
10th International Congress of the German Association for Semiotic Studies (DGS) |
This paper describes a research program with a first experimental setting. It starts with basic assumptions about the essential properties of a computational semiotic agent and Computational Semiotics as a scientific and engineering discipline. It explores then this paradigm in the context of the task of translating ordinary texts into pictures. Because the project of a Picture Compiler is a rather large undertaking can this paper only describe the very first steps of such a project.
Semiotics, Computational Semiotics, Agent, Semiotic Agent, Computational Semiotic Agent, Intelligent System, Meaning, Lexical-Grammatical-Semantical Parser, Semantic Network, Morris' Semiotics, Sign, Conditioning, Brain Models, Picture Interface
1. Computational Semiotics as a Scientific and Engineering Discipline
In his paper [2] the author showed how one can reframe the concept of Charles Morris' semiotics within the framework of modern Theory of Science. From this follows that semiotics can be done as a 'real Science'. In a follow-up paper [4] the author demonstrated furthermore the equivalence between 'semiotics' and 'computational semiotics'. Taking the concept of a 'scientific theory' as the common point of reference, it is shown how the concept of the Turing machine and the concept of semiotics can be reconstructed uniformly within this framework. Finally, it is shown how one can construct a mapping between the concept of 'semiotic agent' as proposed by Morris [12][13] and the concept of the Turing machine, which has been introduced by A.M.Turing [17]. The result is that everything that can be said about a semiotic agent within Morris's concept of semiotics can also be stated in terms of the Turing machine concept. These findings are laying a firm ground for Computational Semiotic Machines and for Computational Semiotics as a discipline.
In this article the author shows an application of this general framework of computational semiotics to a concrete problem, the Picture Compiler. A Picture Compiler takes as input ordinary language texts which describe sequences of scenarios of objects occurring in space, transforms these texts according to a given network of semantic relations into some abstract pictorial representation and outputs this representation as a series of images. As simple as this process can be in the beginning, it shows some fundamental properties of Computational Semiotic Processes as the 'Soul' of a Computational Semiotic Agent.
Due to the fact that the topic of a computational semiotic agent as well as the special topic of a picture compiler is still in its infancy is the content of this paper highly experimental. The author is reporting from an ongoing project which is in an initial stage. Several methodological issues have still to be investigated and experimental setups have to be optimized further.
Let us start with a simple example. You are reading a book and You are reading the sentence:
S1: Im Garten steht ein weisser Gartenstuhl und die Sonne scheint.
(Transl.: In the garden there is a white garden chair and the sun is shining.)
Usually most people would agree that this sentence is not a picture. It is a sequence of alphabetical signs. But people would also agree that, while reading that sequence of alphabetical signs, one has some imagination and that it is just this 'imagination' which in this case is associated with that what we rather vaguely are calling meaning.
But, although there can be find an agreement that this sentence is not a picture, we can decide on the basis of this sentence whether some picture represents somehow the meaning of the sentence or not.
Let us look to the following simple picture:
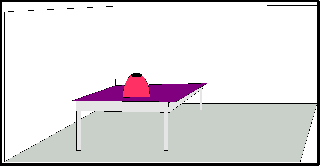
Fig.1 TABLE IN A ROOM
Usually the audience will agree that this picture is not a representation of the meaning of the sentence S1. We are missing a sufficient similarity between this picture and the meaning which we associate with the sentence S1.
Asking someone to answer the question, why he/she thinks that this picture is not an acceptable representation of the meaning of the sentence, we could get an answer like the following:
S2: This picture (= Fig.1) ) shows a room with a table and something on the table, but not a garden, not a garden chair and no sun shining.
Now let us present the following simple picture:
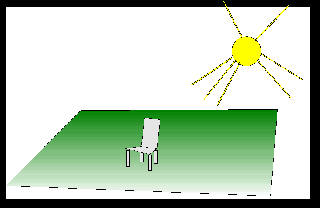
Fig.2 CHAIR ON LAWN WITH SUN
Asking again whether this picture could be an acceptable representation of the sentence, we would probably get the following answer:
S3: Yes, there is a sun shining, and a chair, which could be a white garden chair, which is standing on a lawn; some gardens consists only of a lawn, thus one could accept this picture as a possible representation of the meaning of sentence S1.
Thus daily communication induces the impression, that there exists relationships between the meaning of sentences and pictures and that these relationships are somehow decidable: not every picture P is an acceptable representation of the meaning M of a sentence S, but only those pictures P* which satisfy certain criteria.
Would we continue in this process of asking people about the meaning of their meaning by urging them to explain us, what these criteria could be which led them to accept one picture in one case and to reject other pictures in other cases, then it should become difficult for a normal person to continue its explanation.
To say in one case that the picture shows no garden but a room, while the sentence is speaking about a garden is just this: in one case we can state a valid relationship between certain properties of a picture with the presupposed meaning of the sentence and in another case we can not; it is this relationship by which the meaning of the sentence manifests itself.
Until now we referred to our daily experience. Let us now reframe this matter in a more theoretical view (cf. [1], [2]).
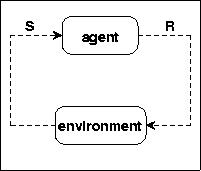
Fig.3 AGENT ENVIRONMENT
We will analyze the problem with the basic terms agent [A] and environment [E]. The environment stimulates the agent by Stimuli [S] and the agent can respond to the environment by Reactions [R].
Terminological remark: To use here the term 'Agent' instead of the term 'System' is a bit a question of taste. Principally one can every kind of an agent reconstruct as a system, but not necessarily vice versa. And, if one follows the hypothesis from A.Meystel, that intelligence presupposes necessarily the use of symbols, then are intelligent systems always per definition semiotic systems. Thus the terms 'intelligent system', 'semiotic system', 'semiotic agent' are highly synonymous terms.
For objects called agents we assume at least the following:
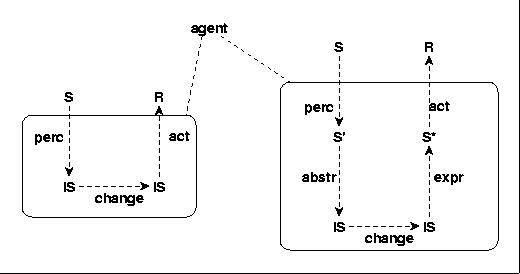
Fig.4 AGENT WITH INTERNAL STRUCTURES
An agent has perception [perc], its internal states [IS] can change , and it has some form of an action function [act] based on its internal states.
One can extend the concept of an agent in many ways. E.g. one can assume an additional abstraction function [abstr] which generalizes somehow the perceptions and an expression function [expr] which transform more abstract states into states which can then lead to concrete responses R. It holds: S' C IS, S* C IS.
With regard to our examples above we have e.g. to distinguish several kinds of Stimuli, e.g. Stext as text events and Spict as picture events. We assume:
Stext C S
Spict C S
Stext cut Spict = 0
From the point of view of an observer one can say, that this observer can make empirical observations as long as he is either only relying on the overt behavior of the agent in its environment or relying on covert behavior when he is dealing with physiological processes. So called phenomenalistic observations are produced when the observer and the agent are one and the same: in this case is the observer relying on his own subjective experience, which he can communicate by some language.
Above we have partially exploited phenomenalistic terms. We have used terms like 'imagination', 'meaning', 'agree', 'similarity' etc. Because phenomenalistic terms are rooted in the subjective experience it is in general difficult to give 'clearcut' definitions of the presupposed meaning of these terms because that, what constitutes the 'meaning' of these terms is only given in the form of intrapersonal states which can not be exchanged 'directly' during a communication, only 'mediated' by other processes.
One strategy to improve the communication of phenomenalistic terms is to provide formal models to represent the possibly intented logical structure of these terms. For the problem under discussion I propose the following introductory formal model:
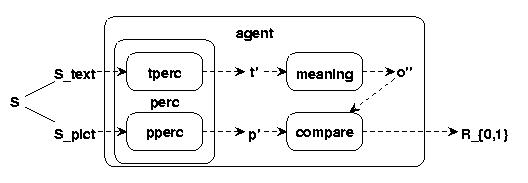
Fig.5 AGENT WITH TEXTS AND PICTURES
With this model I am interpreting the above cited everyday dialogue in the following way:
I am assuming that Stimuli [S] are generally perceived [perc] and by this perception transformed into some perceived units [S']. Text stimuli [S_text] = t and perceived text stimuli = t'; picture stimuli [S_pict] = p and perceived picture stimuli = p', with {t,p} C S and {t',p'} C S'. The perception is assumed as the following mapping: perc: S ---> S', and we can write: perc(t)=t' or perc(p)=p'.
S' C IS (whereby 'IS' shall denote some inner states of the agent).
Text perceptions t' can be related to some other inner states called o'', which form the 'meaning' of text perceptions t'. The relation which 'establishes' the meaning t' for the perceptions t' we will call the meaning function [mean]. The meaning function is assumed as: mean: S' ---> IS, and we can write: mean(t')=o''.
Finally we are assuming the possibility to decide about the similarity of the text meaning o'' compared to some picture perception p' as the following function: cmp: S' x IS ---> {0,1}, writing cmp(p',o'')=b with b in {0,1}.
This formal model does not make any assumptions about the way how these functions and units are realized in the system. It is only intended as some reconstruction of the logical structure underlying the before mentioned everyday dialogue about the relation between texts and pictures. And clearly, it is in no sense exhaustive at all; it is a partial reconstruction with the intention to open up a scientific discourse about the problem.
This model shows a system which, faced with a text and a picture, can react with 'yes' or 'no' regarding the similarity of the meaning of the text with the perceived picture. But the main topic of this paper is different: we are interested in the process where texts are converted into pictures. But the way from this model, regarding the decidability of the similarity between text meaning and picture perceptions, to the conversion of texts into pictures is straightforward.
If we assume that mapping from perceptions into some more abstract meaning units is not 'one way', but there is some way to map abstract inner states back to more simpler states like perceptions, say action states [S*], then we can assume a mapping chain which results into the conversion of texts into pictures:
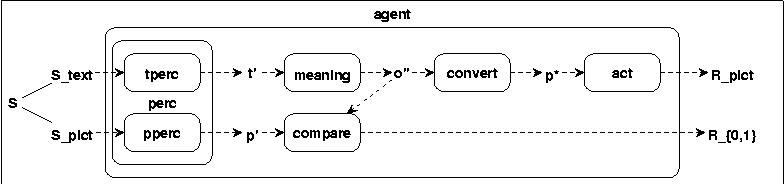
Fig.6 TEXTS INTO PICTURES: FIRST HYPOTHESIS
convert: O'' ---> P*, writing conv(o'',p*)
act: S* ---> R
P* C S* & S* C IS
If we call the meaning units o'' semantical objects or short objects then we can define the following hypothetical function:
top = act o convert o mean o perc (where the sign 'o' means the concatenation of functions)
We then can write: top(t)=p. This functions converts texts t into pictures p.
Before we continue with a more detailed analysis how such a conversion process can really work we will introduce the semiotic framework more explicitly.
The case of Computational Semiotics are not 'agents as such' but those agents, which are Semiotic Agents which can process 'signs'. But what are 'signs'?
Following Charles Morris (cf. my reconstruction in [2][4]) he introduces in a pre-scientific view several basic terms simultaneously to define the term 'sign'. The primary objects are distinguishable organisms which can act as interpreters [I] (the 'semiotic agents' in our terminology). An organism can act as an interpreter if it has internal states called dispositions [IS] ('internal states' in our terminology) which can be changed in reaction to certain stimuli. A stimulus [S] is any kind of physical energy which can influence the inner states of an organism. A preparatory-stimulus [PS] influences a response to some other stimulus. The source of a stimulus is the stimulus-object [SO]. The response [R] of an organism is any kind of observable muscular or glandular action ('covert behavior'). Responses can form a response-sequence [<r_1, ..., r_n>], whereby every singly intervening response r_i is triggered by its specific supporting stimulus. The stimulus-object of the first response in a chain of responses is the start object, and the stimulus-object of the last response in a chain of responses is the goal object. All response-sequences with similar start objects and similar goal objects constitute a behavior-family [SR-FAM].
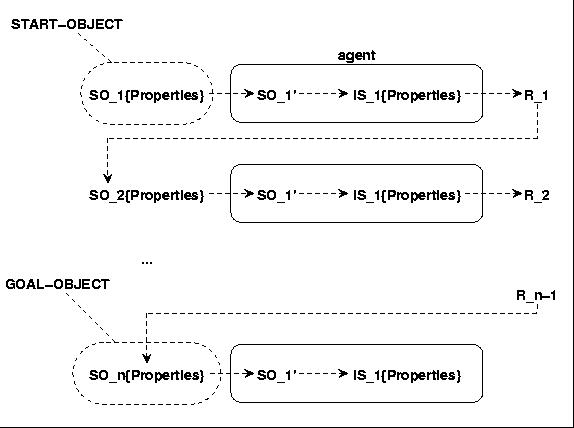
Fig.7 SEMIOTIC AGENT AS INTERPRETER
Based on these preliminary terms he then defines the characteristics of a sign [SGN] as follows: 'If anything, A, is a preparatory-stimulus which in the absence of stimulus-objects initiating response-sequences of a certain behavior-family causes a disposition in some organism to respond under certain conditions by response-sequences of this behavior-family, then A is a sign.' ([13]:10,17). Morris stresses that this characterization describes only the necessary conditions for the classification of something as a sign ([13]:12).
