
|
|
I-ALGO SS03 - ALGORITHMS AND DATASTRUCTURES - Lecture with Exercices
|
In this lecture we want to present first ideas how to generate estimates related to resources an algorithm will need if it will be applied to a problem.
What we usually know are programs running on a computer, whereby 'computer' means in this context a real machine, built from hard materials, occupying some location in space. A programm is some text which has been converted in states of the machine ('bits', somewhere located in the hardware) (for first ideas about hardware see e.g. Rechnerarchitektur).
But in this lecture we are looking to algorithms and automata. From a theoretical point of view (here: theoretical computer science), are programs the realizations of algorithms, or, with other words, algorithms represent the theoretical concept of some computable process. An algorithm is a finite text consisting of commands dedicated for a certain automaton who for every command c 'knows' with which command c' it has to continue. The today best known Prototype of a computing automaton is the Turing Machine; all other know computing automata are either formally equivalent to a turing machine or are weaker subcases of it (for first ideas about algorithms and automata see e.g. Theoretische Informatik).
Therefore, we are looking in this lecture not to 'real' machines with 'real' programs but to 'abstract' automata and algorithms, which can work on such automata.
In the following diagram we show an idealized representation of a general automaton which is equivalent to a turing machine.
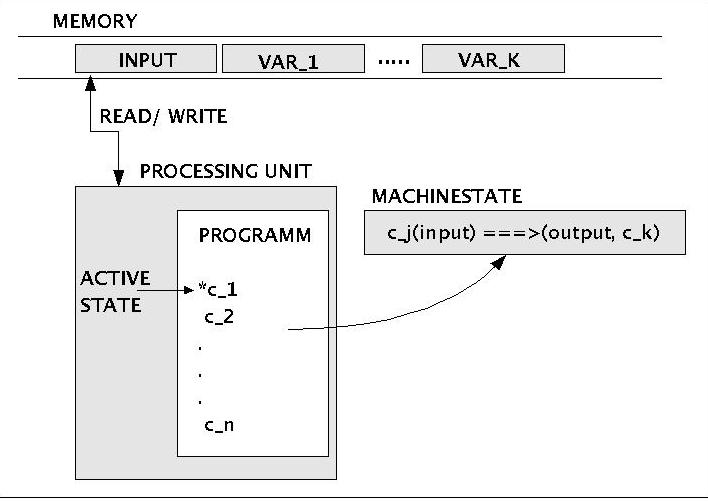
Automaton
The automaton consists of the following parts:
MEMORY: The memory contains the input for the program of the automaton as well as a finite set of variables. A variable is an indexed part of the memory which can contain a value.
PROCESSING UNIT: The processing unit contains the program and is able to read and write the memory based on indices. At every moment it is clear for the processing unit which part of the memory is actually indexed.
MACHINE STATE: A program of the automaton consists of finitely many machine states. Every machine state has the same structure: an index identifying the state, an input field, an outputfiled (where to write what) and a succesor-state index.
From this structure it follows that the processing of an automaton can be represented as a protocol which is a list of items where each item contains the position-number in the list, the actual state of the memory at this point of processing as well as the machine-state which has been applied at this point. Because every machine-state is the most elementary operation of an automaton one can take one position in the protocol (that is: the processing of one machine state) as on time-unit.
An algorithm seen in this context is the program which is 'guiding' the behaviour of the automaton. There are many ways how to represent such programs formally. Well known are e.g. the so-called 'recursive functions', the 'lamba-calculus', 'Thue-Systems', 'Formal grammars' and much more (see again Theoretische Informatik) .
Although we are dealing with algorithms as abstract entities one should now be able to understand why it can make sense to speak about resources which an algorithm will need. The automaton has to store data, has to read data and has to perform actions which are realizing some functions. Stored data need space and the performing of operations needs time.
Because today we are mostly interested in theoretical computer science why we hope to get some support for practical solutions, we are interested in those questions related to algorithms and automata which can be related to our dayly work. And in the practical applications of algorithms it shows up that the resource space is much less important than the resource time. Thus most investigations into the needed resources for algorithms are focussing on the resource time: how much time will an algorithm need. Thus will this question regarding the needed time be the topic of today and the next lectures.
