GRUNDLAGEN DER INFORMATIK/ THORETISCHE INFORMATIK - Mengentheoretische NotationAUTHOR: Gerd Döben-Henisch DATE OF FIRST GENERATION: Oct-9, 2001 DATE OF LAST CHANGE: April-3, 2006 EMAIL: Gerd Döben-Henisch |
Es handelt sich hier um eine informelle Sammlung von verwendeten
Zeichen und Begriffen, die keinen Anspruch auf
systematische Vollständigkeit erhebt. Diese Sammlung ist gedacht als
Ergänzung zu den verschiedensten Lehrveranstaltungen.
Basisbegriffe aus der Mengenlehre
|
|
Im Zusammenhang des Themas Berechenbarkeit/ Entscheidbarkeit wichtige Begriffe: primitiv rekursive Funktionen, Ackermann Funktion, my-rekursive Funktionen, allgemein rekursive Funktionen, rekursive Prädikate |
Graphen
|
BäumeEin Baum ('tree') ist ein geordneter Graph mit den folgenden zusätzlichen Eigenschaften:
Abweichend von der Graphen-Terminologie gibt es bei Bäumen eine spezielle Terminologie:
|
StrukturtheorieIn der allgemeinen Strukturtheorie werden in Anlehnung an das Programm von BOURBAKI jene Strukturen formuliert, die als Basis für alle anderen speziellen Strukturen dienen.(irgendwann aufschreiben...) |
Algebra
|
MasstheorieMit Begriffen wie Ring, sigma-vollständiger und delta-vollständiger Ring, Borel-Ring, Borel-Menge, allgemeiner Halbring mit einem Mass usf. Grndzüge der Masstheorie |
WahrscheinlichkeitstheorieAusgehend von Begriffen wie sigma-Algebra und Borel-Menge Grundzüge einer axiomatischen Wahrscheinlichkeitstheorie |
Bayessche Netze |
Optimierungstheorie |
Maschinelles Lernen |
Formale SprachenIm Kontext von formalen Sprachen werden endliche Mengen
auch benutzt, um Alphabete zu repräsentieren.
|
|
Mittels der Menge A* und der Operation Konkatenation 'o' lässt sich jetzt eine Struktur <A*, o > als Halbgruppe mit neutralem Element (Monoid) definieren, die folgende Eigenschaften haben soll: Für alle x,y ∈ A* soll gelten:
Damit kann man vereinbaren: wenn w, u1,u2, v Worte über einem Alphabet A sind, dann gilt:
Beispiele: die Menge der Theoreme und Nichttheoreme bei formalen Systemen. Wenn eine Zeichenkette w ein Theorem ist, dann gibt es dazu einen endlichen Beweis, der sich nach endlich vielen Schritten finden lässt; eine DTM angesetzt auf ein w als Theorem würde also nach endlich vielen Schritten stoppen. Wäre die Eingabe w ein Nichttheorem, dann gäbe es dazu keinen Beweis; die Suche nach einem solchen nichtvorhandenen Beweis müsste nicht nach endlich vielen Schritten stoppen. Verschiedene Versuche, 'entscheidbare Eigenschaften' von Nichttheoremen relativ zu einem bestimmten formalen System zu finden, waren für bestimmte Teilmengen von Nichttheoremen bislang erfolgreich, aber einer vollständigen Lösung widersetzt sich die Menge der Nichttheoreme bis heute hartnäckig (vgl. dazu auch [Döben 1990]). |