This entire group of terms constitutes the subject matter of the intended science of signs (= semiotics) as viewed by Morris (Morris 1946:17).
Clearly, Morris did not limit himself to characterizing in basic terms the subject matter of his 'science of signs' but introduced a number of additional terms. Strictly speaking, these terms establish a structure which is intended to shed some theoretical light on 'chaotic reality'. In a 'real' theory, Morris would have 'transformed' his basic characterizations into a formal representation (as Turing did with his postulated computing person), which could then be formally expanded by means of additional terms if necessary. But he didn't. Thus we can put only some of these additional terms into ordinary English to get a rough impression of the structure that Morris considered to be important.
Morris used the term interpretant [INT] for all interpreter dispositions (= inner states) causing some response-sequence due to a 'sign' (= preparatory-stimulus). And the goal-object of a response-sequence 'fulfilling' the sequence and in that sense completing the response-sequence Morris termed the denotatum of the sign causing this sequence. In this sense one can also say that a sign denotes something. Morris assumes further that the 'properties' of a denotatum which are connected to a certain interpretant can be 'formulated' as a set of conditions which must be 'fulfilled' to reach a denotatum. This set of conditions constitutes the significatum of a denotatum. A sign can trigger a significatum, and these conditions control a response-sequence that can lead to a denotatum, but do not necessarily do so: a denotatum is not necessary. In this sense, a sign signifies at least the conditions which are necessary for a denotatum but not sufficient (cf. [13]:17ff). A formulated significatum is then to be understood as a formulation of conditions in terms of other signs ([13]:20). A formulated significatum can be designative if it describes the significatum of an existing sign, and prescriptive otherwise. A sign-vehicle [SV] can be any particular physical event which is a sign ([13]:20). A set of similar sign-vehicles with the same significata for a given interpreter is called a sign-family.
Mapping Morris Terminology to our formal model would yield the interpretation, that the 'designation' is given by the properties of the perceived object and through these properties the agent can 'control' whether a given perception is the right 'denotatum' or not.
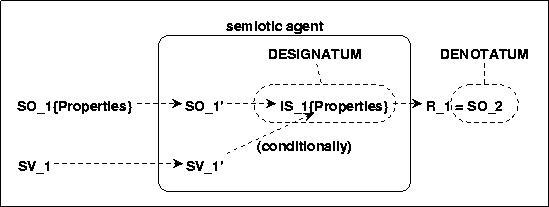
8. BIRTH OF A SIGN
The diagram shows that a stimulus object SO can function as a sign vehicle SV if the 'sign functioning' stimulus object can represent the original stimulus object SO during some time 'as if the original stimulus object would be there'. One known mechanism which can explain such a 'generation of a sign' is 'classical conditioning'.
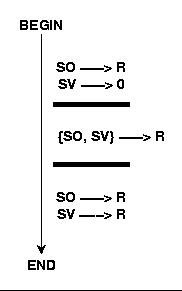
9. SCHEDULE FOR CONDITIONING
Such a kind of conditioning presupposes in the agent a mechanism which can 'detect' the 'simultaneity' of two stimuli SO and SV. If such a cooccurence happens it 'connects' the SV-stimulus to the representations connected to the SO-stimulus. If this connection is 'established' the agent can respond to the SV-stimulus 'as if' the SO-stimulus is given (In Neurobiology are neuronal circuits known which function like this (cf. e.g. [7] pp506f). Furthermore has the author shown [5][6], how one can directly implement such a neuronal conditioning mechanism within a neural network with 5 neurons. For the type of neurons used see [3].
Applying this to the case where the sign vehicles SV are texts, we get:
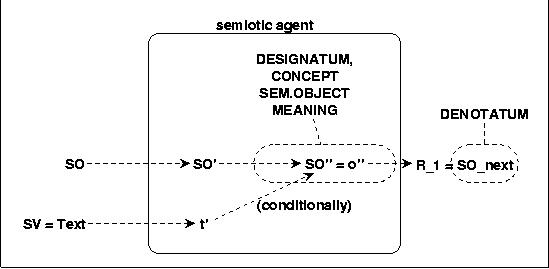
10. TEXT AS A SIGN
The sign vehicle text, which functions as a stimulus, can after perception be conditioned to certain abstract structures of perceived objects SO''. When this happens then are these abstract structures becoming the designatum (meaning) of the text. In other contexts are these abstract structures also called concepts or semantical objects.
In this section we will clarify, how it is possible to implement these general formal models into a working semiotic agent.
Putting all the different considerations so far together we are getting the following model as a starting point:
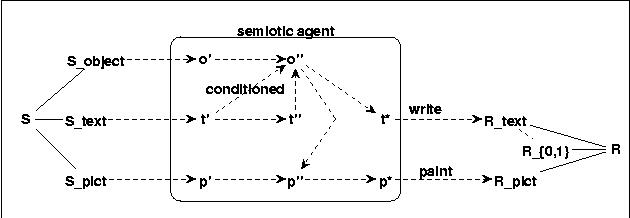
Fig.11 TEXT TO PICTURES: SECOND HYPOTHESIS
We have three kinds of stimuli: objects which don't serve as signs or pictures, and texts as well as pictures. For all these stimuli we assume at least two levels of representations in the system: the perceptional level (S') and a somehow more abstract level (S''). To convert these Representations into concrete responses as e.g. in the case of writing or painting there is another level of representation (S*) which serves especially for the concrete acts which are responsible for the observable responses R. The connection between the texts and the objects have explicitly to be conditioned. In this setting it is assumed that the painting of a picture caused by the perception of some text has to be realized by a mapping from the meaning of the text o'' into the abstract representation of a picture (p'') which in turn can then be converted into a representation for concrete painting (p*).
At this point in the discourse is this sketchy model still rather arbitrary. There was some intuition in the beginning from the discussed examples. Then we took over the model of Morris, which is more or less speculative regarding the assumptions about the internal structures of a semiotic agent. What we have is a logical concept which has to be made more precise and has to be turned into a working model.
The problem at this point is that until now there is no complete solution available, neither in Linguistics, neither in Psychology, neither in Neurobiology (cf. e.g. the excellent readers [8], [10], and [11]). And one has to decide which kind of a solution one wants to approach? Should it be any abstract solution without any connection to real living systems? Should it be a model based on an empirical theory? Or what?
Primarily I am interested in a solution which is 'as simple as possible'. But because the problem is endowed with an extreme complexity it would be nice to have some 'guiding line' which one could follow in search for a solution.
The only known working solution today is the brain in the body of living systems where the body again is embedded in a real environment. Any model which can copy the working brain sufficiently well must be close to a possible solution.
Therefore, although we don't want to develop a complete empirical theory about the brain we are interested in using the empirical results about the brain to induce experimental models which should lead to acceptable solutions.
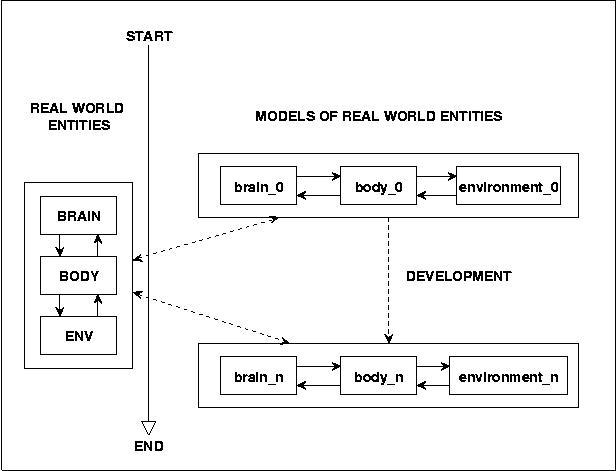
Fig.12 APPROACHING THE GOAL BY BRAIN MODELS
Picking up the 'real prototype' we will call such a setting Environment Based Learning Sytem [EBLS]. We will use such a setting for all our upcoming experiments. It holds:
stim_1: ENV ---> BODY
stim_2: BODY ---> BRAIN (stim_2 = perc of Agent)
act_2: BRAIN ---> BODY (act_2 = act of Agent)
act_1: BODY ---> ENV
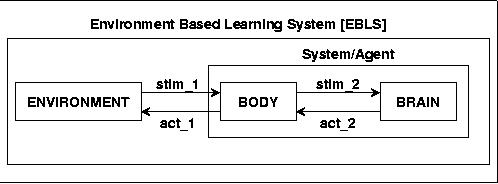
Fig.13 EBLS := ENVIRONMENT BASED LEARNING SYSTEM
On account of the extreme complexity of the problem one can reach a satisfying solution probably only if one approaches the final goal by a series of simple models in clearly defined controlled environments.
In the beginning would it furthermore be helpful to work in parallel: building models with neuronal architectures as well as those with non-neuronal architectures to control models of the one kind by models of the other kind.
These considerations lead us to the definition of a first scenario which we describe next.
As starting point for the first scenario we select the following one:
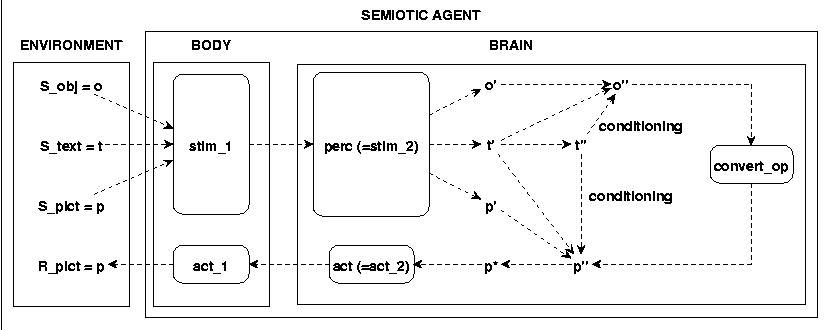
Fig.14 STARTING POINT FOR A FIRST SCENARIO
The environment provides as stimuli events some objects o, pictures p, and as sign vehicles some texts t. These stimuli are transformed by the body in a way which enables the brain to perceive these stimuli as stimuli events o', p', and t'. By some form of conditioning the text events are connected to the abstract structures o'' of the perceived objects. Optionally this can also be done for the perceived pictures p'. The critical process is now the assumed conversion from the conditioned meaning o'' of the texts into the abstract structures p'' of the pictures. These abstract picture structures p'' can then be transformed into concrete 'picturing activities' p* which in turn are producing e.g. painting activities.
This starting scenario is still very complex. I have reduced it to the following one:
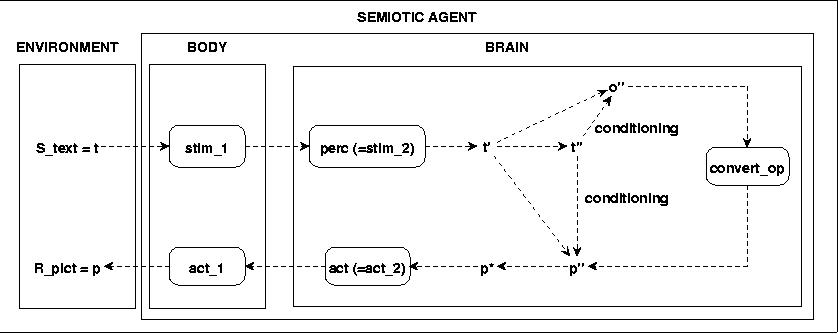
Fig.15 SIMPLIFIED STARTING POINT FOR A FIRST SCENARIO
In the simplified version has the variety of environmental stimuli been reduced to text events t. This raises the question how it is possible to generate the abstract structures o'' of the objects and the abstract structures p'' of the pictures? Indeed it would be much more interesting to have from the start a possibility to experiment with the conditioning of texts by real object perception. The author himself has done first experiments with such 'self-learning processes regarding the chains o -> o' -> o'' connected to t -> t' -> t'' by conditioning t'' <-> o'' in 1995 [1]. Very recently has been a similar experiment been reported by L.Steels in [16]. But as one will see in the following the complexity is already in this reduced version extremely high. Leaving out the dynamical generation of abstract object and picture structures by perception we have to provide these abstract structures as given structures based on some explicit assumptions. Later on we have to incorporate the dynamic generation of these abstract structures again.
The next decision which has been made is to start with non-neuronal structures to set up a test case and then, in a next step, to build several neuronal structures to compare the neuronal structures against the non-neuronal test case. The report about the neuronal structures will be the topic of another paper. The author has developed 1998-2001 a new mathematical model of 'real neurons' which will be used in one of the experimental neuronal structures (for a short description of the early version of this new type of a neuron see [3]).
The concrete scenario No.1 has the following format: Text stimuli t are ordinary texts in German. These are read and tokenized into a series of Tokens which represent the perceived text t'. The abstract structures of the perceived text t'' are realized as a LEXICON [LEX] and a GRAMMAR [GR]. The abstract structures of the objects o'' are realized as some kind of a SEMANTIC NET [SN] which is constructed based on explicit assumptions. The abstract structures of the pictures p'' are realized as a PICTURE INTERFACE [PINT] consisting of a structured text, which in this scenario is also based on explicit assumptions. The transformation of the PICTURE INTERFACE into the concrete structures p* which drive a GRAPHIC ENGINE is done by another parser which is strictly speaking not essential for the conversion from o'' to p''; thus we will for this scenario use any graphical representation which is available.
