Durch den Einsatz moderner Computer im Kontext wissenschaftlicher Theorien eröffnet sich die Möglichkeit, die formalen Theorien als solche Strukturen bzw. Modelle zu realisieren, die sich auf einem Computer ausführen lassen. Dies führt zwar einerseits zu einer Einschränkung der Ausdruckskraft der verwendbaren Theoriesprache 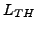 auf solche Sprachen, die berechenbar sind, aber auf der anderen Seite werden solche Theorien tatsächlich nutzbar. Bezogen auf das Bild 2.2 kann man sagen, dass in computergestützten Theorien die verwendeten Modelle letztlich durch formale Automaten darstellbar und die Schlussfolgerungen in Form von Simulationen (bzw. verifizierenden Algorithmen) verfügbar sind. Die solcherart berechneten Folgezustände (=Theoreme) können in der Regel dann direkt mit den verfügbaren Daten verglichen werden. Lassen sich Folgezustände nicht verifizieren, dann stellt sich das Modell damit in Frage, wenngleich eine direkte Widerlegung grundsätzlich sehr schwierig sein wird.
auf solche Sprachen, die berechenbar sind, aber auf der anderen Seite werden solche Theorien tatsächlich nutzbar. Bezogen auf das Bild 2.2 kann man sagen, dass in computergestützten Theorien die verwendeten Modelle letztlich durch formale Automaten darstellbar und die Schlussfolgerungen in Form von Simulationen (bzw. verifizierenden Algorithmen) verfügbar sind. Die solcherart berechneten Folgezustände (=Theoreme) können in der Regel dann direkt mit den verfügbaren Daten verglichen werden. Lassen sich Folgezustände nicht verifizieren, dann stellt sich das Modell damit in Frage, wenngleich eine direkte Widerlegung grundsätzlich sehr schwierig sein wird.
Figure 2.3:
Rahmen für computergestützte Theorie
|
![\includegraphics[width=4.5in]{engineering_framework_req_sr_model_sys_model_impl_validation.eps}](img14.png) |
Neben dem allgemeinen Rahmen der Theoriebildung soll in diesem Kurs allerdings mehr der Rahmen des allgemeinen Systems Engineerings benutzt werden. Wie im Bild 2.3 illustriert wird, werden mindestens die folgenden Elemente eines Engineering Prozesses angenommen:
- Problem: Ein Auftraggeber identifiziert eine Problemstellung, für die eine funktionierende Lösung gefunden werden soll. Im Falle von computergestützten lernenden Systemen handelt es sich in der Regel um Lernaufgaben, für die ein passendes technisches System gesucht wird.
- Anforderungen und Verhaltensmodell: Das Problem wird soweit analysiert, bis ein Anforderungstext erstellt werden kann, der alle die erwarteten Verhaltenseigenschaften des intendierten lernenden Systems enthält, die vom Auftraggeber gewünscht werden. Die beteiligten Akteure werden nur unter der Rücksicht ihrer beobachtbaren Schnittstelle beschrieben. Auf der Basis dieses Anforderungstextes wird dann das erwartete Verhalten (mit Hilfe von verknüpften Automaten) modelliert.
- Modell der Systemfunktion: Sofern das erwartete Verhalten fixiert ist, muss dann die interne Systemfunktion des lernfähigen Systems modelliert werden. Unter Berücksichtigung des neuronalen Prinzips sind dies neuronale Netze, die hier als verknüpfte Automaten verstanden werden. Der Input-Output der Systemfunktion ist definiert durch das Interface als Teil des Verhaltensmodells.
- Implementierung: man kann hier u.a. folgende Fälle unterscheiden. (i) Das Modell ist schon die Implementierung, da ein Interpreter verfügbar ist, der das Modell simuliert; (ii) das Modell wird direkt in eine bestimmte Zielsprache kompiliert, die sich dann auf einer gegebenen Plattform ausführen lässt; (iii) die Modelle werden direkt in FPGAs übersetzt, die sich als (Neuro-)Chips in ein technisches System direkt einbauen lassen.
- Validierung: In der Validierung wird das implementierte System des Lerners L mit einem realen Benutzer U in der vorgesehenen Umgebung E auf der Basis der Anforderungen getestet. Auch wenn die Verifikation ohne Beanstandung passiert worden ist kann dieser Test noch Mängel sichtbar machen.
Figure 2.4:
Rahmen für computergestützte Theorie mit Spezifikation und Verifikation
|
![\includegraphics[width=4.5in]{engineering_framework_req_sr_model_sys_model_spec_verification.eps}](img15.png) |
Innerhalb des allgemeinen Engineering Prozesses gibt es zwei weitere spezielle Teilprozesse (vgl. Bild 2.4): die formale Spezifikation von Eigenschaften im Bereich des beobachtbaren Verhaltens sowie die formale Spezifikation von Eigenschaften im Bereich des Verhaltens der Systemfunktion.
Zwar kann man auch informell über Verhaltenseigenschaften sprechen, im Falle von komplexen Verhaltensweisen mit vielen Eigenschaften, die sich schnell und wechselwirkend ändern können, ist ein menschlicher Beobachter aber schnell überfordert. Hier können letztlich nur formale Spezifikationen zum Einsatz kommen, die wiederum vollautomatisch verifiziert werden können.
Hier stellt sich die spannende Frage, wieviele der vom Phänomen her interessanten komplexen Eigenschaften des Lernens sich auf diese Weise beschreiben und verifizieren lassen.
Für die Umsetzung dieses Programms bedeutet dies, dass unter Voraussetzung eines definierten Konzepts eines Engineering Prozesses folgende Schritte ausgeführt werden sollen:
- Aus einer Liste von zu lösenden Problemen wird das nächste noch nicht gelöste Problem ausgewählt.
- Dann wird dazu ein Experiment mit einem biologischen System durchgeführt und die Verhaltensdaten werden protokolliert.
- Unter Einbeziehung dieser Daten wird für das Problem ein geeignetesVerhaltensmodell erstellt.
- Das Verhaltensmodell wird mittels einer formalen Spezifikation automatisch bezüglich wichtiger Eigenschaften verifiziert.
- Dann wird eine Systemfunktion modelliert, die die Verhaltensanforderungen bedienen kann. Im Ergebnis muss die Systemfunktion als ein neuronales Netz konstruiert werden, das diesen Anforderungen genügt.
- Das Systemmodell wird mittels einer formalen Spezifikation automatisch bezüglich wichtiger Eigenschaften verifiziert.
- Implementierung der Systemfunktion (standardmäßig mittels Interpreter; daneben vorzugsweise automatisch als Neurochip)
- Validierung des implementierten Systems auf der Basis der Anforderungen einschliesslich des Verhaltensmodells
- Vergleich der Ergebnisse mit denen des biologischen Systems
- Gesamtauswertung.
Gerd Doeben-Henisch
2010-12-16