
|
|
II-RA PROZESSRECHNER SS03 - Vorlesung mit Übung
|
Anhand eines einfachen Beispiels und einer komplexeren Modellierung wurden bisher die Grundbegriffe der Modellierung vorgestellt. Mengentheoretische Grundlagen wurde erläutert. Zum Abschluss dieser Einführung wird hier ein zweites Beispiel ausführlich vorgestellt. Im Anschluss daran wird die Problematik der zeitlichen Dimension thematisiert. Grundbegriffe der Realzeit werden eingeführt.
Das zweite Beispiel betrachtet ein System, das im Rahmen einer Alarmschaltung auf bestimmte Eigenschaften des Eingangssignals mit ganz gezielten Aktionen reagieren soll. Die Anwendungssituation ist im folgenden Schaubild festgehalten.
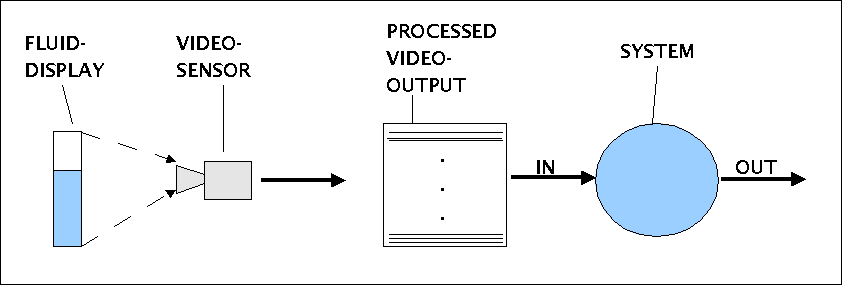
Beispiel einer Alarmschaltung
Eine Flüssigkeitsanzeige ('fluid display') gibt Auskunft über (i) den Füllstand eines Behälters sowie (ii) über die Geschwindigkeit der Änderung. Ein Videosensor ist so eingestellt, dass die Flüssigkeitsanzeige das Bild vollständig ausfüllt. Diejenigen Bereiche, die mit Flüssigkeit gefüllt sind, erscheinen als 'dunkel', der übrige Bereich als 'hell'. Der Input des Videosensors wird so verarbeitet, dass als Output eine 100 x 10 Matrix ausgegeben wird, in der eine Zeile entweder die Werte '1111111111' hat (dies indiziert 'Flüssigkeit') oder '0000000000' (dies indiziert 'keine Flüssigkeit'). Eine Zeile entspricht somit 1% der Messfläche. Der vorverarbeitete Video-Output wird dem System als Input übergeben. Die Betreiber des Systems interessieren sich für folgende Eigenschaften des Inputs:
Der Füllstand des Behälters mit Flüssigkeit hat 75% erreicht; dies ist höchste Alarmstufe A3.
Der Füllstand des Behälters ist grösser 63%; dies ist Alarmstufe A2
Der Füllstand des Behälters ist grösser 25%; dies ist Alarmstufe A1
Der Füllstand des Behälters ist grösser 25% und steigt mit mindestens 10% pro Messintervall; dies ist auch Alarmstufe A2
Der Füllstand des Behälters ist grösser 25% und steigt mit mindestens 15% pro Messintervall; dies ist auch Alarmstufe A3
In allen anderen Fällen soll kein Alarm gegeben werden.
Dieses Beispiel bietet Stoff für viele Diskussionen. Nehmen wir die Werte zunächst einmal, wie vorgegeben. Es geht jetzt darum, ein Modell zu konstruieren.
Die Modellbildung folgt dem Schema, das in Vorlesung 5 ausführlich vorgestellt worden ist.
Vorgegebens ist das Schema SYS(s) gdw s = < < O1, ..., Ok >, F > Nennen wir das zu konstruierende System s_alarm. Es muss dann gezeigt werden, dass gilt: SYS(s_alarm). Dies ist nur dann der Fall, wenn gilt s_alarm = < < O1, ..., Ok >, F >, d.h. es gibt Objekte und eine Systemfunktion für s_alarm. Um diese Forderung einzulösen, müssen wir entsprechende Objekte und Funktionen konstruieren.