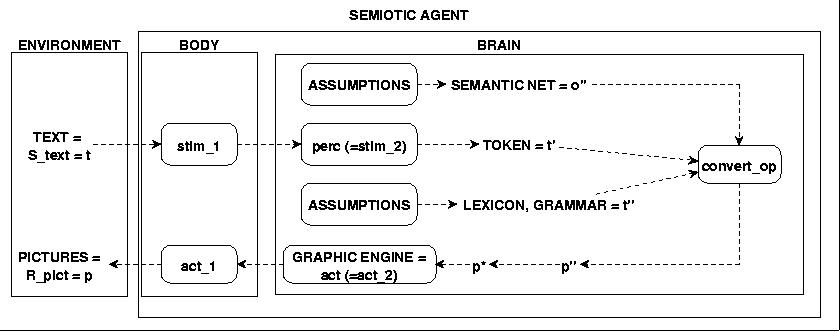
Fig.16 THE FIRST REAL SCENARIO
What will be shown next are concrete examples of a first PICTURE INTERFACE, some SEMANTIC NET, a LEXICON and a GRAMMAR, and a first Lexical-Grammar-Semantical-PARSER which is able really to transform ordinary texts into pictures.
Actually there are not enough empirical data available to say what kind of structures correspond to our term 'abstract picture structure o'' ' in the 'real' brain. But what we can do is to collect some data about attributes we know, which are necessary to realize concrete pictures.
We make the following assumptions:
To realize a sequence of pictures we need information about the START and the END of a picture in the sequence. We will call something with a START and end END a FRAME.
To place some OBJECT in a FRAME we need a DESCRIPTION of the OBJECT: Names, Attributes, Operations.
To realize some SPATIAL RELATIONS between objects we need specific information about such relations.
To realize these assumptions we choose as data format an XML-document which mimics the structure of UML-classes or UML-objects enhanced with informations about relations and frames (for UML see [14]).
A class (or an object) in UML has basically three 'compartments':

Fig.17 UML CLASS DIAGRAM STRUCTURE
We can transform all these informations in the following XML-format:
<FRAME> ... <REL-NAME name="xyz" > <CLASS name="abcdefg" class="hijklm [, hijklm]" ATTRIBUTLIST OPERATIONLIST > </CLASS> </OBJ name="abcdefg" class="hijklm [, hijklm]" ATTRIBUTLIST OPERATIONLIST > </OBJ> </REL-NAME> ... </FRAME> ... <FRAME> ... </FRAME>
Frames are ordered in the way they have to appear in time. Within a frame there are space-object building blocks headed by spatial relations. Arguments of spatial relations are again space-object building blocks with spatial relations or space-object building blocks without spatial relations. A space-object building block without spatial relations consists of CLASS- or OBJ-units.
A CLASS- or OBJ-unit consists of a set of features which are partially ordered:
NAME: name="..."; the name of this object which corresponds to some lexical entry in some language.
CLASS: class=..."; the class to which this class or (object) belongs to in some semantical network.
ATTRIBUTES: Open list of attributes. For the visualization we will suppose at least the following special VISUALIZATION ATTRIBUTES: picture_type with values in {file, label} and picture_content with values in {keywords, labels}. This allows a much more detailed communication with the visualization unit. Using picture_type="file" with picture_content="...some keywords..." tells the visualization unit to open this file for geometric data and some additional parameters. Using picture_type="label" with picture_content="...some text..." tells the visualization unit not to visualize a concrete object but an abstract object, which is represented by the given text.
OPERATIONS: Open list of operations. This list can be used to parameterize the visualization process with additional parameters.
To determine the list of necessary spatial relations we are following the everyday experience of an observer in an environment. As the following diagram illustrates is an everyday observer embedded in a quasi Euclidean Space 'in front' of an ensemble of objects 'arranged' in space.
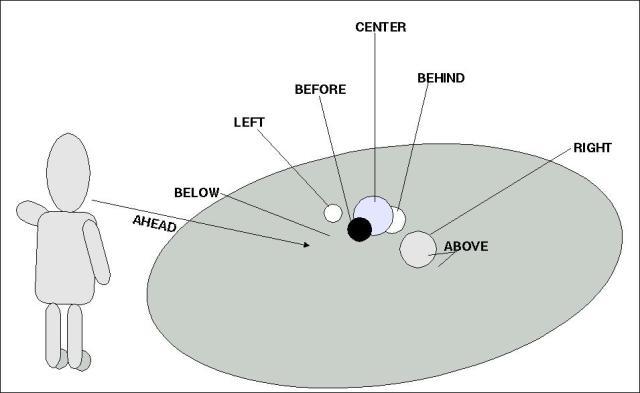
Fig.18 OBSERVER SPACE
This 'everyday experience of objects in space' is also reflected in everyday language. Thus what we will do is to collect an -possible open- list of spatial relations as they can be found in the ordinary language.
The formal structure of the spatial relations is the following:
If R is a spatial relation then it holds:
R C OBJUNITSn with n in [1,k] and OBJUNITS = {CLASSUNIT, OBJUNIT, SETUNIT}
<R> ... <OBJUNIT>...</R>
CLASSUNIT is <CLASS ...></CLASS>
OBJUNIT is <OBJ ...></OBJ>
SETUNIT is <SET [number={n, 'some', 'many'}]> OBJUNITS </SET>
<R> ... <OBJUNIT>...</R> in OBJUNITS
In the case of the SETUNITS we allow some quantifier-like feature 'number="..."'. Besides the possibility to generate enumerating sets one can use this feature to tell the visualization unit to generate 'adequate sets' of objects; either a definite number k of units or an arbitrary number of objects with 'some' and 'many'.
A first list of relations is the following one:
{ ABOVE(a,b), ASSOC(a,b), AT(a,b), BEFORE(a,b), BEHIND(a,b),
BELONGS_TO()a,b), CENTER(a), IN(a,b), ISA(a,b), LEFT(a,b), ON(a,b),
PARTOF(a,b), RIGHT(a,b), UNDER(a,b) }
The CENTER-relation is a special relation insofar it only tells that the unit a is perceived by the observer in the 'center' of the observed space. What this does 'really' mean has the visualization unit to decide.
Important is furthermore that these requirements for a Picture Language do not include any kind of activity. This is a consequence of the underlying assumption that any kind of activity is either static (e.g. 'the picture is attached at the wall') or dynamic; in the last case the activity introduces a change of the situation which has to be 'discretized' into a number of intermediate static states which together represent the change. Thus it will be the task of the Lexical-Grammatical-Semantical-Parse process to translate Activities in an appropriate series of static states.
With this assumptions we will now show a first conversion process from texts into pictures. Part of the new approach will be a semantical network with a new type of Lexical-Grammatical-Semantical-Parser [LGS-Parser].
We will start the construction of the Lexical-Grammatical-Semantical-Parser [LGS-Parser] and the Semantical Net [SN] needed for the task with a collection of requirements which have to be met.
ILLFORMED TEXTINPUT: The first requirement is induced by the fact that the text input is not assumed to be always 'syntactically correct' and that the parser has to cope with such a situation.
INCOMPLETE WORLD KNOWLEDGE: One can not assume that the world knowledge which is accessible to the parser is complete; the 'usual' case will be that of incomplete knowledge.
CHANGING ENVIRONMENT: The presupposed environment is assumed to be a changing one; everything can change during the course of time.
SPEECH INPUT: The actual version of the picture compiler is dealing with text input. But future version shall also deal with speech input. In the actual version can this be 'simulated' by the text output of a speech recognizer.
These requirements are also in agreement with the experience of one of the biggest speech-project of the past 10 years, the Verbmobil-Project (cf. [18]). As it is pointed out in [9] there is no alternative to a robust chunk parser if the input can not be assumed to be in a canonical form. The key idea of such a robust chunk parser is a two tier architecture: (i) The basic processing is done by regular grammars working in a cascading form; (ii) the post-processing is working on this output to produce more complete trees. But the main point is, that any unsolved problem on any of these levels does not stop the whole process; the parser is working to the end and passes all 'unrecognized units' 'as is'.
The Semantic Construction in the Verbmobile Project is also constructed according the principles of a robust parsing (cf. [15]). But compared to the Picture Compiler intended in this paper ist the syntactical-semantical parsing in the Verbmobile Project not in parallel but sequential! In Verbmobile semantical construction begins when syntactical parsing ends.
As one can see through the example of the Verbmobile Project is the main problem to find a strategy to cope with the complexity without having all information. A tentative answer to this challenge has the following elements:
ISLANDS OF CERTAINTY: Take any piece of input as 'isolated' information and collect all information available for this piece.
CASCADING INDUCTIVE PROCESSING: Continue stepwise processing by elaborating possible connections between the Island of Certainty
MIXING SYNTAX AND SEMANTICS: We postulate an interrelationship between syntactical and semantical structures which forces a quasi parallel processing of syntactical and semantical parsing.
EVOLUTIONARY DEVELOPMENT: The strategy will develop a network of modules which will handle more and more information while passing unresolved pieces of information through without changes.
As general these assumptions may appear, they already are inducing strong constraints for the parsing approach intended in this paper. As the digram below shows are the islands of certainty recruited from the text input itself as well from three sources of knowledge: from a lexicon, from a grammar for syntactical rules, and from a semantical network. Already on this level we have a simultaneity of syntactical and semantical information. Starting from these initial informations will several parse cycles be organized which exploit these information and try to widen the scope of any piece of information in a 'vertical' and in a 'horizontal' direction. Every level of this cascading parsing processes as such is a simple automaton. In an optimal parse all the initial pieces of information are completely integrated in a final structure. But this is 'usually' not the case; the more probable case is such that some of the initial pieces of information are left unsolved; these will be 'passed through as is'.
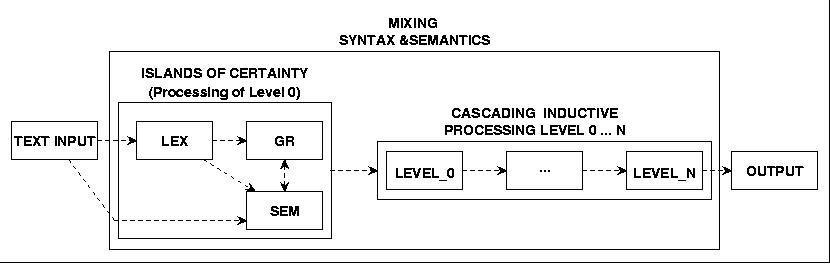
Fig.25 OUTLINE FOR A ROBUST SYNTACTICAL-SEMANTICAL PARSER
To understand this parsing architecture more fully one has to consider the general layout of the data which we will assume as 'implicitly given' in this whole process. These following assumptions are not to understand as a 'dogmatic setting' but as a 'working hypothesis' which has to be refined during the forthcoming results.
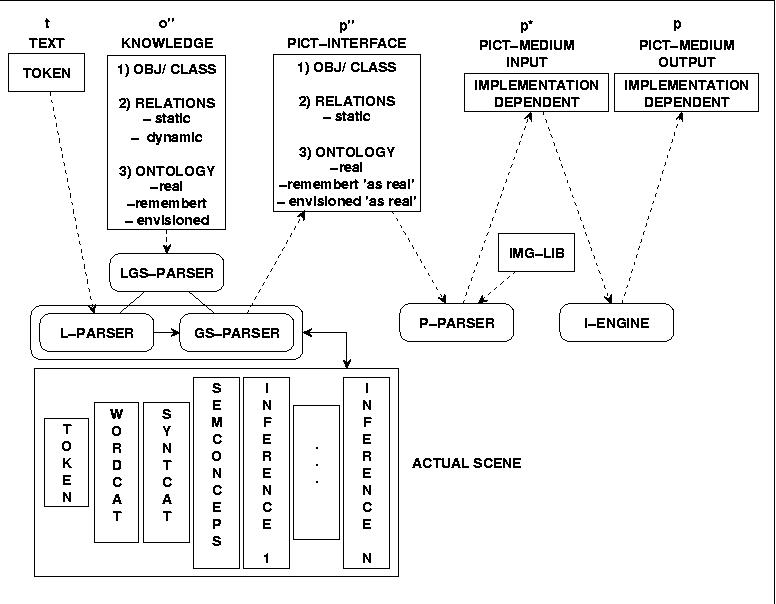
Fig.26 DATA TYPE MAP FOR PICTURE COMPILER
We are not so much interested in the final processes of turning the Picture Interface data into some real image. Although this process is as such endowed with its own complexity and offers a lot interesting topics we want to concentrate here on the process from the text input to the picture interface data.
The structure of the Picture Interface we have describe in a chapter above. From this one knows that in the Picture Interface there are only three kinds of information available: (i) Objects and Classes with their attributes and Operations; (ii) Static Relations between these Objects and Classes; (iii) and one level of ontological status: the reality of the picture as such. 'Past' or 'envisioned' things are encoded in the reality of the picture presence.
The structure of the Knowledge Data isn't yet defined. We will assume that the following kind of data have to be given in the Knowledge Base (= Semantical Net):
OBJ/CLASSES with their attributes and possible operations
RELATIONS static as well as dynamic ones. (Dynamic relations are activities, which change the status of an object or a class).
ONTOLOGY in the modes 'real', 'remembered' and 'envisioned'.
As one can see is the Picture Interface compared to the Knowledge Interface a reduced form; the picture interface is completely static whereas the Knowledge Interface 'in some way' encodes changes, activities.
The Lexical-Grammatical-Semantical-Parser has to 'interprete' the token of the input text in the light of a Grammar and a Knowledge Base in a way that we will get 'sequences of static structures' 'out of it' in the format of the Picture Interface.
But because you can only 'get out some X of Y' if this X is somehow 'contained' in Y (or in a reachable context of Y), all these needed information have to be encoded in the knowledge structure from 'somewhere'.