AutomatenIm Grundlagenstreit um die Entscheidbarkeit mathematischer Theorien hatte sich gezeigt, dass eine Minimalvoraussetzung für eine befriedigende Diskussion um die Entscheidbarkeit darin bestand, dass die Beweisführung in einem endlichen Verfahren mit endlichen Mitteln stattzufinden habe. Anders formuliert heisst dies, dass solch ein effektives Verfahren intutiv die folgenden Eigenschaften besitzen sollte:
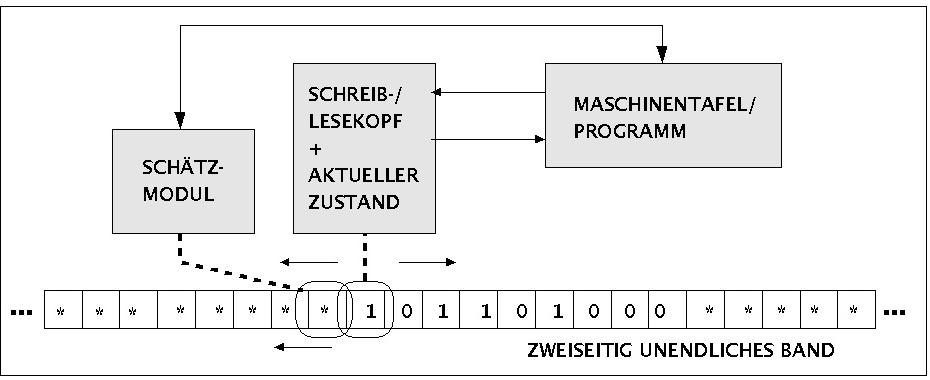
Dasjenige Verfahren, das diesen intuitiven Forderungen nach Auffassung von GÖDEL und CHURCH historisch als erstes am nächsten kam, war ein Verfahren von TURING aus dem Jahr 1936, das von CHURCH Turingmaschine genannt wurde. Wie sich im Laufe der Jahre zeigte, konnten bislang alle anderen Verfahren, die auch den Anspruch erhoben, ein effektives Verfahren zu sein, als mit der Turingmaschine äquivalent erwiesen werden. Wir beginnen daher die Darstellung der Automaten mit dem Konzept der Turingmaschine; andere Automatentypen folgen. 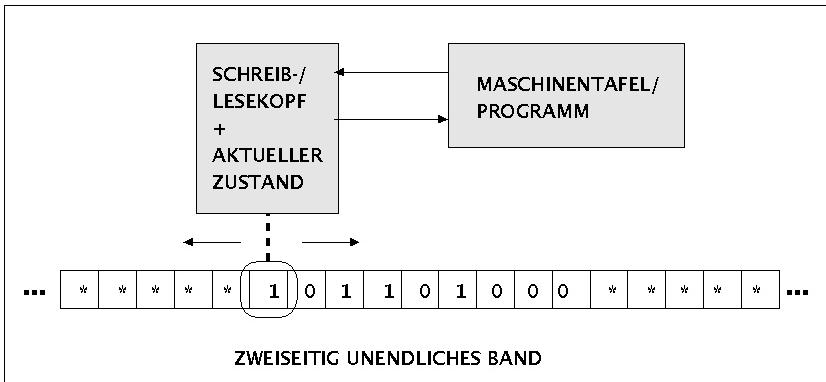
Deterministische 1-Band Turingmaschine Wir wählen hier die Form der deterministischen Turingmaschine (DTM) mit einem Band.. Wie später gezeigt wird, sind andere Formen von Turingmaschinen (1/2-Band, mehrere Bänder, universelle Turingmaschine, nichtdeterministische Turingmaschine usw. nicht stärker als eine DTM). Intuitiv besteht eine Turingmaschine aus einem nach beiden
Seiten offenen Band ('tape'), das gleichmässig in rechteckige
Felder ('squares') unterteilt ist. Zu Beginn einer Rechnung
ist das Band leer bis auf eine endliche Menge von Symbolen I
aus
einem endlichen Alphabet A, die nacheinander auf das Band
geschrieben sind, pro Feld ein Symbol. Alle anderen Felder
enthalten das leere Zeichen '§', das nicht zum Alphabet A
gehört (A - {§}) (In der Literatur gibt es eine Vielzahl von
Konventionen zur Bezeichnung des leeren Feldes {'b', 'B', 'kleines
Epsilon', 'leeres Quadrat, 'Unterstrich mit Winkeln nach
oben', '*'}. Das Alphabet A ist nicht leer. Zu Beginn der Rechnung
steht der Schreib-Lese-Kopf genau über dem ersten Feld
der Inschrift I. Die Turingmaschine befindet sich im Start-Zustand q0.
Die Menge aller Zustände Q ist endlich.