Für die Konstruktion solch einer Funktion gibt es keine klaren Regeln. Fest stehen nur die Eckwerte und die allgemeine Forderung, dass die Funktion vollständig und rechtseindeutig sein soll. Alles übrige muss 'herausgefunden' werden. Das nachfolgende Schaubild gibt eine Skizze, auf welche Weise z.B. die Funktion F_s_alarm() konstruiert werden könnte:
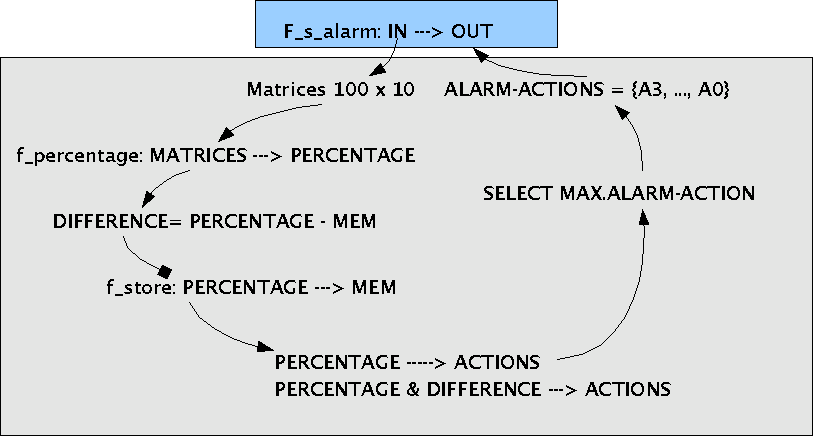
Konstruktion der Systemfunktion
Im vorliegenden Beispiel gibt es mindestens zwei Arten von Systemobjekten: IN und OUT. Weitere Objekte können
durch die Analyse als notwendig erscheinen. So z.B. ein 'Memory-Objekt' MEM zum zwischenspeichern des letzten
Inputwertes. Man könnte also schreiben:
objects(s_alarm) = < IN, OUT, MEM >.
Von der Menge IN ist bekannt, dass sie aus Elementen besteht, die 100 x 10-Matrizen sind, also IN = {y| MATRIX(y,100,10)}, wobei dann genau definiert werden müsste, wie denn so eine MATRIX(y,100,10) aussehen würde. Dies schenken wir uns hier.
Von der Menge OUT wissen wir, dass gilt: OUT = {A0, A1, A2, A3}, wobei 'A0' für 'kein Alarm' stehen soll.
Als nächstes muss die Konstruktion der Systemfunktion Fs_alarm vorbereitet werden. Grundsätzlich
gilt, dass Fs_alarm eine Abbildung der Art ist: Fs_alarm: ARGUMENTE ---> WERTE, wobei die
Argumente und Werte aus dem Bereich der Objekte von s_alarm stammen müssen. Aus dem Zusammenhang ist bekannt, dass
Werte aus der Menge OUT bestimmten Werten aus der Menge IN nach bestimmten 'Kriterien' zugeordnet werden sollen.
D.h. generell wird folgende Zuordnung benötigt:
Fs_alarm: IN ---> OUT
Genauer gilt: Aus dem Input muss ein %-Wert errechnet werden und in Abhängigkeit von diesem --und eventuell dem
%-Wert des vorausgehenden Inputwertes-- soll eine mögliche Antwort berechnet werden. Daraus ergibt sich, dass die
Systemfunktion Fs_alarm möglicherweise Hilfsfunktionen benötigt:
fprozent: IN ---> NAT*
fstore: NAT+ ---> MEM (mit MEM = {p'} )
fclassify1: NAT+ ---> OUT
fclassify2: NAT+ x NAT+ ---> OUT
Die Systemfunktion wird damit in folgende Abfolge von Hilfsfunktionen zerlegt:
p = fprozent(m) berechnet aus einer Matrix m einen %-Wert p;
Dieser Wert wird mittels action1 = fclassify1(p) in eine mögliche Aktion umgerechnet.
Dann wird die Differenz des aktuellen Wertes p mit dem letzten Wert p' aus MEM gebildet: d = p - p' und der aktuelle Wert gespeichert: MEM = fstore(p).