This is a very big task and the ongoing project is only in the beginning. Because we have just started the experiments with this LGS-Parsing Process at the time of this writing I can not give a satisfying report now. At the time of the workshop in October 2002 there will be some more results available.
8. Elemente des folgenden experimentellen LSG-Parsers
Es werden jetzt die einzelnen Komponenten des folgenden Experimentes einzeln vorgestellt und dann ein erstes Experiment durchgeführt.
Logisch könnte man sich den LSG-Parser z.B. als eine Klasse vorstellen, die die mit der Umgebung (Texte, PINT, Lexikon, Grammatik, semantisches Netz) über ein spezielles Interface kommuniziert. Aus der Umgebung werden die Daten zu den Texten, dem Lexikon, dem semantischen Netzt und der Grammatik übernommen. Intern wird ein dynamisches working Memory verwaltet, ebenso dynamische Varianten der eingelesenen Lexika, semantischen Netze und Grammatiken. Hier wird angenommen, dass diese internen Elemente selbst wieder als Klassen realisiert sind, die mit der Hauptklasse lsg_parser über Schnittstellen kommunizieren. Basisoperationen wären das Lesen und Schreiben von Daten, das Einfügen und Löschen von Elementen sowie das Suchen bestimmter Elemente. Ferner wird angenommen, dass die 'offene' Menge von elementaren Lsg-pParser-Operationen spezielle Unterklassen bilden.
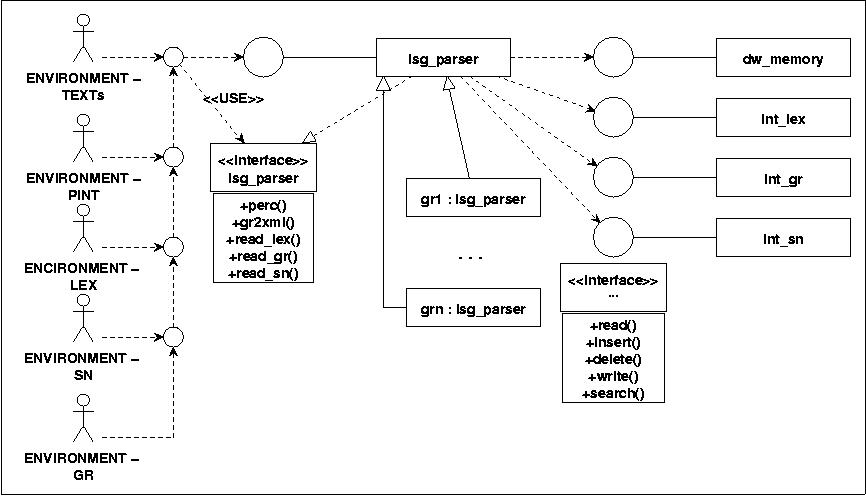
8.1 Das Testcorpus 'knowbot0b.txt
'
/fh/KNOWBOTS2/K2-TH/TOOLS/PARSE2 > cat knowbot0b.txt Hans ist klein und hat dunkle Haare. Er ist Schüler der dritten Klasse. Er betritt seine Klasse. Links an der Stirnseite hängt eine weisse Tafel an der Wand. Vor ihm steht das braune Pult des Lehrers. Rechts sind die Bänke für die Schüler. Er geht in die dritte Reihe und setzt sich auf seinen Platz an dem Fenster.
A possible translation could be:
Hans is small and has dark hairs. He is a third-year student. He enters his classroom. Left, at the facing wall is a Whiteboard attached to the wall. Before him stands the brown desk of the teacher. To the Right are the banks of the students. He walks to the third row and is sitting down on his seat at the window.
8.2 Einen einfachen 'Text-Normalisierer' parse0.sh
Mit einem sehr einfachen 'Präprozessor' parse0.sh wird der Eingabetext in eine Sequenz von 'normalisierten Token' umgeformt:
#! /bin/bash
#
# parse0.sh
#
# Takes a text T with filename as first argument
# Squeezes all blanks to one newline '\n', thus tokenize the text one token per line
# Changes all capital letters to lower letters
# Replaces all occurences of german Umlaute {ä,ö,ü,ß} by {ae, oe, ue, ss}
# Replaces all 'strong' punctuation marks by 'BB' (Big Break) and the 'weak' ones by 'SB' (Small Break)
# Repetition of substituion of new blanks by newline (Putting substitution of Umlaute after Punctuations does not work...)
#
# CALL: mklex.sh FILE
##########################################
cat $1 \
| tr -s '[:blank:]' '\n' \
| tr '[:upper:]' '[:lower:]' \
| sed 's/ä/ae/' \
| sed 's/ö/oe/' \
| sed 's/ü/ue/' \
| sed 's/ß/ss/' \
| sed 's/[\.;!?]/ BB/' \
| sed 's/,/ SB/' \
| tr -s '[:blank:]' '\n'
Angewendet auf unseren Text ergibt sich:
fh/KNOWBOTS2/K2-TH/TOOLS/PARSE2 > parse0.sh knowbot0b.txt hans ist klein und hat dunkle haare BB er ist schueler der dritten klasse BB er betritt seine klasse BB links an der stirnseite haengt eine weisse tafel an der wand BB vor ihm steht das braune pult des lehrers BB rechts sind die baenke fuer die schueler BB er geht in die dritte reihe und setzt sich auf seinen platz an dem fenster BB
8.3 A Tag-Set for Word Categories called 'fhffm.txt
The following list of Word Categories 'fhffm.txt' has been used (cf. also the TTS-Projects using CELEX, BOMP and IMS-Festival):
/fh/KNOWBOTS2/K2-TH/TOOLS/PARSE2 > cat fhffm.txt AUX ; Hilfsverben ADJ ; Adjektiv ART ; Artikel ARTP ; Artikel mit Besitzanzeige (possesiv) ADV ; Adverbien CARD ; Numeralia (aber auch AD~ z.B. bei Ordinalzahlen) CN ; Substantiva CON ; Konjunktionen ITJ ; Interjektionen NEG ; Negation und Affirmation (mit Vorsicht zu geniessen: auch 'ja', 'jawohl', 'danke' sind NEG) N ; Nomina POSPREP ; Possesiv-Präpositionen (Präposition zum anzeigen eines Zugehörigkeitsverhältnisses) PREP ; Präpositionen POSPR ; Possesivpronomen PPR ; Personalpronomen PR ; Pronomina RPR ; Reflexifpronomen V ; Verben
Für die Zwecke des Bildcompilers ist dieser Tag-Set unzureichend! Um nämlich später die Eigenschaften als Attributwerte der Objekte bzw. Klassen im Rahmen der Objektrepräsentation 'automatisch' übernehmen zu können, muss schon an dieser Stelle für die Adjektive eine zusätzliche Information eingeführt werden. Notwendig ist eine Kenntlichmachung von unterschiedlichen Eigenschaftsklassen wie z.B. 'COLOR', 'SIZE' etc. so dass dann z.B. ein Adjektiv wie 'weiss' als konkreter Wert z.B. der Eigenschaftsklasse 'COLOR' übernommen werden kann (etwa COLOR="weiss"). Wir werden diese zusätzlichen Informationen im Lexikon eintragen.
The Word Categories have to be inserted 'by hand' based on 'linguistic knowledge' to define a Lexicon. The Word Categories are partially 'enlarged' by 'features' like 'COLOR', 'SIZE' etc. The following Lexicon has been compiled: 'lex0_ab.txt':
fh/KNOWBOTS2/K2-TH/TOOLS/PARSE2 > cat lex0_ab.txt TOKEN WCAT FEATURE_1 ... FEATURE_n OCCURENCES --------------------------------------------------------------- BB BB 6 an PREP 3 auf PREP 1 baenke CN 1 betritt V 1 braune ADJ COLOR 1 das ART 2 dem ART 1 der ART 2 der ARTP 1 des ARTP 1 die ART 3 dritte CARD 1 dritten CARD 1 dunkle ADJ COLOR 1 eine ART 1 er PPR 2 fenster CN 1 fuer POSPREP 1 geht V 1 haare CN 1 haengt V 1 hans N 1 hat AUX 1 ihm PPR 1 in PREP 1 ist AUX 1 klasse CN 2 klein ADJ SIZE 1 lehrers CN 1 links ADV 1 platz CN 1 pult CN 1 rechts ADV 1 reihe CN 1 schueler CN 2 seine POSP 1 seinen POSP 1 setzt V 1 sich RPR 1 sind AUX 1 steht V 1 stirnseite CN 1 tafel CN 1 und CON 1 vor PREP 1 wand CN 1 weisse ADJ COLOR 1
Man erkennt, dass es im Lexikon Token mit Mehrfachnennungen gibt, die unterschiedliche Wortkategorien besitzen. Dies bedeutet, dass bei der nachfolgenden Verarbeitung mit Alternativen gearbeitet werden muss. Ferner kann jede Wortklasse WCAT durch zusätzliche FEATURE ergänzt werden. Typische weitere FEATURE wären z.B. 'GENDER' {m,f,n}, 'NUMBER' {sgl, pl} und 'PERSON' {1,2,3}. Formal werden die Feature als zusätzliche Eigenschaften einer Wortart WCAT aufgefasst, d.h. eine Wortklasse wird als Vektor aufgefasst, dessen erstes Element (='head') die eigentliche Wortklasse ist und deren weitere Elemente ('tail') zusätzliche Merkmale darstellen. Man könnte also auch von einer Klasse mit Subklassenspezifikation sprechen, deren Wert das jeweilige Wort-Token ist. '(weiss, <ADJ, COLOR>)' wäre also die subspezifizierte Wortklasse 'ADJ' mit Zusatzmerkmal 'COLOR' und dem Wert 'weiss', oder '(er, <PPR, 3.PERS, SGL,M>)'
8.5 The Semantical Net 'SN1.xml'
Presupposing the theoretical background introduced above we assume a few basic ontological modes for semantical concepts.
Der ontologische Status REAL wird dann mit den aktuell wahrgenommenen Entitäten und den damit assoziierten abstrakten Strukturen assoziiert. Der ontologische Status ERINNERBAR wird mit dem gesamten semantischen Netz assoziiert. Der ontologische Status VORSTELLBAR wird in diesem Experiment noch nicht betrachtet. Vereinfachend kann also gesagt werden: 'erinnerbar' ist nur etwas in diesem Modell, was schon einmal 'wahrgenommen' worden ist. Die Wahrnehmung ('perception') ist also die die notwendige Vorstufe der 'Erinnerung' ('memory'). Allerdings wird in diesem Experiment der Übergang von der Wahrnehmung zur Erinnerung noch nicht modelliert. Es wird nur das 'Ergebnis' einer Wahrnehmung durch Setzen von bestimmten semantischen Strukturen 'simuliert'.
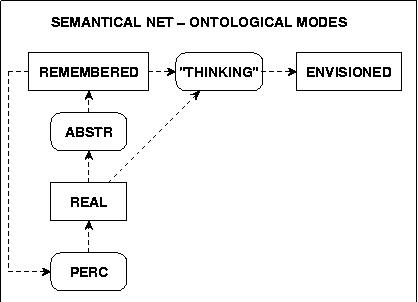
Independent of the ontological modes will the following TAGs be assumed to represent the occurences of objects in space:
OBJ [SN-O]: Any kind of concrete stuff (e.g. the concrete person 'hans')
CLASS [SN-O]: Any kind of concept, for which exist concrete objects as elements (e.g. is the concrete person 'hans' an element of the abstract class 'human').
SREL [SN-SR]: Spatial Relation. Spatial Relations are considered 'primary' compared to non-spatial relations.
REL [SN-R] Non-spatial Relations. Examples of Non-spatial Relations are 'isa'-Relations (hans is a student) or the 'belongs_to'-Relation ('the desktop of the theacher').
ACTIVITY [SN-A] Activities are either 'static' or 'dynamic'. If 'static' they don't change the local structure of space ('the picture hangs on the wall'). If 'dynamic' they change the structure of space in a certain interval of time ('hans sits down on hies chair').
Zum Verhältnis dieser verschiedenen Kategorien untereinander wird im Rahmen des Bildcompiler Projektes davon ausgegangen, dass die Raumrelationen gegenüber den Nichträumlichen Relationen und den Aktivitäten primär sind. Damit ist gemeint, dass jede Aktivität ein Raumstruktur voraussetzt, auf die sie sich bezieht. Entweder beschreibt eine Aktivität eine Eigenschaft innerhalb einer bestimmten Raumstruktur oder aber den Vorgang einer Veränderung, bei der sich Teile des Raumes in einer bestimmten Weise von einem Ausgangszustand zu einem neuen Endzustand hin 'verändern'. Wesentlich bei allen Relationen und Aktivitäten ist, dass bezüglich der gleichen Objekte gleichzeitig mehrere Relationen unterschiedlichen Typs sowie Aktivitäten bestehen könne.
Zum Verhältnis zwischen Objekten und Klassen gilt, dass bei 'Simulation' einer Wahrnehmung für ein gegebenes Objekt a die Bestimmung einer Klasse b nicht immer so einfach und eindeutig ist wie bei einer tatsächlichen Wahrnehmung. Bei einer 'tatsächlichen' Wahrnehmung ist jedes konkret vorkommende individuelle Objekt ein Objekt. Im Text werden solche individuellen Objekte 'in der Regel' durch individuell identifizierende Namen repräsentiert. Aber es können verschiedene individuelle Objekte den gleichen Namen haben oder das Objekt zum Namen existiert schon garnicht mehr. Die Gleichsetzung von Objekten mit individuellen Namen ist von daher eine Konvention. Entsprechend werden alle Token, die Bezug auf zuvor 'textlich eingeführte Objekte' nehmen, auch als 'Repräsentanten des gemeinten Objektes' angesehen.