There is another topic to be mentioned in connection with an algorithm: correctness. If we design an algorithm A to solve some problem P, then it is important to know, that the algorithm A really fullfils all the requirements which are defined by the problem P. To show that an algorithm A is correct it will not suffice to make some tests which are error-free; we need some more stronger method, we need a proof which demonstrates in general, that all defined cases are catched sufficiently by our algorithm A. Thus we have to transform the algorithm A in a symbolic representation which allows the application of a proof. One possible strategy is to represent algorithms as flowcharts (see below), then to transform the flowcharts in a polynom of partial time-functions, and then, finally, to convert this polynom of time-functions into a big-OH notation (see below).
If we are talking about algorithms we are especially interested in the structure of an algorithm, it's 'essential' components, to understand and algorithm as well as to be able to generate estimates about the resources an algorithm will need. And in this context it is a permanent discussion what is the 'best' way to represent the structure of an algorithm?
Mostly known forms of how to represent algorithms are the textual representations related to so-called 'programming languages' like C/C++, Fortran, Modula, Perl, Ada etc. What counts for these programming-language-representations is their nearness to a real application; if You have a representation e.g. in C then you can immediately compile it on a computer and run it.
There are other diagramatic-like forms of representations which are independent of a certain programming language and which can be helpful in some cases. These are the well known Flow Charts from Nassi and Shneiderman.
With a collection of 3-4 different flowcharts it is possible to describe any algorithm run on an automaton. We will use this notational device in this course to represent the structure of algorithms, especially in the context of computing the time an algorithm is expected to need.
The investigations in the resources needed by an algorithm will usually yield some numbers (see below), which are used to estimate the amount of resources needed. But because these algorithms are related to the behaviour of (abstract) automata one can not relate these numbers directly to any (empirical, real) computer. One and the same algorithm with --let us say e.g.-- 1000 theoretical time steps, can need on a real machine which is slow perhaps 2 micro-seconds and on a fast machine 0.00002 micro-seconds. Thus in using theoretical analysis of algorithms one has also to take into account the real world with its real computers whose performances until today are steadily improving.
If we are interested in a measurement of the resources which an algorithm needs we have to establish a mapping from input to the resource of interest:
comp: INPUT ---> RESOURCE
Because we will focus on pratical reasons on the resource time, we can say we are looking for a mapping of input into time:
time: INPUT ---> TIME
The exact analysis of the way how to establish an adequate resource-mapping function is not simple and is closely related to what is called in theoretical computer science complexity theory (see some remarks at: Komplexctätstheorie).
Here we will not go 'deeper' into th problem. We will only assume that we are able to discretize the input of the algorithm into distinguishable 'units' which can be counted. The amount of input units will always be a finite number n in the set of natural numbers Nat. Thus we can say:
time: Nat ---> TIME
Dealing with automata which are processing commands of algorithms we can stay also with natural numbers if we are counting the processing of one basic command as 1 abstract time unit. Compound commands are the a multiple of 1 time unit according to the number of basic commands involved. Thus we get:
time: Nat ---> Nat
Applying the theoretical results to real programs on real computers we will usually need real numbers to encode the time of a program run. That is we will have some mapping from natural time units to realnumbered time units:
time2time: Nat ---> Real
Examples of time-functions in order of increasing growth rate and tractability
|
FUNCTION |
NAME |
COMMENT |
TRACTABILITY (guessed) |
|
c |
Constant |
a single command |
probably yes |
|
log N |
Logarithmic |
|
|
|
log2 N |
Log-squared |
|
|
|
N |
Linear |
|
|
|
N log N |
N log N |
||
|
N2 |
Quadratic |
||
|
N3 |
Cubic |
|
|
|
2N |
Exponential |
probably not |
What is important in analyzing the time behavior of an algorithm is evidently its growth rate: which function f of a collection of possible functions is growing at the highest growth rate?
The other point is that in a polynomial expression like 5*N3+N2+1500*N+4000 that portion, which is contributed by the 'lower' terms (= N2+1500*N+4000) can mostly be neglected compared to the contribution of the highest term assuming values of N like 100, 10000 and bigger.
This is the rationale behind the idea to represent time-functions in the so-called Big-Oh notation O(f(n)). In the Big-Oh notation only the dominant term is represented. This means both functions:
f1(N) = 5*N3+N2+1500*N+4000
f2(N) = 5*N3
are represented as O(N3).