Die Differenz d wird mittels action2 = fclassify2(p,d) in eine mögliche Aktion umgerechnet.
Falls action2 > action1 dann wird action2 ausgeführt, ansonsten action1.
Setzt man die vorausgehende Analyse um, dann wird der Input schon in alle möglichen Varianten zerlegt: einmal bzgl. der kritischen %-Werte und einmal bzgl. der Beschleunigungsraten. Die beiden konkurrierenden Werte, die sich aus diesen Fallunterscheidungen ergeben können, werden dann bzgl. der Priorität verglichen (NOALARM < A1 < A2 < A3). Der Wert mit der höchsten Priorität wird genommen.
Wurde im vorausgehenden Text geklärt.
Wenn man alle Bestandteile der Systemfunktion --einschliesslich möglicher Teilfunktionen-- gefunden hat, die eine Lösung ergben könnten --Optimierungsfragen bleiben hier zunächst unberücksichtigt--, dann hat man neben diversen Systemobjekten in der Regel eine endliche Menge von 'eingebauten' oder neu definierten Funktionen zur Verfügung, die zum Einsatz kommen sollen. Für die Anwendung dieser endlichen Menge von Funktionen ist es nun wichtig, noch festzulegen, in welcher zeitlichen Abfolge dies geschehen soll. Dies kann grundsätzlich rein sequentiell geschehen oder partiell auch parallel. Um diese Sachverhalte zu repräsentieren kann man grundsätzlich gerichtete Graphen benutzen: die Kanten in den Graphen sind dann Funktionen; der Knoten am Ausgangspunkt einer solchen Funktionskante ist dann eine Menge von Objekten, die die Inputobjekte der Funktion als Teilmenge enthalten, und der Knoten am Endpunkt des Graphen ist ebenfalls eine Menge von Objekten, die die Outputobjekte als Teilmenge enthalten. Dort, wo Kanten verzweigen und 'parallel' laufen liegt dann eine Parallelverarbeitung vor.
Eine andere Darstellungsweise wäre jene mittels Struktogrammen (Für den klassischen Artikel zur Idee und Motivation von Struktogrammen siehe FLOWCHART TECHNIQUES FOR STRUCTURED PROGRAMMING von I. Nassi und B. Shneiderman (1973)). Struktogramme sind bis heute ein sehr wertvolles Mittel, um die Anordnung der Abarbeitung von Funktionsmengen darzustellen; sie eignen sich auch immer noch hervorragend für spätere Berechnungen zum Zeitbedarf von Algorithmen. Im vorliegenden Fall liegt nur eine rein sequentielle Verarbeitung vor, man kann die Struktogramm-Darstellungsweise aber auch leicht auf den parallelen Fall ausdehnen. Aus praktischen Gründen empfiehlt sich eventuell eine Kombination: Für die Repräsentation der generellen Struktur paralleler Prozesse benutzt man einen gerichteten Graphen und für die inhaltliche Beschreibung der einzelnen Pfade Struktogramme.
Es folgt das Beispiel eines Struktogramms für eine der Teilfunktionen f_classify1():
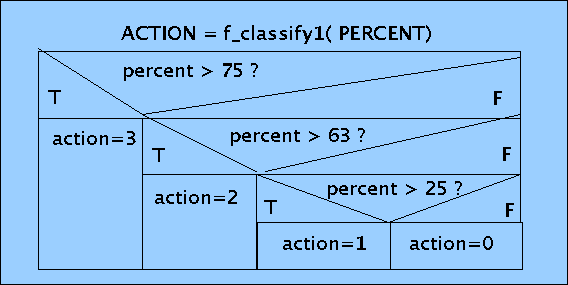
Struktogramm zu Funktion f_classify1()
Mittels eines solchen Struktogramms kann man auch überprüfen, ob die Funktion, die man modelliert hat, vollständig und rechtseindeutig ist (die klassischen Forderungen an Standardfunktionen): die Modellierung ist vollständig, wenn für alle potentiell möglichen Inputwerte eine Antwort definiert ist und die Funktion ist rechtseindeutig, wenn für jeden Inputwert genau ein Wert aus den Outputwerten definiert ist.