Aus diesen Überlegungen folgt, dass die Einführung und Benutzungvon Objekten strenggenommen an den Bezug zu einer konkreten Welt gebunden ist, in der es konkrete identifizierbare Objekte gibt. Anders gesprochen, wenn man ein semantisches Netz aufbaut, in dem Objekte vorkommen, dann ist dies so zu interpretieren, dass der Weltausschnitt, der durch dieses semantische Netz repräsentiert werden soll, mindetens die konkreten Objekte enthalten sollte, die im semantischen Netz als Objekte vorkommen.
Eine weitere Komplikation im Umgang mit konkreten Objekte besteht darin, dass eben nicht immer -sogar in den seltentsten Fällen- für konkrete Objekte individuelle Namen eingeführt werden. Wenn es z.B. heisst, 'vorne steht das pult des lehrers' dann sind die Token 'pult' und 'lehrers' strenggenommen keine individuellen Namen von konkreten Objekten, sondern Namen von Klassen, die auf ein konkretes Objekt angewendet werden. Man müsste eigentlich umschreiben: 'vorne steht ein gegenstand, der ein pult ist, der einem anderen gegenstand gehört, der ein lehrer ist'.
Im alltäglichen Sprachgebrauch werden also offensichtlich Namen von Klassen zur Bezeichnung konkreter Gegenstände benutzt, als ob sie individuelle Namen dieser Gegenstände wären. Allerdings muss man in diesem Fall bei Token, die Klassen repräsentieren, einen Artikel vorsetzen, was bei 'echten' Namen nicht notwendig ist:
hans singt (N V). hans ist ein mensch (N AUX CN). der mensch singt (ART CN V).
Folgende semantische Konzepte wurden für die Interpretation des Testtextes angenommen (diese Konzepte enthalten keine expliziten Bildinformationen für die spätere Visualisierung. dies ist Aufgabe des Image-Parsers):
//************************************************************
// SN1
//************************************************************
<SREL name="AT" token={(german,{an})} args="(a,b)" syntLR="NP - NP" or "- NP V NP">
</SREL>
<SREL name="BEFORE" token={(german,{vor})} args="(b,a)" syntLR="- NP V NP" </SREL>
<SREL name="in" token={(german,{in})} args="(a,b)" synLR="NP V - NP" or "NP - NP">
</SREL>
<SREL name="LEFT_OF" token={(german,{links})} args="(a,b)" synLR="- last(OBJ) NP">
</SREL>
<SREL name="ON" token={(german,{auf})} args="(a,b)" synLR="NP V NP - NP[P]">
</SREL>
<SREL name="RIHT_OF" token={(german,{rechts})} args="(a,b)" synLR="- last(OBJ) NP">
</SREL>
//-------------------------------------------------------------------------------------------
<REL name="BELONGSTO" token={(german,{ARTP:der, ARTP:des })} args="(a,b)" synLR="NP - NP[P]" or "N V - CN">
</REL>
<REL name="BELONGSTO" token={(german,{POSP:sein[e]})} args="(b,a)" synLR="NP PREP - CN">
</REL>
<REL name="BELONGSTO" token={(german,{POSPREP: fuer})} args="(b,a)" synLR="NP - NP">
</REL>
<REL name="HAVE" token={(german,{hat,haben})} args="(a,b)" synLR="(S,NP) (W,AUX) (S,NP)">
</REL>
<REL name="HAVE" token={(german,{ist, sind})} args="(a,b)" synLR="NP+num - ADJ+num">
</REL>
<REL name="ISA" token={(german,{ist, sind})} args="(a,b)" synLR="~ADV NP+num - NP+num ~ADV">
</REL>
//-------------------------------------------------------------------------------------------
<ACTIVITY name="be" token={(german,{ist, sind)} args="(a)" syntLR="ADV NP - NP" or "NP - ADJ" >
</ACTIVITY>
<ACTIVITY name="enter" token={(german,{[ein | be]treten})} args="(a,b)" syntLR="NP - NP" >
</ACTIVITY>
<ACTIVITY name="go" token={(german,{geh[t | en]})} args="(a)" synL="NP - " >
</ACTIVITY>
<ACTIVITY name="hang" token={(german,{haeng[t |en]}}} args="(a,b)" syntLR="NP -" "- NP" >
</ACTIVITY>
<ACTIVITY name="sit" token={(german,{setz[t | st | en]}}} args="(a)" synR="NP - RPR" >
</ACTIVITY>
<ACTIVITY name="stay" token={(german,{steh[t | en]}}} args="(a)" syntLR="- NP" or "NP -">
</ACTIVITY>
//-------------------------------------------------------------------------------------------
<CLASS name="bench" token={(german, {bank})} class="furniture" >
</CLASS>
<CLASS name="board" token={(german, {board, tafel})} class="non-living object" >
</CLASS>
<CLASS name="body" token={(german, {koerper})} class="living object" >
</CLASS>
<CLASS name="classroom" token={(german, {klasse, klassenraum})} class="room" >
</CLASS>
<CLASS name="furniture" token={(german, {moebel})} class="non-living object" >
</CLASS>
<CLASS name="desk" token={(german, {pult, arbeitstisch, schreibtisch})} class="furniture" >
</CLASS>
<CLASS name="hair" token={(german, {haare})} class="body" >
</CLASS>
<OBJ name="hans" class="student" ></OBJ>
<OBJ name="headwall" token={(german, {stirnseite})} class="wall" >
</OBJ>
<CLASS name="human" token={(german, {mensch})} class="living object" >
</CLASS>
<CLASS name="living object" token={(german, {belebtes Objekt, beseeltes objekt}})} class="object" >
</CLASS>
<CLASS name="location" token={(german, {ort})} class="space" >
</CLASS>
<CLASS name="non-living object" token={(german, {nicht belebtes Objekt, totes Objekt, unbeseeltes objekt}})} class="object" >
</CLASS>
<CLASS name="object" token={(german, {objekt, gegenstand, ding})} class="root" >
</CLASS>
<CLASS name="opening" token={(german,{oeffnung} )} class="space" >
</CLASS>
<OBJ name="place" token={(german, {platz})} class="location" >
</OBJ>
<CLASS name="row" token={(german, {reihe})} class="space" >
</CLASS>OBJ
<CLASS name="room" token={(german, {raum})} class="space" >
</CLASS>
<CLASS name="space" token={(german, {raum})} class="root" >
</CLASS>
<CLASS name="student" token={(german, {schueler, student})} class="human, year" >
</CLASS>
<CLASS name="year" token={(german,{jahr, klasse} )} class="human, year" number=CARD >
</CLASS>
<CLASS name="wall" token={(german,{wand} )} class="non-living object" ptype="file" pcontent="wall0" >
</CLASS>
<CLASS name="window" token={(german,{fenster} )} class="opening" >
</CLASS>
Üblicherweise verteht man unter einer (formalen) Grammatik eine Menge von Ersetzungsregeln, die über einer Folge von Symbolen operieren. Diese Annahme trifft auf die vorliegende Situation nur unvollständig zu! Nach den bisherigen Analysen muss davon ausgegangen werden, dass die zu bearbeitenden Daten in einer Art dynamischen Matrix angeordnet sind (siehe Schaubild).
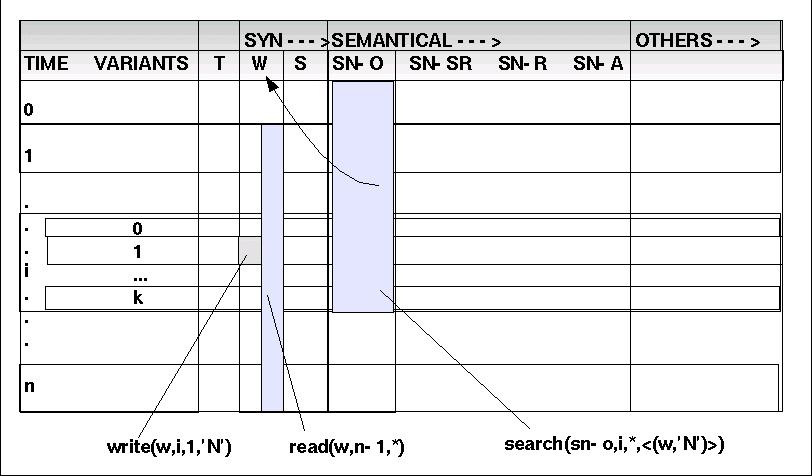
Die Spalten ('columnes'), auch 'Dimensionen' genannt, werden durch die unterschiedlichen Datentypen (Kategorien) gebildet, die Zeilen ('rows') durch Zeitpunkte. D.h. zu einem Zeitpunkt t=i kann es in jeder Spalte ein korrelierendes Ereignis geben bzw. ein solches Ereignis kann durch Anwendung einer grammatischen Regel erzeugt werden.
Die Menge der Dimensionen lässt sich grob unterteilen in syntaktische, semantische und andere Kategorien. Ferner ist im Bereich der Zeitpunkte anzunehmen, das zum gleichen Zeitpunkt mehr als eine Variante möglich ist. Daher kann jeder Zeitpunkt nochmals weiter unterteilt sein.
Um über die 'Objekte' solch einer dynamischen Datenmatrix präzise reden zu können, werden einige neue Begriffe eingeführt.
Drei Basisfunktionen werden angenommen:
LESEN: Man muss beliebige Zellen der Marix lesen können. Dazu dient die Funktion 'read(d,i,j)'. Zum i-ten Zeitpunkt soll die k-te Variante aus der Dimension d gelesen werden. Jede Dimension hat ihr eigenes Datenformat. Es wird nur angenommen, dass in jeder Zelle immer ein Element des Datenformats steht. Man kann auch einen ganzen Block lesen mit 'read(d,(i1,*),(i',*))': Lese in Dimension d von Zeitpunkt i1 bis i2 alle Elemente. '*' bedeutet hier, dass alle Varianten jeweils mit durchlaufen werden sollen.
SCHREIBEN: Umgekehrt zum Lesen muss man auch jede Zelle der Matrix schreiben können: 'write(d,i,j,c)'. Zum i-ten Zeitpunkt soll in Variante j der Dimension d der Wert c geschrieben werden. 'c' muss ein gültiges Element der Kategorie d sein. Weiter sollte es möglich sein, einen ganzen Block zu schreiben mit 'write(d,(i1,j1),(i2,j2), c)': der Wert c wird in alle Zellen von (i1,j1) bis (i2,j2) geschrieben.
SUCHEN: Es muss möglich sein, in der 'History' eines Elementes in einer Spalte alle die Elemente zu suchen, die in anderen Spalten bestimmte Eigenschaften besitzen: 'search(d1,i,j,<(d2_1,c_1), ..., (d2_k,c_k)>)': Suche dasjenige Element in Dimension d1 von Zeitpunkt i Vartiante j ab rückwärts, das in der Dimension d2_1 den Wert c_1 hat, ..., und in Dimension d2_k den Wert c_k.
ERSETZEN: Es muss möglich sein, in der Zeichenkette eines Objektes der Dimension SN-O an einer bestimmten Stelle ein bestimmtes Zeichenmuster ('pattern') P1 durch ein neues Zeichenmuster P2 zu ersetzen: 'subst(o,P1,P2)'. Ist das zeichenmuster P1 noch nicht vorhanden, dann wird es neu eingesetzt (Problem der Lokalisierung: wo).
Mit Hilfe dieser Vereinbarungen sind nun die eigentlichen grammatischen Regeln neu zu definieren.
Die Regelanwendung ist ein zyklisches Geschehen: innerhalb eines Arbeitszyklus des Systems werden eine Reihe von Operationen nacheinander ausgeführt.
(1) perc: TEXT ---> TOKEN
perc parses a text and tokenizes the text in partial sequences of n units.
Jeder Zyklus wird dadurch eröffnt, dass mittels der Operation 'perc' ('perception') n-viele neue Token-Elemente aus einer Textquelle eingelsen und 'am Ende' der dynamischen Matrix in der Dimension 'T' ('TOKEN') angefügt werden. Mit jedem Token wird der Index der Zeitpunkte um 1 erhöht (siehe Schaubild).
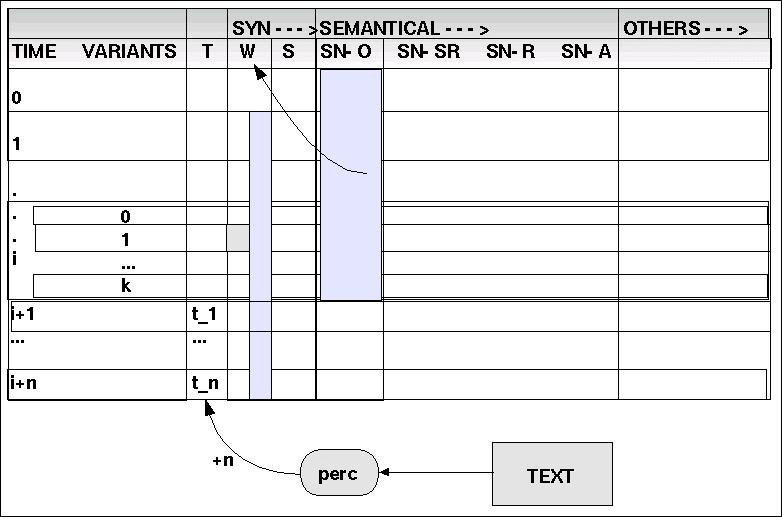
| TOKEN | WCAT | SCAT | OBJ/CLASS | SN-SR | SN-R | SN-ACT |
| hans | ||||||
| ist | ||||||
| klein | ||||||
| und | ||||||
| hat | ||||||
| dunkle | ||||||
| haare | ||||||
| BB |
(2) lex: TOKEN ---> WCAT
lex maps the tokens into word categories WCAT
Jedes Word-Token, das neu in die Dimension T geladen wird, wird von der Operation lex() in die Menge der Wortklassen WCAT abgebildet. Der errechnete Wert aus WCAT wird in die Dimension W eingetragen. Dabei kann es vorkommen, das ein und dasselbe Token t mehreren Wortkategorien zugeordnet werden kann. In diesem Fall würde für jede Variante eine eigene 'Zeile' eingeführt.
