kategorie  .
.
- Ein Lerner zeigt auf ein Objekt , zu dem es schon eine Objekt-Kategorie gibt, und hört ein
Lautereignis . Falls es noch keine passende Laut-Kategorie gibt, bildet er eine Laut-Kategorie
neu. Sowohl im Fall, dass es schon eine Laut-Kategorie gab bzw. im Fall, dass eine neu gebildet wurde, fügt
der Lerner ein Kontextmerkmal
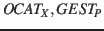 zur Laut-Kategorie hinzu.
zur Laut-Kategorie hinzu.
- Ein Lerner hat eine Objekt-Kategorie und eine Laut-Kategorie und besitzt dazu einen
Kontextmerkmal
, d.h. zum Objekt der Kategorie gab es eine Zeigeaktion, die ein Lautereignis der
Kategorie nach sich zog. Deswegen bildet er eine Zeichenbeziehung zwischen und
.
- Ein Lerner sieht ein Objekt und äußert dazu mit einen gelernten Ausdruck.
- Ein Lerner hört einen Ausdruck und zeigt dazu mit auf ein passendes Objekt in seiner Umgebung, falls
vorhanden.
Hinweis: Diese Annahmen implizieren, dass ein Lerner über folgende Aktionsmöglichkeiten verfügt:
- Bewegungen {0,1, ..., 8}
- Essen
- Zeigen (mit Richtung)
- Laute äußern
Zugleich muss man festlegen, wie sich diese verschiedenen Aktionen einem anderen Lerner (als Beobachter) darstellen.
Gerd Doeben-Henisch
2014-01-14