The exact definition of Big-Oh is given below:
(Big-Oh) T(N) is O(f(N)); T(N) is growing slower or equal (<) as a function f(N), which describes the behaviour of N. More precise, there is a positiv constant c and a N0 such that T(N) < c*f(N) when N > N0.
Example:
T(N) = 100N2 + 35N + 15
f(N) = N2
c = 102
|T(N)| < c * |f(N)|
therefore: T(N) is O(f(N))
(Big-Omega) T(N) is Omega(f(N)); T(N) is growing faster or equal (>) as a function f(N), which describes the behaviour of N. More precise, there is a positiv constant c and a N0 such that T(N) > c*f(N) when N > N0.
(Big-Theta) T(N) = Theta(f(N)); T(N) is growing equal (=) as a function f(N), which describes the behaviour of N. More precise, there is a positiv constant c and a N0 such that T(N) = c*f(N) mit N > N0.
(Little-oh) T(N) = o(f(N)); T(N) is growing slower (<) as a function f(N), which describes the behaviour of N. More precise, there is a positiv constant c and a N0 such that T(N) < c*f(N) mit N > N0.
Using the notation of logarithm it is important to know that the base B of a logarithm does
not matter in the case of the Big-O-Notation. It holds:
For any constant B > 1: logB N = O(log N)
(see prove in [WEISS 2001:212]). The definition used for logarithm is:
For any B,N > 0: logB N = K if BK = N.
In the context of Computer Science does the writing 'log N' imply that B=2.
When to use O(log N)-notation?
Intuitively 'clear' cases are those, where a certain problem X has repeatedly either to be doubled or to be halved.
If e.g. the amount X has to be doubled n-many times --X * 21 * ... * 2n = X * 2n-- then one could write X * log n.
Similar if the amount X has to be halved n-many times --X /( 21 * ... * 2n) = X /( 2n)-- then one could write X / log n.
Thus an algorithm is O(log N)if it takes constant ( O(1) ) time to cut the problem size by a constant fraction.
Following [GAREY/ JOHNSON 1979:8f] one can state as a 'rule of thumb' for for an estimate of the tractability of algorithms: if the argument of a big-oh notation O(f(n)) is a polynom with n the inputlength of the algorithm, then it can be assumed, that the algorithm is 'in principle' tractable, if the exponents are not larger than 2 or 3 and the coefficients are 'not too large'. If not a polynom, but an exponential function, than it is higly probable, that the algorithms is not tractable.
To illustrate the theoretical concepts a bit we will have a look to a concrete problem, which has been presented by J.L.Bentley 1984 in the communications of the ACM, vol.27:865-871.
The problem is entitled the Maximum Contigous Subsequence Sum Problem: Given a sequence of possibly negative integers n1,n2, ..., nk, find that contiguous subsequence with the maximum sum according to SUM(i=0; i=k) ni.
Example: input {-3,5,1} with 3 elements.
Possible subsequences and their sums are:
{-3} ==> -3
{-3,5} ==> 2
{-3,5,1} ==> 3
{5} ==> 5
{5,1} ==> 6
{1} ==> 1
Thus 'the winner' in this case would be: {5,1} ==> 6
Below you can see four different algorithms (from the public source of Allen Weiss); I have only rearranged the 'packaging' thus you can now use the algorithms separately and you can modify the input at your command.
//----------------------------
//
// msum-o-n3.cpp
//
// author: m.a.weiss
// modifications: g.doeben-henisch (march-12, 2003)
// Cubic maximum contiguous subsequence sum algorithm.
// Comparable: must have constructor from int, must have
// += and > defined, must have copy constructor
// and operator=, and must have all properties
// needed for vector.
// seqStart and seqEnd represent the actual best sequence.
//
//-------------------------------------------------------------
#include <stdlib.h>
#include <iostream>
#include <iomanip>
#include <vector>
using namespace std;
template <class Comparable>
Comparable maxSubsequenceSum1( const vector<Comparable> & a,
int & seqStart, int & seqEnd )
{
int n = a.size( );
Comparable maxSum = 0;
for( int i = 0; i < n; i++ )
for( int j = i; j < n; j++ )
{
Comparable thisSum = 0;
for( int k = i; k <= j; k++ )
thisSum += a[ k ];
if( thisSum > maxSum )
{
maxSum = thisSum;
seqStart = i;
seqEnd = j;
}
}
return maxSum;
}
// Test program.