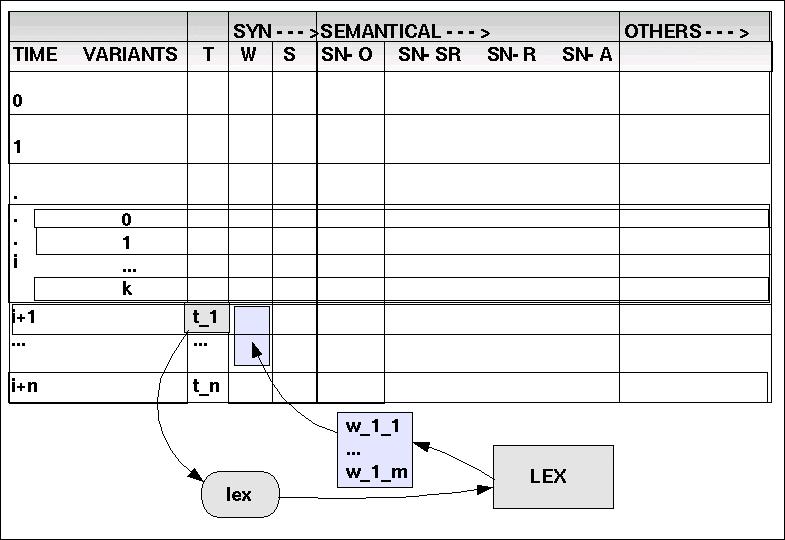
| TOKEN | WCAT | SCAT | OBJ/CLASS | SN-SR | SN-R | SN-ACT |
| hans | <N> | |||||
| ist | <AUX> | |||||
| klein | <ADJ, SIZE> | |||||
| und | <CON> | |||||
| hat | <AUX> | |||||
| dunkle | <ADJ, COLOR> | |||||
| haare | <CN> | |||||
| BB | <BB> |
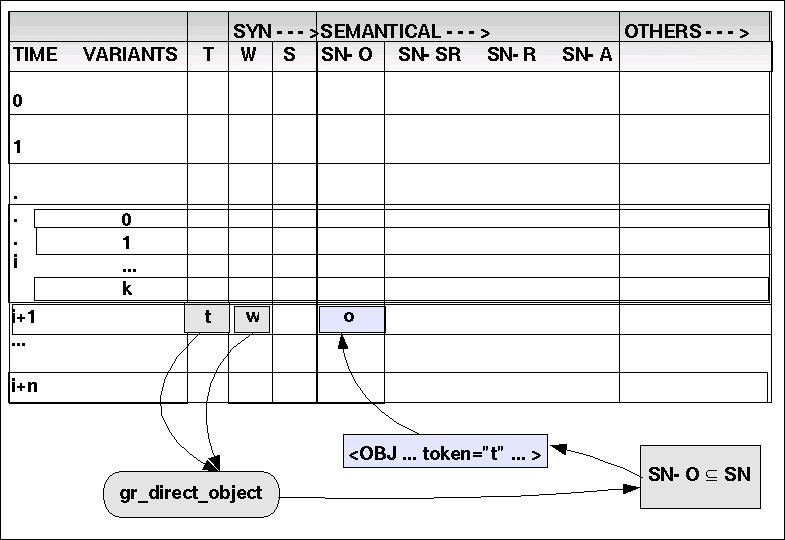
(3) gr_direct_object: {N, CN, BB } x TOKEN ---> SN-O
gr_direct_object maps pairs of (N,t), (CN,t) und (BB,t) of word categories together with an indexing token into the set of OBJs and CLASSes as they are represented as a subset in the semantical net SN.
Sei i der aktuelle Zeitpunkt.
Mittels read(T,i,j) und read(W,i,j) wird geprüft, ob ein Paar (<N>,t) vorliegt. Falls ja, wird mittels 'search()' eine Anfrage an das semantische Netz gestartet, ob es ein Objekt '<OBJ ... >' oder eine Klasse '<CLASS ... >' gibt, deren token-Attribut mit dem Token 't' übereinstimmt. Falls ja, dann wird dieses Objekt o komplett aus dem semantischen Netz übernommen und mittels 'write(SN-O,i,j,o)' eingetragen. Wird kein Objekt mit einem passenden Token-Attribut gefunden, dann ist die Datenbasis unvollständig und es muss ein Dummy-Objekt eingetragen werden. Liegt garkein Paar (<N>,t) vor, wird der nächste Fall geprüft.
Mittels read(T,i,j) und read(W,i,j) wird geprüft, ob ein Paar (<CN>,t) vorliegt. Falls ja, wird mittels 'search()' eine Anfrage an das semantische Netz gestartet, ob es ein Objekt '<OBJ ... >' oder eine Klasse '<CLASS ... >' gibt, deren token-Attribut mit dem Token 't' übereinstimmt. Falls ja, dann wird dieses Objekt o komplett aus dem semantischen Netz übernommen und mittels 'write(SN-O,i,j,o)' eingetragen. Wird kein Objekt mit einem passenden Token-Attribut gefunden, dann ist die Datenbasis unvollständig und es muss ein Dummy-Objekt eingetragen werden. Liegt garkein Paar (<CN>,t) vor, wird der nächste Fall geprüft.
Mittels read(T,i,j) und read(W,i,j) wird geprüft, ob ein Paar (<BB>,t) vorliegt. Falls ja, wird mittels 'write(SN-O,i,j,</FRAME>)' eingetragen. Liegt kein Paar (<BB>,t) vor, wird der nächste Fall geprüft.
| TOKEN | WCAT | SCAT | OBJ/CLASS | SN-SR | SN-R | SN-ACT |
| hans | <N> | <OBJ name="hans" class="student" ></OBJ> | ||||
| ist | <AUX> | |||||
| klein | <ADJ, SIZE> | |||||
| und | <CON> | |||||
| hat | <AUX> | |||||
| dunkle | <ADJ, COLOR> | |||||
| haare | <CN> | <CLASS name="hair" token={(german, {haare})} class="body" > </CLASS> | ||||
| BB | <BB> | </FRAME> |
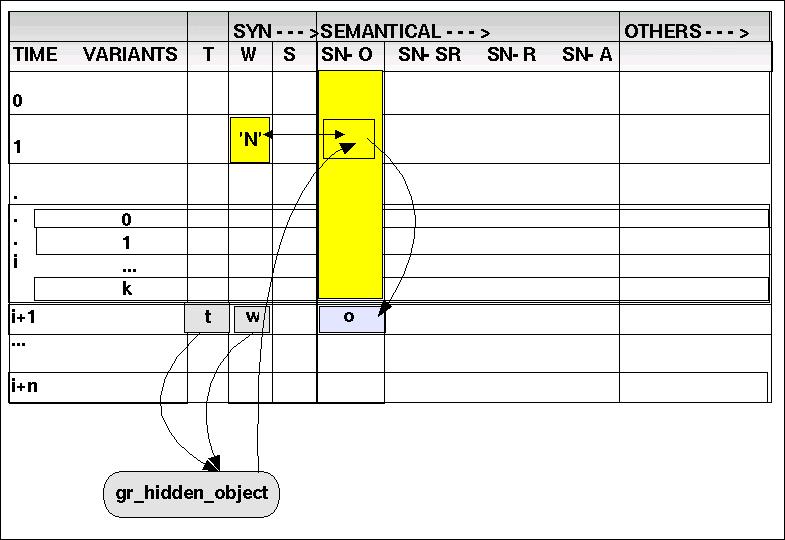
(4) gr_hidden_object: { PPR, RPR, CON } x TOKEN ---> SN-O
Wortkategorien wie 'PPR' und 'RPR' referrieren auf schon eingeführte Objekte vom Typ 'N' oder 'CN'. Das gleiche gilt auch für 'CON' wenn es direkt von einem Verbal-Komplex gefolgt wird.
Sei i der aktuelle Zeitpunkt.
Mittels read(T,i,j) und read(W,i,j) wird geprüft, ob ein Paar (<PPR>,t) vorliegt. Falls ja, wird mittels 'search(SN-O,i-1,*,<(W,'N')>)' eine Suche in der Dimension SN-O von Zeitpunkt i-1 abwärts (einschliesslich aller Varianten) gestartet, ob es ein Objekt gibt, das simultan in der Dimension W den Wert 'N' hat. Falls ja, dann wird dieses Objekt o kopiert und mittels 'write(SN-O,i,j,o)' in die Zeile eingetragen, in der die Wortklasse 'PPR' steht. Wird kein Objekt mit einem passenden Token-Attribut gefunden, dann wird die Suche mit 'search(SN-O,i-1,*,<(W,'CN')>)' wiederholt. Führt auch dies nicht zum Erfolg, dann ist die Datenbasis unvollständig; ein Dummy-Objekt ist zu erzeugen.
Mittels read(T,i,j) und read(W,i,j) wird geprüft, ob ein Paar (<RPR>,t) vorliegt. Falls ja, wird mittels 'search(SN-O,i-1,*,<(W,'N')>)' eine Suche in der Dimension SN-O von Zeitpunkt i-1 abwärts (einschliesslich aller Varianten) gestartet, ob es ein Objekt gibt, das simultan in der Dimension W den Wert 'N' hat. Falls ja, dann wird dieses Objekt o kopiert und mittels 'write(SN-O,i,j,o)' in die Zeile eingetragen, in der die Wortklasse 'RPR' steht. Wird kein Objekt mit einem passenden Token-Attribut gefunden, dann wird die Suche mit 'search(SN-O,i-1,*,<(W,'CN')>)' wiederholt. Führt auch dies nicht zum Erfolg, dann ist die Datenbasis unvollständig; ein Dummy-Objekt ist zu erzeugen.
Die Idee ist, bei 'CON' den Satz enden zu lassen, eine neue Zeile einzuführen, und mit der neuen Zeile den nächsten Satz beginnen zu lassen. Als Element wird in die neue Zeile das Objekt eingesetzt, auf das die Konjunktion indirekt verweist: Wenn read(W,i,j) == 'CON' & read(W,i+1,j) == 'AUX | V' dann write(S,i,j,BB) & write(SN-O,i,j,</FRAME>) && newline(i+1) && write(T,i+1,0,'dummy') & write(W,i+1,0,'N') & write(S,i+1,0,'NP') & write(SN-O,i+1,0,read(SN-O,search(SN-O,i-1,*,<(W,'N')>),0))
| TOKEN | WCAT | SCAT | OBJ/CLASS | SN-SR | SN-R | SN-ACT |
| hans | <N> | <OBJ name="hans" class="student" ></OBJ> | ||||
| ist | <AUX> | |||||
| klein | <ADJ, SIZE> | |||||
| und | <CON> | BB | </FRAME> | |||
| dummy | <N> | NP | <OBJ name="hans" class="student" ></OBJ> | |||
| hat | <AUX> | |||||
| dunkle | <ADJ, COLOR> | |||||
| haare | <CN> | <CLASS name="hair" token={(german, {haare})} class="body" > </CLASS> | ||||
| BB | <BB> | </FRAME> |
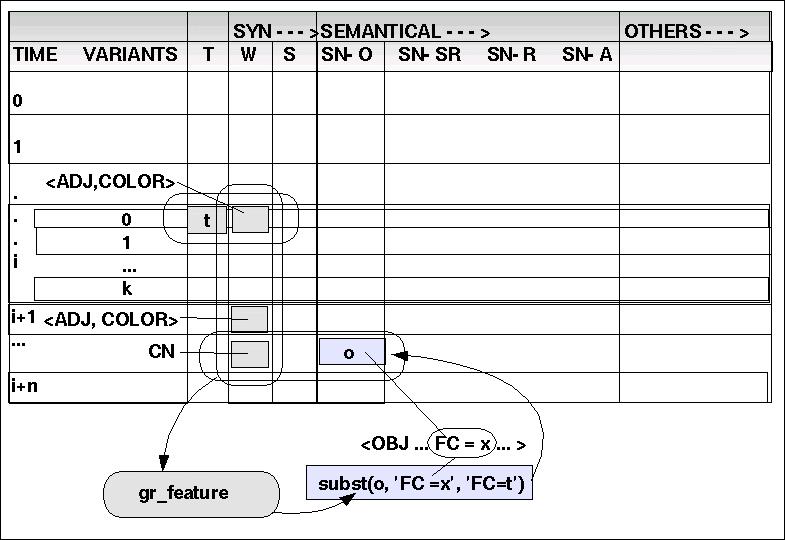
(5.) gr_feature: TOKEN x WCAT x SN-O ---> SN-O
Die Grundidee ist die, dass Adjektive, denen eine spezielle Feature-Klasse zugeordnet ist (wie z.B. ADJ 'dunkel' <---> COLOR) direkt in Attribute von zugehörigen Objekten übersetzt werden können. Dies setzt voraus, dass das zugehörige Objekt identifiziert wird. Hier werden zwei Hauptfälle unterschieden:
<N,AUX,ADJ> Das Adjektiv bezieht sich auf das vorausgehende nominale Objekt.Wenn read(W,i,j) == <N > & read(SN-O,i,j) == o & read(W,i+1,j) == <AUX > & read(W,i+2,j) == <ADJ,FC > & read(T,i+2,j) == 't' dann subst(o,'FC=x','FC=t').