Neben dem Startzustand q0 enthält sie noch eine endliche
Menge von Endzuständen E = {qe.1, ...,qe.k }
mit k > 1. Die Aktionen einer DTM sind in der
Maschinentafel, dem 'Programm' der Turingmaschine,
festgelegt. Eine Maschinentafel besteht aus einer endlichen nichtleeren
Menge von Übergangsregeln D, wobei eine einzelne
Übergangsregel di die Form hat: Eine einzelne Übergangsregel ist wie folgt zu lesen:
vj, v'j sind aus G = A u {§} und
Beginnend mit dem Startzustand q0 auf dem ersten Zeichen einer Inschrift I wird eine DTM also einzelne Aktionen anhand der Menge der Übergangsregeln in der Maschinentafel ausführen. Grundsätzlich sind nun drei Fälle denkbar:
Tritt Fall (2) ein, dann soll die Konvention gelten, dass die DTM die ursprüngliche Eingabe I gelöscht hat und der Schreib-Lesekopf am Ende wieder auf dem ersten Zeichen des Ergebnisses steht; das Ergebnis kann leer sein. Damit kann man nun folgende formalisierte Darstellung einer deterministischen Turingmaschine (DTM) geben: DTM(m) gdw m = < < Q, A, G, {§}, {q0 }, E, D >, < d0, ..,dn > > mit
|
KomplexitätstheorieIn der Komplexitätstheorie wird die 'Komplexität'
('complexity') eines Problems gemessen am Ressourcenbedarf für seine
Repräsentation und für seine Lösung. Neben der Ressource 'Platz'
('space') ist es vor allem der 'Zeitbedarf' ('time'), der zur
Charakterisierung benutzt wird.
In der nachfolgende Tabelle sieht man eine Beispielmaschine für die Inputlängen n=10 ... 60 mit unterschiedlichem polynomem oder exponentiellem Zeitbedarf: |
| |
n = | 10 | 20,00000000 | 30,00000000 | 40,00000000 | 50,00000000 | 60,00000000 | |
| n^1 | 1 | 0,00001000 | 0,00002000 | 0,00003000 | 0,00004000 | 0,00005000 | 0,00006000 | <- sec |
| n^2 | 2 | 0,00010000 | 0,00040000 | 0,00090000 | 0,00160000 | 0,00250000 | 0,00360000 | <- sec |
| n^3 | 3 | 0,00100000 | 0,00800000 | 0,02700000 | 0,06400000 | 0,12500000 | 0,21600000 | <- sec |
| n^5 | 5 | 0,00166667 | 0,05333333 | 0,40500000 | 1,70666667 | 5,20833333 | 12,96000000 | <- min |
| 2^n | |
0,00000000 | 0,00000000 | 0,00000032 | 0,00032464 | 0,33242982 | 340,40813510 | <- Jahrhunderte |
|
Zwar steigt auch der polynome Zeitbedarf mit der Inputlänge n bei n^5 deutlich an, aber der exponentielle Zeitbedarf für 2^n ist schon dramatisch höher, ganz zu schweigen von Werten wie 3^n, 4^n usf. Von daher gilt die Daumenregel, dass effiziente Algorithmen in polynomialer Zeit arbeiten, ineffiziente in exponentieller Zeit. Bei kleinen Inputlängen muss dies allerdings nicht gelten; da kann ein exponentieller Algorithmus u.U. sogar schneller sein als ein polyniomialer. Ferner sagt die Erfahrung, dass in der Praxis effiziente Algorithmen solche polynomialen Algorithmen sind, die höchsten Grad 2-3 haben.
Obwohl die Komplexitätsklasse P hier mithilfe der deterministischen Turingmaschine definiert wurde, kann man sagen, dass diese Aussagen aufgrund der Äquivalenz (bis auf einen polynomialen Faktor) aller heutzutage bekannter Berechnungsverfahren auf jeden beliebigen Computer zutreffen. Am Beispiel des Traveling-Salesman-Problems kann man sich klar machen, was dies bedeutet. Bei n Städtenamen benötigt man eine n * n = n2-Matrix, um die Entfernungen zwischen den Städen zu kodieren. Das ist nicht exponentiell. Will man nun aber für einen beliebigen Ausgangspunkt ermitteln, welcher der Wege unter einer gewissen Schranke ('bound') B liegt, so muss man im schlechtesten Fall ('worst case') alle Möglichkeiten durchprüfen. Bei n-vielen Namen bedeutet dies, dass man beim Start (n-1)-viele Möglichkeiten hat, im zweiten Schritt (n-2)-viele Möglichkeiten, ... m.a.W. die Gesamtheit der möglichen Werte ist Multipliziert man die Formel aus, dann erhält man ein Polynom vom Grade (n-2), also nn-2. Das ist 'nahezu' exponentiell.
|
| tm(x)= | IF x ∈ L(m) ==> min({ k | (E:P) PROTOCOL(P,m,x,k) )} ) |
| ELSE 0 |
|