int main( void )
{
unsigned int length;
vector<int> test; //Empty vector
int ss = -1, se = -1; // ss := SeqStart, se := SeqEnd
cout << "Number of elements for sequence = " ;
cin >> length;
test.resize(length); //Fitting vector to user input
cout << endl << "Thank you; we will start now collecting your input! " << endl ;
for( int i = 0; i < test.size( ); i++ ){
cout << "Any integer = " ;
cin >> test[i];
}
for( int i = 0; i < test.size( ); i++ )
cout << test[i] << " ";
cout << endl << maxSubsequenceSum1( test, ss, se ) << endl;
cout << " (at position " << ss << " to " << se << ")" << endl;
return 0;
}
gerd@goedel:~/WEB-MATERIAL/fh/I-ALGO/I-ALGO-EX/EX1> ./msum-o-n3 Number of elements for sequence = 3 Thank you; we will start now collecting your input! Any integer = -3 Any integer = 5 Any integer = 1 -3 5 1 6 (at position 1 to 2)
//----------------------------
//
// msum-o-n2.cpp
//
// author: m.a.weiss
// modifications: g.doeben-henisch (march-12, 2003)
//
// Quadratic maximum contiguous subsequence sum algorithm.
// Comparable: must have constructor from int, must have
// += and > defined, must have copy constructor
// and operator=, and must have all properties
// needed for vector.
// seqStart and seqEnd represent the actual best sequence.
//
//-------------------------------------------------------------
#include <stdlib.h>
#include <iostream>
#include <iomanip>
#include <vector>
using namespace std;
template <class Comparable>
Comparable maxSubsequenceSum2( const vector<Comparable> & a,
int & seqStart, int & seqEnd )
{
int n = a.size( );
Comparable maxSum = 0;
for( int i = 0; i < n; i++ )
{
Comparable thisSum = 0;
for( int j = i; j < n; j++ )
{
thisSum += a[ j ];
if( thisSum > maxSum )
{
maxSum = thisSum;
seqStart = i;
seqEnd = j;
}
}
}
return maxSum;
}
// Test program.
int main( void )
{
unsigned int length;
vector<int> test; //Empty vector
int ss = -1, se = -1; // ss := SeqStart, se := SeqEnd
cout << "Number of elements for sequence = " ;
cin >> length;
test.resize(length); //Fitting vector to user input
cout << endl << "Thank you; we will start now collecting your input! " << endl ;
for( int i = 0; i < test.size( ); i++ ){
cout << "Any integer = " ;
cin >> test[i];
}
for( int i = 0; i < test.size( ); i++ )
cout << test[i] << " ";
cout << endl << maxSubsequenceSum2( test, ss, se ) << endl;
cout << " (at position " << ss << " to " << se << ")" << endl;
return 0;
}
gerd@goedel:~/WEB-MATERIAL/fh/I-ALGO/I-ALGO-EX/EX1> ./msum-o-n2 Number of elements for sequence = 3 Thank you; we will start now collecting your input! Any integer = -3 Any integer = 5 Any integer = 1 -3 5 1 6 (at position 1 to 2)
//----------------------------
//
// msum-o-nlogn.cpp
//
// author: m.a.weiss
// modifications: g.doeben-henisch (march-12, 2003)
//
// Recursive O( N log N ) maximum contiguous subsequence sum algorithm.
// Comparable: must have constructor from int, must have
// += and > defined, must have copy constructor
// and operator=, and must have all properties
// needed for vector.
//-------------------------------------------------------------
#include <stdlib.h>
#include <iostream>
#include <iomanip>
#include <vector>
using namespace std;
template <class Comparable>
Comparable max3( const Comparable & a, const Comparable & b, const Comparable & c )
{
return a > b ?
( a > c ? a : c ) :
( b > c ? b : c );
}
template <class Comparable>
Comparable maxSubSum( const vector<Comparable> & a, int left, int right )
{
Comparable maxLeftBorderSum = 0, maxRightBorderSum = 0;
Comparable leftBorderSum = 0, rightBorderSum = 0;
int center = ( left + right ) / 2;
if( left == right ) // Base Case.