<ADJ [ADJ]* CN> Das Adjektiv bezieht sich auf das nachfolgende allgemeine Nomen.Wenn read(W,i,j) == <ADJ,FC > & read(T,i,j) == 't' & read(W,i+c,j) == <ADJ,FC_i > & read(T,i+c,j) == 't_i' & read(W,i+c+1,j) == <CN > & read(SN-O,i+c+1,j) == o dann subst(o,'FC=x','FC=t') & subst(o, 'FC_i = x_i', FC_i = t_i').
| TOKEN | WCAT | SCAT | OBJ/CLASS | SN-SR | SN-R | SN-ACT |
| hans | <N> | <OBJ name="hans" class="student" SIZE="klein" ></OBJ> | ||||
| ist | <AUX> | |||||
| klein | <ADJ, SIZE> | |||||
| und | <CON> | BB | </FRAME> | |||
| dummy | <N> | NP | <OBJ name="hans" class="student" SIZE="klein" ></OBJ> | |||
| hat | <AUX> | |||||
| dunkle | <ADJ, COLOR> | |||||
| haare | <CN> | <CLASS name="hair" token={(german, {haare})} COLOR="dunkle" class="body" > </CLASS> | ||||
| BB | <BB> | </FRAME> |
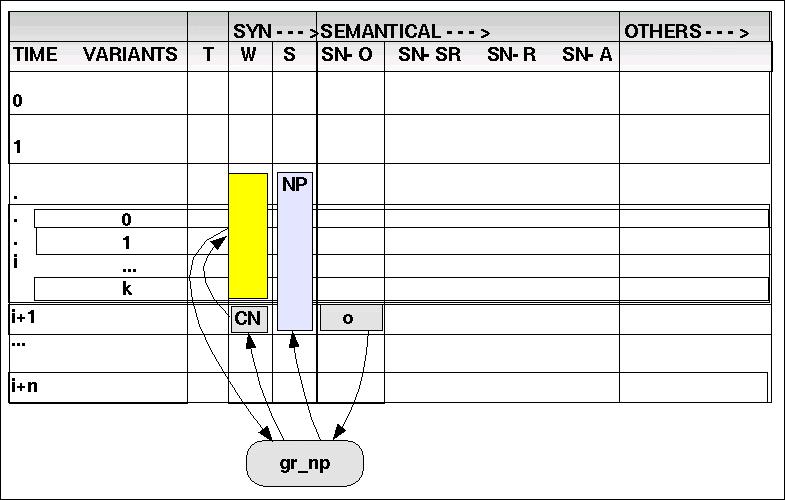
(6) gr_np: SN-O X W ---> S
Ausgehend von der Dimension SN-O werden Objekte identifiziert; dann werden auf der korrelierenden Dimension W jene Sequenzen analysiert, die diesen Objekten korrespondieren, und zwar ausgehend von 'N' und 'CN' Werten. Die Werte der 'W'-Dimension werden dann in die S-Dimension abgebildet.
<N> : Wenn read(SN-O,i,j) == 'o' & read(W,i,j) == 'N' dann write(S,i,j,NP).
<AUX ADJ [ADJ]* CN> Wenn read(SN-O,i,j) == 'o' & read(W,i,j) == 'CN' & read(W,(i,j), (i-c,j)) == 'ADJ' & read(W,i-c-1,j) == 'AUX' dann write(S,(i-c,j),(i,j),NP).
<ART [ADJ]* CN> Wenn read(SN-O,i,j) == 'o' & read(W,i,j) == 'CN' & optional(read(W,(i,j), (i-c,j)) == 'ADJ') & read(W,i-c-1,j) == 'ART' dann write(S,(i-c,j),(i,j),NP).
| TOKEN | WCAT | SCAT | OBJ/CLASS | SN-SR | SN-R | SN-ACT |
| hans | <N> | NP | <OBJ name="hans" class="student" SIZE="klein" ></OBJ> | |||
| ist | <AUX> | |||||
| klein | <ADJ, SIZE> | |||||
| und | <CON> | BB | </FRAME> | |||
| dummy | <N> | NP | <OBJ name="hans" class="student" SIZE="klein" ></OBJ> | |||
| hat | <AUX> | |||||
| dunkle | <ADJ, COLOR> | NP | ||||
| haare | <CN> | <CLASS name="hair" token={(german, {haare})} COLOR="dunkle" class="body" > </CLASS> | ||||
| BB | <BB> | </FRAME> |
(7)gr_srel: { PREP, ADV } ---> SREL
gr_srel maps the categories < PREP, ADV > into the set of spatial relations SREL.
Diese Regel wird weiter unten beschrieben
wcat(ADV [AUX | V])) ==> wcat(ADV) sn(REL) newline:( cat(N, NP) sn(insert(last(hist(scat(N), sn(OBJ))))) [AUX | V]
(8)gr_rel: { ARTP, POSP, POSPREP, AUX } ---> ~SREL
gr_rel maps the categories { ARTP, POSP, POSPREP, AUX} into the set of non-spatial relations ~SREL.
Diese Wortklassen werden angesehen als Repräsentanten von nicht-räumlichen Beziehungen, die eine irgendwie geartete 'Zugehörigkeitsbeziehung' artikulieren. Das Verfahren ist das folgende:
Ausgehend von der Dimension W wird nach entsprechenden Wortklassen gesucht: 'read(W,i,j,) == Y' mit Y in { ARTP, POSP, POSPREP, AUX }.
Wird ein solches Element identifiziert, wird das zugehörige Token dazu gelesen 'read(T,i,j) = t', und es wird eine Suche in dem semantischen Netz gestartet: 'sn_search()' in der Untermenge SN-R.
Werden passende Elemente in SN-R gefunden {o1, ..., ok}, dann wird für jedes Element der syntaktische Kontext 'synLR' geprüft: stimmt der ausgewiesene syntaktische Kontext mit dem aktuellen syntaktischen Kontext überein. Ist dies der Fall, dann wird das Element o aus SN-R in die Dimension SN-R kopiert mit 'write(SN-R, i,j,o)'.
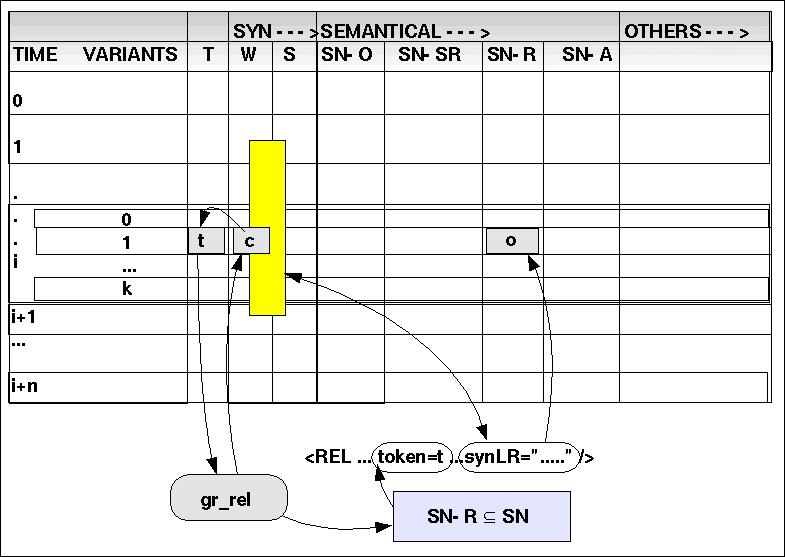
Im konkreten Fall trifft zunächst read(W,1,0) == <AUX> mit read(T,1,0) == 'ist' zu; d.h. es gibt Elemente in SN-R mit solch einem Token. Die dort angeführten syntaktischen Kontexte passen jedoch nicht.
Es gibt noch ein weiteres Element read(W,5,0) == <AUX> mit read(T,5,0) == 'hat'; es gibt Elemente in SN-R mit solch einem Token. In diesem Fall passen die dort angeführten syntaktischen Kontexte '(S,NP) (W,AUX) (S,NP)', also kann man dieses Element us SN-R nach SN-R übernehmen.
| TOKEN | WCAT | SCAT | OBJ/CLASS | SN-SR | SN-R | SN-ACT |
| hans | <N> | NP | <OBJ name="hans" class="student" SIZE="klein" ></OBJ> | |||
| ist | <AUX> | |||||
| klein | <ADJ, SIZE> | |||||
| und | <CON> | BB | </FRAME> | |||
| dummy | <N> | NP | <OBJ name="hans" class="student" SIZE="klein" ></OBJ> | |||
| hat | <AUX> | <REL name="HAVE" token={(german,{hat,haben})} args="(a,b)" synLR="(S,NP) (W,AUX) (S,NP)"> </REL> | ||||
| dunkle | <ADJ, COLOR> | NP | ||||
| haare | <CN> | <CLASS name="hair" token={(german, {haare})} COLOR="dunkle" class="body" > </CLASS> | ||||
| BB | <BB> | </FRAME> |
(9)gr_act: {AUX, V } ---> SN-A
gr_act maps the categories AUX and V into the set of activities SN-A.
Als letztes wird geprüft, ob irgendwelche Aktivitäten vorliegen. Es gibt einmal Aktivitäten im Kontext von 'AUX'; diese bilden einen Grenzfall; man kann darüber streiten, ob es sich um Aktivitäten oder 'Zustände' handelt. Ferner gibt es die Wortklasse 'V'.
Als erstes wird auf AUX geprüft. Das Schema ist das gleiche wie bei gr_rel. Der Unterschied liegt nur darin, dass jetzt statt in SN-R in SN-A gesucht wird. Es wird ein Element in SN-A gefunden, das einen passenden syntaktischen Kontext aufweist. Also kann man das Element in SN-A einsetzen.
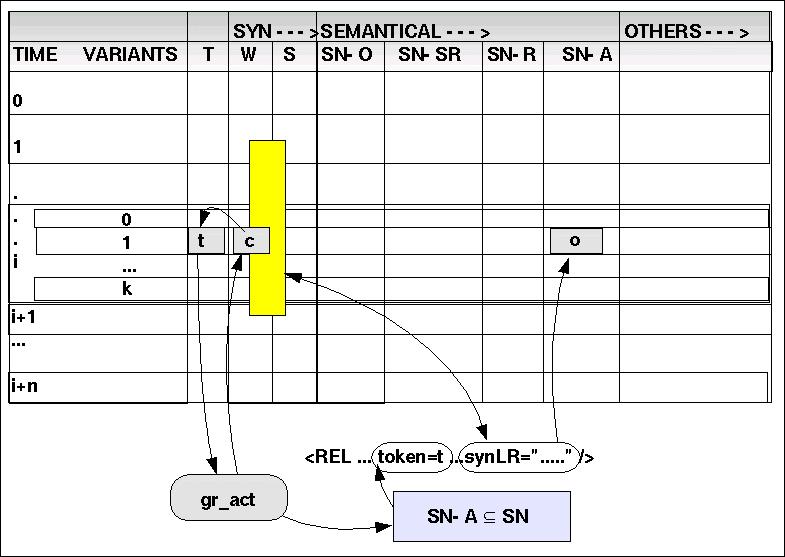
| TOKEN | WCAT | SCAT | OBJ/CLASS | SN-SR | SN-R | SN-ACT |
| hans | <N> | NP | <OBJ name="hans" class="student" SIZE="klein" ></OBJ> | |||
| ist | <AUX> | <ACTIVITY name="be" token={(german,{ist, sind)} args="(a)" syntLR="ADV NP - NP" or "NP - ADJ" > </ACTIVITY> | ||||
| klein | <ADJ, SIZE> | |||||
| und | <CON> | BB | </FRAME> | |||
| dummy | <N> | NP | <OBJ name="hans" class="student" SIZE="klein" ></OBJ> | |||
| hat | <AUX> | <REL name="HAVE" token={(german,{hat,haben})} args="(a,b)" synLR="(S,NP) (W,AUX) (S,NP)"> </REL> | ||||
| dunkle | <ADJ, COLOR> | NP | ||||
| haare | <CN> | <CLASS name="hair" token={(german, {haare})} COLOR="dunkle" class="body" > </CLASS> | ||||
| BB | <BB> | </FRAME> |
(10)gr2xml: DWM ---> PINT
gr2xml maps the dynamical working memory DWM into the picture interface PINT
Die Grundidee besteht darin, mit Blick auf die endgültige Struktur die vorhandenen Elemente umzugruppieren. Die endgültige Struktur, so wie sie in PINT festgehalten ist, orientiert sich primär an Raumrelationen, nachgeordnet an nicht-räumlichen Relationen, dann an Aktivitäten.