Anhand des Struktogramms kann man leicht sehen, dass die Gesamtheit aller Inputwerte in vier Fälle zerlegt wird und für jeden Fall wird genau eine Antwort definiert.
Bei der Implementierung des Modells SYS(s_alarm) in scilab kann man sich von zwei Eckwerten leiten lassen (siehe nachfolgendes Bild):
Die Modellfunktion F_s_alarm:IN ---> OUT lässt sich fast direkt als eine scilab-Funktion [OUT] = F_s_alarm(IN) hinschreiben.
Entsprechend lassen sich alle Hilfsfunktionen direkt als scilab-Funktionen implementieren.
Das scilab-Programm entspricht dann genau der System-Funktion.
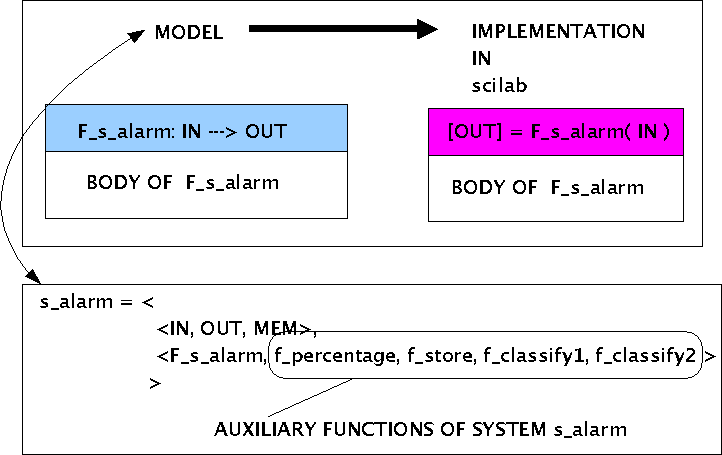
Vom Modell zur Implementierung
Bei der nachfolgenden Implementierung wurde von folgender Vereinfachung Gebrauch gemacht: es wurden nicht Matrizen als Eingangswerte benutzt, sondern es wurde angenommen, dass die Auswertung der Matrizen bzgl. prozentualem Anteil von Wasser in der Anzeige schon erfolgt ist, so dass nur noch Prozentwerte an das System übergeben wurden.
//---------------------------------- //
// ii-ra-bsp2.sci
//
// author: gerd doeben-henisch
//
// first: may-5, 2003
// last: may-6, 2003
//
// idea: scilab-implementation of theoretical model
// given in lecture 8 of PRT
// For more comments see text of lecture
//
//---------------------------------------
//Classifies percentages for actions
function [action] = f_classify1(percent)
if percent > 75 then action=3
elseif percent > 63 then action=2
elseif percent > 25 then action=1
else action=0
end
endfunction
//Classifies percentages and degree of change for actions
function [action] = f_classify2(percent,difference)
if percent > 24 & difference > 9 & difference < 15 then action=2
elseif percent > 24 & difference > 14 then action=3
else action=0
end
endfunction
//-----------------------------------------------------
//The main system-function calling the other functions
//----------------------------------------------------
//
// f_alarm1()
//
// Input of values by keyboard
//
//---------------------------------------------------
function [action] = f_alarm1(percent)
cont = 'y'
mem = percent
while cont == 'y'
percent = input('Next item of fluid display [0,100]')
ac1=f_classify1(percent)
difference = percent - mem
mem = percent
ac2 = f_classify2(percent,difference)
if ac2 > ac1 then action=ac2
else action = ac1
end
disp('INPUT : ',percent, difference)
disp('OUTOUT : ',action)
cont = input('continue (y,n) ?')