return a[ left ] > 0 ? a[ left ] : 0;
Comparable maxLeftSum = maxSubSum( a, left, center );
Comparable maxRightSum = maxSubSum( a, center + 1, right );
for( int i = center; i >= left; i-- )
{
leftBorderSum += a[ i ];
if( leftBorderSum > maxLeftBorderSum )
maxLeftBorderSum = leftBorderSum;
}
for( int j = center + 1; j <= right; j++ )
{
rightBorderSum += a[ j ];
if( rightBorderSum > maxRightBorderSum )
maxRightBorderSum = rightBorderSum;
}
return max3( maxLeftSum, maxRightSum,
maxLeftBorderSum + maxRightBorderSum );
}
// Public driver.
template <class Comparable>
Comparable maxSubsequenceSum3( const vector<Comparable> & a )
{
return a.size( ) > 0 ? maxSubSum( a, 0, a.size( ) - 1 ) : 0;
}
// Test program.
int main( void )
{
unsigned int length;
vector<int> test; //Empty vector
cout << "Number of elements for sequence = " ;
cin >> length;
test.resize(length); //Fitting vector to user input
cout << endl << "Thank you; we will start now collecting your input! " << endl ;
for( int i = 0; i < test.size( ); i++ ){
cout << "Any integer = " ;
cin >> test[i];
}
for( int i = 0; i < test.size( ); i++ )
cout << test[i] << " ";
cout << endl << maxSubsequenceSum3( test ) << endl;
return 0;
}
gerd@goedel:~/WEB-MATERIAL/fh/I-ALGO/I-ALGO-EX/EX1> ./msum-o-nlogn Number of elements for sequence = 3 Thank you; we will start now collecting your input! Any integer = -3 Any integer = 5 Any integer = 1 -3 5 1 6
//----------------------------
//
// msum-o-n.cpp
//
// author: m.a.weiss
// modifications: g.doeben-henisch (march-12, 2003)
//
// Linear maximum contiguous subsequence sum algorithm.
// Comparable: must have constructor from int, must have
// += and > defined, must have copy constructor
// and operator=, and must have all properties
// needed for vector.
// seqStart and seqEnd represent the actual best sequence.
//
//-------------------------------------------------------------
#include <stdlib.h>
#include <iostream>
#include <iomanip>
#include <vector>
using namespace std;
template <class Comparable>
Comparable maxSubsequenceSum4( const vector<Comparable> & a,
int & seqStart, int & seqEnd )
{
int n = a.size( );
Comparable thisSum = 0;
Comparable maxSum = 0;
for( int i = 0, j = 0; j < n; j++ )
{
thisSum += a[ j ];
if( thisSum > maxSum )
{
maxSum = thisSum;
seqStart = i;
seqEnd = j;
}
else if( thisSum < 0 )
{
i = j + 1;
thisSum = 0;
}
}
return maxSum;
}
// Test program.
int main( void )
{
unsigned int length;
vector<int> test; //Empty vector
int ss = -1, se = -1; // ss := SeqStart, se := SeqEnd
cout << "Number of elements for sequence = " ;
cin >> length;
test.resize(length); //Fitting vector to user input
cout << endl << "Thank you; we will start now collecting your input! " << endl ;
for( int i = 0; i < test.size( ); i++ ){
cout << "Any integer = " ;
cin >> test[i];
}
for( int i = 0; i < test.size( ); i++ )
cout << test[i] << " ";
cout << endl << maxSubsequenceSum4( test, ss, se ) << endl;
cout << " (at position " << ss << " to " << se << ")" << endl;
return 0;
}
gerd@goedel:~/WEB-MATERIAL/fh/I-ALGO/I-ALGO-EX/EX1> ./msum-o-n Number of elements for sequence = 3 Thank you; we will start now collecting your input! Any integer = -3 Any integer = 5 Any integer = 1 -3 5 1 6 (at position 1 to 2)
gerd@goedel:~/WEB-MATERIAL/fh/I-ALGO/I-ALGO-EX/EX1> ./MaxSum 225 (at position 52 to 98) 225 225 (at position 52 to 98) 225 (at position 52 to 98) Algorithm #4 N = 1 time = 0.000001 Algorithm #3 N = 1 time = 0.000002 Algorithm #2 N = 1 time = 0.000001 Algorithm #1 N = 1 time = 0.000001 --------------------------------------------------- Algorithm #4 N = 10 time = 0.000003 Algorithm #3 N = 10 time = 0.000010 Algorithm #2 N = 10 time = 0.000007 Algorithm #1 N = 10 time = 0.000026 --------------------------------------------------- Algorithm #4 N = 100 time = 0.000014 Algorithm #3 N = 100 time = 0.000123 Algorithm #2 N = 100 time = 0.000494 Algorithm #1 N = 100 time = 0.015625 --------------------------------------------------- Algorithm #4 N = 1000 time = 0.000112 Algorithm #3 N = 1000 time = 0.001601 Algorithm #2 N = 1000 time = 0.048780 Algorithm #1 N = 1000 time = 14.000000 --------------------------------------------------- Algorithm #4 N = 10000 time = 0.000689 Algorithm #3 N = 10000 time = 0.019417 Algorithm #2 N = 10000 time = 4.000000 Algorithm #2 N = 10000 time = still running ---------------------------------------------------
Here is the example source-code from [WEISS 2000] showing the four different algorithms 'behind' the measured data above together with an empirical time-checking function.