Der Konvertierungsprozess duchläuft folgende allgemeine Phasen:
IDENTIFIZIERUNG DER ARGUMENTE: Die Argumente von Relationen müssen identifiziert werden. Es wird angenommen, dass dies nur solche Elemente sein können, die in der Dimension S den Wert 'NP' haben. Welche es sind muss dann anhand des syntaktischen Kontextes ermittelt werden. Dabei gilt es, zu bedenken, dass im Rahmen des konkreten Sprechens (bzw. Schreibens) die Argumente von Relationen gewöhnlich 'serialisiert' werden, was zu 'Infixschreibweisen führt wie 'a R b' anstatt 'R a b'. Für PINT muessen alle diese Schreibweisen 'normalisiert' werden.
UMSTELLEN DER ARGUMENTE: Nachdem die Argumente identifiziert werden konnten, muessen in der Regel aufgrund der Serialisierung Umstellungen vorgenommen werden. D.h. in allen Fällen, in denen die ideale Anordnung 'R a1, ..., an' aufgrund des Textes noch nicht vorliegt, muessen die Elemente des Textes entsprechend umgruppiert werden.
FRAMEs: Ein kompletter Frame reicht dann entweder von der ersten Zeile bis zum ersten <FRAME> oder, wenn 'read(SN-O,i,j) == </FRAME>' das erste Frame-Ende anzeigt dann von Zeile i+1 bis zu Zeile'read(SN-O,i+c,j) == </FRAME>' mit dem nächsten Frame.
AUSGABE und LÖSCHEN DES FRAMES Zum Schluss wird der Inhalt der Spalten SN-O ... SN-A in der abschliessenden Reihenfolge als Text ausgegeben. Zeilen, in denen keine Eintragungen zu finden sind, werden dabei überlesen. Anschliessend werden die Zeilen des abgesendeten Frames in die History kopiert und im DWM gelöscht.
Innerhalb dieser Abarbeitung ist eine Rangfolge einzuhalten:
SN-SR
SN-R
SN-A
Betrachten wir das am Beispiel des ersten erkennbaren Frames.
Identifizierung und Umstellung von SN-SR und SN-R Elementen findet keine Anwendung, da es keine solchen Elemente gibt.
Identifizierung und Umstellung von SN-A Elementen findet eine Anwendung. SN-A-Element 'be' mit 'ist' trifft mit dem zweiten Kontext zu. Das Argument a wird also mit dem NP-Komplex 'read(S,0,0) == NP' identifiziert. Eine Umstellung muss zwischen den Zeilen 0 und 1 vorgenommen werden. Der Bereich der Aktivität muss entsprechend angepasst werden.
Der Beginn des Frames wird in die erste Zeile gelegt.
| TOKEN | WCAT | SCAT | OBJ/CLASS | SN-SR | SN-R | SN-ACT |
| ist | <AUX> | < FRAME> | <ACTIVITY name="be" token={(german,{ist, sind)} args="(a)" syntLR="ADV NP - NP" or "NP - ADJ" > | |||
| hans | <N> | NP | <OBJ name="hans" class="student" SIZE="klein" ></OBJ> | </ACTIVITY> | ||
| klein | <ADJ, SIZE> | |||||
| und | <CON> | BB | </FRAME> | |||
| dummy | <N> | NP | <OBJ name="hans" class="student" SIZE="klein" ></OBJ> | |||
| hat | <AUX> | <REL name="HAVE" token={(german,{hat,haben})} args="(a,b)" synLR="(S,NP) (W,AUX) (S,NP)"> </REL> | ||||
| dunkle | <ADJ, COLOR> | NP | ||||
| haare | <CN> | <CLASS name="hair" token={(german, {haare})} COLOR="dunkle" class="body" > </CLASS> | ||||
| BB | <BB> | </FRAME> |
Man erhält dann das folgende PINT-Dokument:
< FRAME>
<ACTIVITY name="be" token={(german,{ist, sind)} args="(a)" syntLR="ADV NP - NP" or "NP - ADJ" >
<OBJ name="hans" class="student" SIZE="klein" >
</OBJ>
</ACTIVITY>
</FRAME>
Es werden dann die Zeilen des abgesendeten Frames gelöscht:
| TOKEN | WCAT | SCAT | OBJ/CLASS | SN-SR | SN-R | SN-ACT |
| dummy | <N> | NP | <OBJ name="hans" class="student" SIZE="klein" ></OBJ> | |||
| hat | <AUX> | <REL name="HAVE" token={(german,{hat,haben})} args="(a,b)" synLR="(S,NP) (W,AUX) (S,NP)"> </REL> | ||||
| dunkle | <ADJ, COLOR> | NP | ||||
| haare | <CN> | <CLASS name="hair" token={(german, {haare})} COLOR="dunkle" class="body" > </CLASS> | ||||
| BB | <BB> | </FRAME> |
Die gleiche Prozedur wird jezt auf den nächsten Frame angewendet.
Identifizierung und Umstellung von SN-SR und SN-A Elementen findet keine Anwendung, da es keine solchen Elemente gibt.
Identifizierung und Umstellung von SN-R Elementen findet eine Anwendung. SN-R-Element 'have' mit 'hat' trifft mit dem syntaktischen Kontext zu. Das Argument a wird also mit dem NP-Komplex 'read(S,0,0) == NP' identifiziert und das Argument b mit dem NP-Komplex 'read(S,3,0) == NP'. Eine Umstellung muss zwischen den Zeilen 0 und 1 vorgenommen werden. Der Bereich der Relation muss entsprechend angepasst werden.
Der Beginn des Frames wird in die erste Zeile gelegt.
| TOKEN | WCAT | SCAT | OBJ/CLASS | SN-SR | SN-R | SN-ACT |
| hat | <AUX> | <FRAME> | <REL name="HAVE" token={(german,{hat,haben})} args="(a,b)" synLR="(S,NP) (W,AUX) (S,NP)"> | |||
| dummy | <N> | NP | <OBJ name="hans" class="student" SIZE="klein" ></OBJ> | |||
| dunkle | <ADJ, COLOR> | NP | ||||
| haare | <CN> | <CLASS name="hair" token={(german, {haare})} COLOR="dunkle" class="body" > </CLASS> | </REL> | |||
| BB | <BB> | </FRAME> |
Daraus wird das folgende PINT-Dokument generiert:
<FRAME>
<REL name="HAVE" token={(german,{hat,haben})} args="(a,b)" synLR="(S,NP) (W,AUX) (S,NP)">
<OBJ name="hans" class="student" SIZE="klein" ></OBJ>
<CLASS name="hair" token={(german, {haare})} COLOR="dunkle" class="body" > </CLASS>
</REL>
</FRAME>
9. Weitere Experimente mit dem LSG-Parser
MUSS MIT DEN NEUEN REGELN ÜBERARBEITET WERDEN !!!!
| TOKEN | WCAT | SCAT | OBJ/CLASS | SN-SR | SN-R | SN-ACT |
| hans | N | NP | <FRAME> <OBJ name="hans" class="student" ></OBJ> | |||
| ist | AUX | <REL name="HAVE" token={(german,{ist, sind})} args="(a,b)" synLR="NP+num - ADJ+num"> </REL> | ||||
| klein | ADJ | |||||
| und | CON | BB | </FRAME> | |||
| N | NP | <FRAME><OBJ name="hans" class="student" ></OBJ> | ||||
| hat | AUX | <REL name="HAVE" token={(german,{hat,haben})} args="(a,b)" synLR="NP - CN"> </REL> | ||||
| dunkle | ADJ | CN | ||||
| haare | CN | <CLASS name="hair" token={(german, {haare})} class="body" > </CLASS> | ||||
| BB | BB | BB | </FRAME> |
| TOKEN | WCAT | SCAT | OBJ/CLASS | SN-SR | SN-R | SN-ACT |
| er | PPR | |||||
| ist | AUX | |||||
| schueler | CN | |||||
| der | ART, ARTP | |||||
| dritten | CARD | |||||
| klasse | CN | |||||
| BB | BB |
| TOKEN | WCAT | SCAT | OBJ/CLASS | SN-SR | SN-R | SN-ACT |
| er | PPR | |||||
| betritt | V | |||||
| seine | POSP | |||||
| klasse | CN | |||||
| BB | BB |
| TOKEN | WCAT | SCAT | OBJ/CLASS | SN-SR | SN-R | SN-ACT |
| links | ADV | |||||
| an | PREP | |||||
| der | ART, ARTP | |||||
| stirnseite | CN | |||||
| haengt | V | |||||
| eine | ART | |||||
| weisse | ADJ | |||||
| tafel | CN | |||||
| an | PREP | |||||
| der | ART, ARTP | |||||
| wand | CN | |||||
| BB | BB |
| TOKEN | WCAT | SCAT | OBJ/CLASS | SN-SR | SN-R | SN-ACT |
| vor | PREP | |||||
| ihm | PPR | |||||
| steht | V | |||||
| das | ART | |||||
| braune | ADJ | |||||
| pult | CN | |||||
| des | ART, ARTP | |||||
| lehrers | CN | |||||
| BB | BB |
| TOKEN | WCAT | SCAT | OBJ/CLASS | SN-SR | SN-R | SN-ACT |
| rechts | ADV | |||||
| sind | AUX | |||||
| die | ART | |||||
| baenke | CN | |||||
| fuer | POSPREP | |||||
| die | ART | |||||
| schueler | CN | |||||
| BB | BB |
| TOKEN | WCAT | SCAT | OBJ/CLASS | SN-SR | SN-R | SN-ACT |
| er | PPR | |||||
| geht | V | |||||
| in | PREP | |||||
| die | ART | |||||
| dritte | CARD | |||||
| reihe | CN | |||||
| und | CON | |||||
| setzt | V | |||||
| sich | RPR | |||||
| auf | PREP | |||||
| seinen | POSP | |||||
| platz | CN | |||||
| am | PREP | |||||
| fenster | CN | |||||
| BB |
G.Döben-Henisch, The BLINDs WORLD I. Ein philosopisches Experiment auf dem Weg zum digitalen Bewußtsein, In: K.Gerbel/ P.Weibel (eds.), Mythos Information. Welcome to the wired world. @rs electronica 95, Springer-Verlag, Wien, pp.227-244, 1995.
G.Döben-Henisch, Semiotic Machines - An Introduction, In: E.W.B.Hess-Lüttich et al. (eds) Signs & Space - Raum & Zeichen. An International Conference on the Semiotics of Space and Culture in Amsterdam, Gunter Narr Verlag, Tübingen, 1998, pp. 313-327,1996b.
G.Döben-Henisch, Taxonomy for the INM-Neuron, MS, INM - Institute for New Media, Frankfurt, Germany, 1998
G.Döben-Henisch, Alan Matthew Turing, the Turing Machine, and the Concept of Sign, In: W.Schmitz, Th.A.Sebeok (eds.),Das Europäische Erbe der Semiotik; The European Heritage of Semiotics, ISBN 3933592062, to be published 2002
G.Döben-Henisch, J.Hasebrook, A Toolbox of Artificial Brain Cells to Simulate Classical and Operant Learning Behavior. 6th Conference on Computational Ontelligence. Dortmund: University of Dortmund, 1999, pp.689-691
G.Döben-Henisch, L.Erasmus, J.Hasebrook, Knowledge Robots for Knowledge Workers: Self-Learning Agents connecting Information and Skills, in: Intelligent Agents and Their Applications (Studies in Fuzziness and Soft Computing, Vol. 98), L. C. Jain, Zhengxin Chen, Nikhil Ichalkaranje (eds.), Springer, New York, 2002, pp.59-79
J.Dudel, R.Menzel, R.F.Schmidt, Neurowissenschaft. Vom Molekül zur Kognition. Springer-Verlag, 1996
Miachel S.Gazzaniga (ed), The Cognitive Neuroscience, MIT Press, Cambridge (MA),1995
E.Hinrichs et.al, Robust Chunk Parsing for Spontaneous Speech, in: W.Wahlster (ed.), Verbmobil: Foundations of Speech-to-Speech Translation,Springer, Berlin - Heidelberg - New, 2000 York et al., pp.163-182
Xuedong Huang, Alex Acero, Hsiao-Wuen Hon, Spoken Language Processing. A Guide to Theory, Algorithm, and System Development, Prentice Hall PTR, Upper Saddle River (NJ), 2001
D.Jurafsky, J.H.Martin , Speech and Language Processing. An Introduction to Natural Language Processing, Computational Linguistics, and Speech Recognition, Prentice Hall, Upper Saddle River (NJ), 2000
Charles W. MORRIS, Foundations of the Theory of Signs, 1938. Chicago, University of Chicago Press
Charles W. MORRIS, Signs, Language and Behavior. New York, Prentice-Hall Inc, 1946
OMG Unified Modeling Language Specification, Version 1.3, March 2000 (siehe: OMG Documents)
M.Schiehlen, Semantic Construction, in: W.Wahlster (ed.), Verbmobil: Foundations of Speech-to-Speech Translation,Springer, Berlin - Heidelberg - New, 2000 York et al., pp.200-215
Luc Steels, Language Games for Autonomous Robots. IEEE Intelligent Systems, Sept./Oct. 2001, pp.16-22
A.M.Turing, On Computable Numbers with an Application to the Entscheidungsproblem, In: Proc. London Math. Soc., Ser.2, vol.42(1936), pp.230-265; received May 25, 1936; Appendix added August 28; read November 12, 1936; corr. Ibid. vol.43(1937), pp.544-546. Turing's paper appeared in Part 2 of vol.42 which was issued in December 1936
W.Wahlster (ed.), Verbmobil: Foundations of Speech-to-Speech Translation,Springer, Berlin - Heidelberg - New, 2000 York et al.