end
endfunction
//-----------------------------------------------------
//The main system-function calling the other functions
//----------------------------------------------------
//
// f_alarm2()
//
// Input of values by file
//
//---------------------------------------------------
function [action] = f_alarm2()
fdata=read('WEB-MATERIAL/fh/II-RA/II-RA-EX/EX8/f_alarm2_data.dat',1,20)
mem = fdata(1)
for k=2:1:20
percent = fdata(k)
ac1=f_classify1(percent)
difference = percent - mem
mem = percent
ac2 = f_classify2(percent,difference)
if ac2 > ac1 then action=ac2
else action = ac1
end //End if
disp('INPUT : '),disp(percent, difference)
disp('OUTPUT : '), disp(action)
end //End for
endfunction
//-----------------------------------------------------
//The main system-function calling the other functions
//----------------------------------------------------
//
// f_alarm3()
//
// Input of values by file
// and Output of diagrams of
// -Input-values
// - Difference
// - Output-Values
//
//---------------------------------------------------
function [action] = f_alarm3()
fdata=read('WEB-MATERIAL/fh/II-RA/II-RA-EX/EX8/f_alarm2_data.dat',1,20)
magnify=25
diff(1)=0
outp(1)=0
mem = fdata(1)
for k=2:1:20
percent = fdata(k)
ac1=f_classify1(percent)
difference = percent - mem
mem = percent
ac2 = f_classify2(percent,difference)
if ac2 > ac1 then action=ac2
else action = ac1
end //End if
diff(k)=difference
outp(k)=action*magnify
end //End for
xbasc()
plot2d(fdata)
plot2d(diff)
plot2d3([1:1:20],outp)
endfunction
Nachdem man das programm scilab auf der Kommandozeile einer shell (oder über ein Icon auf der grafischen Oberfläche) gestartet hat
>scilab
kann man innerhalb von scilab die Datei laden:
-->getf('WEB-MATERIAL/fh/II-RA/II-RA-EX/EX8/ii-ra-bsp2.sci')
-->
Der Pfad ist von Rechner zu Rechner verschieden, da er davon abhängt, wie scilab installiert wurde. Der eigentliche Dateiname ist hier ii-ra-bsp2.sci. Man kann jetzt von scilab aus alle funktionen aufrufen, die in der Datei definiert wurden, auch die Hilfsfunktionen einzeln. Der Aufruf der Hilfsfunktion f_classify1() sähe folgendermassen aus:
-->f_classify1(40)
ans =
1.
-->f_classify1(65)
ans =
2.
-->f_classify1(76)
ans =
3.
-->
Ein Beispiel für den isolierten Aufruf der Hilfsfunktion f_classify2():
-->f_classify2(25,6)
ans =
0.
-->f_classify2(25,11)
ans =
2.
-->f_classify2(25,15)
ans =
3.
-->
Will man die scilab-Implementierung von F_s_alarm() über die Tastatur benutzen, dann muss man f_alarm1() aufrufen:
-->f_alarm1(10)
Beim Aufruf von f_alarm1(10) übergibt man einen Startwert für den letzten Inputwert, der aktuell in MEM gespeichert ist.
Next item of fluid display [0,100]-->20
10.
20.
INPUT :
0.
OUTOUT :
Gibt man als neuen Wert 20 ein --der letzte alte Wert ist 10--, dann erhält man als Differenz 10 und als aktuellen Wert 20. Der Output ist die Alarm-Aktion 0.
continue (y,n) ?-->'y'
Next item of fluid display [0,100]-->31
11.
31.
INPUT :
2.
OUTOUT :
Gibt man als neuen Wert 31 ein --der letzte alte Wert ist 20--, dann erhält man als Differenz 11 und als aktuellen Wert 31. Der Output ist die Alarm-Aktion 2, der der %-Wert über 25 ist und die Veränderung grösser als 10.
continue (y,n) ?-->'y'
Next item of fluid display [0,100]-->57
26.
57.
INPUT :
3.
OUTOUT :
continue (y,n) ?-->'y'
Next item of fluid display [0,100]-->67
10.
67.
INPUT :
2.
OUTOUT :
continue (y,n) ?-->'y'
Next item of fluid display [0,100]-->75
8.
75.
INPUT :
2.
OUTOUT :
continue (y,n) ?-->'y'
Next item of fluid display [0,100]-->77
2.
77.
INPUT :
3.
OUTOUT :
continue (y,n) ?-->n
-->f_alarm3(1)
ans =
0.
-->
Die Version f_alarm2() bezieht ihren Input aus einer datei. Die Beispieldatei hat folgenden Inhalt:
10,15,20,26,39,42,35,27,33,44, 48,53,69,74,84,98,95,65,35,15
Ruft man f_alrm2() von scilab aus auf, dann erhält man folgenden output:
-->f_alarm2()
INPUT :
5.