#include <stdlib.h>
#ifdef USE_DOT_H
#include <iostream.h>
#include <iomanip.h>
#else
#include <iostream>
#include <iomanip>
#if !defined( __BORLANDC__ ) || __BORLANDC__ >= 0x0530
using namespace std; // Borland has a bug
#endif
#endif
#ifndef SAFE_STL
#include <vector>
using std::vector;
#else
#include "vector.h"
#include "StartConv.h"
#endif
// Cubic maximum contiguous subsequence sum algorithm.
// Comparable: must have constructor from int, must have
// += and > defined, must have copy constructor
// and operator=, and must have all properties
// needed for vector.
// seqStart and seqEnd represent the actual best sequence.
template <class Comparable>
Comparable maxSubsequenceSum1( const vector<Comparable> & a,
int & seqStart, int & seqEnd )
{
int n = a.size( );
Comparable maxSum = 0;
for( int i = 0; i < n; i++ )
for( int j = i; j < n; j++ )
{
Comparable thisSum = 0;
for( int k = i; k <= j; k++ )
thisSum += a[ k ];
if( thisSum > maxSum )
{
maxSum = thisSum;
seqStart = i;
seqEnd = j;
}
}
return maxSum;
}
// Quadratic maximum contiguous subsequence sum algorithm.
// Comparable: must have constructor from int, must have
// += and > defined, must have copy constructor
// and operator=, and must have all properties
// needed for vector.
// seqStart and seqEnd represent the actual best sequence.
template <class Comparable>
Comparable maxSubsequenceSum2( const vector<Comparable> & a,
int & seqStart, int & seqEnd )
{
int n = a.size( );
Comparable maxSum = 0;
for( int i = 0; i < n; i++ )
{
Comparable thisSum = 0;
for( int j = i; j < n; j++ )
{
thisSum += a[ j ];
if( thisSum > maxSum )
{
maxSum = thisSum;
seqStart = i;
seqEnd = j;
}
}
}
return maxSum;
}
template <class Comparable>
Comparable max3( const Comparable & a, const Comparable & b, const Comparable & c )
{
return a > b ?
( a > c ? a : c ) :
( b > c ? b : c );
}
// Recursive O( N log N ) maximum contiguous subsequence sum algorithm.
// Comparable: must have constructor from int, must have
// += and > defined, must have copy constructor
// and operator=, and must have all properties
// needed for vector.
template <class Comparable>
Comparable maxSubSum( const vector<Comparable> & a, int left, int right )
{
Comparable maxLeftBorderSum = 0, maxRightBorderSum = 0;
Comparable leftBorderSum = 0, rightBorderSum = 0;
int center = ( left + right ) / 2;
if( left == right ) // Base Case.
return a[ left ] > 0 ? a[ left ] : 0;
Comparable maxLeftSum = maxSubSum( a, left, center );
Comparable maxRightSum = maxSubSum( a, center + 1, right );
for( int i = center; i >= left; i-- )
{
leftBorderSum += a[ i ];
if( leftBorderSum > maxLeftBorderSum )
maxLeftBorderSum = leftBorderSum;
}
for( int j = center + 1; j <= right; j++ )
{
rightBorderSum += a[ j ];
if( rightBorderSum > maxRightBorderSum )
maxRightBorderSum = rightBorderSum;
}
return max3( maxLeftSum, maxRightSum,
maxLeftBorderSum + maxRightBorderSum );
}
// Public driver.
template <class Comparable>
Comparable maxSubsequenceSum3( const vector<Comparable> & a )
{
return a.size( ) > 0 ? maxSubSum( a, 0, a.size( ) - 1 ) : 0;
}
// Linear maximum contiguous subsequence sum algorithm.
// Comparable: must have constructor from int, must have
// += and > defined, must have copy constructor
// and operator=, and must have all properties
// needed for vector.
// seqStart and seqEnd represent the actual best sequence.
template <class Comparable>
Comparable maxSubsequenceSum4( const vector<Comparable> & a,
int & seqStart, int & seqEnd )
{
int n = a.size( );
Comparable thisSum = 0;
Comparable maxSum = 0;
for( int i = 0, j = 0; j < n; j++ )
{
thisSum += a[ j ];
if( thisSum > maxSum )
{
maxSum = thisSum;
seqStart = i;
seqEnd = j;
}
else if( thisSum < 0 )
{
i = j + 1;
thisSum = 0;
}
}
return maxSum;
}
#include <time.h>
void getTimingInfo( int n, int alg )
{
vector<int> test( n );
int ss = -1, se = -1;
clock_t startTime;
int totalTime = 0;
int i;
for( i = 0; totalTime < 02 * CLOCKS_PER_SEC; i++ )
{
for( int j = 0; j < test.size( ); j++ )
test[ j ] = rand( ) % 100 - 50;
startTime = clock( );
switch( alg )
{
case 1:
maxSubsequenceSum1( test, ss, se );
break;
case 2:
maxSubsequenceSum2( test, ss, se );
break;
case 3:
maxSubsequenceSum3( test );
break;
case 4:
maxSubsequenceSum4( test, ss, se );
break;
}
totalTime += clock( ) - startTime;
}
cout.setf( ios::fixed, ios::floatfield );
cout.precision( 6 );
double elapsed = totalTime / CLOCKS_PER_SEC;
cout << "Algorithm #" << alg << "\t"
<< "N = " << setw( 8 ) << test.size( )
<< "\ttime = " << setw( 12 ) << ( elapsed / i ) << endl;
}
// Test program.
int main( void )
{
const int ARRAY_SIZE = 100;
vector<int> test( ARRAY_SIZE );
int ss = -1, se = -1;
for( int i = 0; i < test.size( ); i++ )
test[ i ] = rand( ) % 100 - 50;
cout << maxSubsequenceSum4( test, ss, se ) << endl;
cout << " (at position " << ss << " to " << se << ")" << endl;
cout << maxSubsequenceSum3( test ) << endl;
cout << maxSubsequenceSum2( test, ss, se ) << endl;
cout << " (at position " << ss << " to " << se << ")" << endl;
cout << maxSubsequenceSum1( test, ss, se ) << endl;
cout << " (at position " << ss << " to " << se << ")" << endl;
// Get some timing info
for( int n = 1; n <= 100000; n *= 10 )
for( int alg = 4; alg >= 1; alg-- )
{
if( alg == 1 && n > 50000 )
continue;
getTimingInfo( n, alg );
}
return 0;
}
#ifdef SAFE_STL
#include "EndConv.h"
#endif
There are many options how to continue from here now. In the next lecture we will have a look to 'recursion'. A very interesting topic.
Exercices are given during the Session at Monday
What is the difference between a 'real' program running on a 'real' computer compared to an algorithm and an automaton?
What are the main components of an automaton? How do they work together? How can you describe the behaviour of an automaton?
In which sense can we speak about 'resources' in the context of algorithms and automata?
What does it mean that an algorithm is 'correct'? How can we show, that an algorithm is correct?
What are 'flowcharts'? Why can we say that it is possible to represent every algorithm as a flowchart?
How would you explain the relationship between the abstract numbers describing the time an algorithm will need while running on an automaton and the empirical numbers describing the time needed by an algorithm implememnted on a real computer?
Which typical examples of functions do you know which describing the time needed depending from input n?
How do you explain the big-Oh notation to your friend? Why do we use the Big-Oh-notation at all?
What would be the big-Oh-representtion of the two functions f1 and f2: f1(N) = 5*N3+N2+1500*N+4000; f2(N) = 5*N3
Hint: Try to translate the algorithms from the examples above into flowchart-representations.
Hint: Try to translate the indivudal parts of the flowchart-representations into partial time-functions; combine all functions into one function.
Hint: Try to construct a general statement (= proof) about the time which the algorithm in the 'worst case' will need.