15.
OUTPUT :
0.
INPUT :
5.
20.
OUTPUT :
0.
INPUT :
6.
26.
OUTPUT :
1.
INPUT :
13.
39.
OUTPUT :
2.
INPUT :
3.
42.
OUTPUT :
1.
INPUT :
- 7.
35.
OUTPUT :
1.
INPUT :
- 8.
27.
OUTPUT :
1.
INPUT :
6.
33.
OUTPUT :
1.
INPUT :
11.
44.
OUTPUT :
2.
INPUT :
4.
48.
OUTPUT :
1.
INPUT :
5.
53.
[More (y or n ) ?]
OUTPUT :
1.
INPUT :
16.
69.
OUTPUT :
3.
INPUT :
5.
74.
OUTPUT :
2.
INPUT :
10.
84.
OUTPUT :
3.
INPUT :
14.
98.
OUTPUT :
3.
INPUT :
- 3.
95.
OUTPUT :
3.
INPUT :
- 30.
65.
OUTPUT :
2.
INPUT :
- 30.
35.
OUTPUT :
1.
INPUT :
- 20.
15.
OUTPUT :
0.
ans =
0.
-->
Schliesslich gibt es auch noch die Variante, dass man sich sämtliche werte (Input, Differenzen und Output) grafisch anzeigen lassen kann (hier in einfachster Version):
-->f_alarm3()
ans =
0.
-->
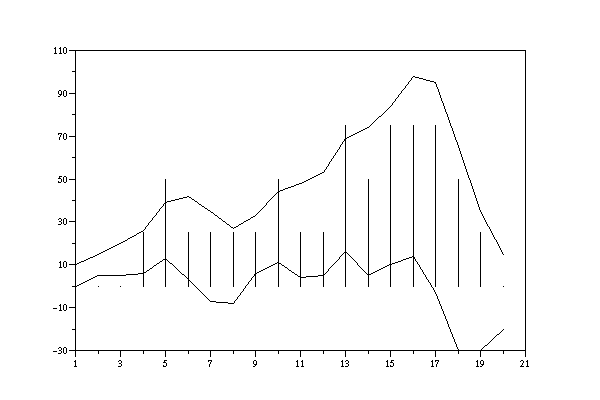
Visualization of version f_alarm3():
Input := upper curce;
Differenz := lower
curve;
Output := vertical bars (vertical bars are magnified)
Es wurde erste Grundbegriffe der Realzeit eingeführt. Siehe nächste VL.
Zur Einübung der bislang vorgestellten Modellierungsmethoden sei hier ein weiteres Beispiel gegeben, das man versuchen sollte, zu modellieren.
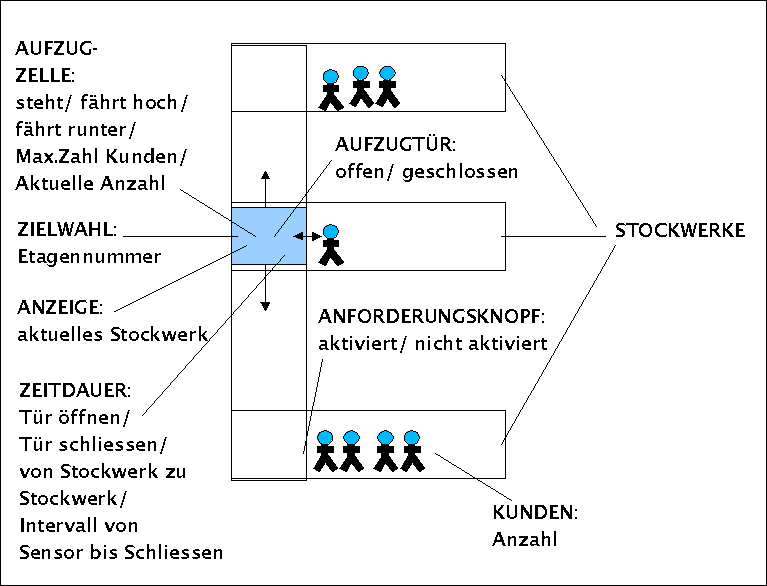
The elevator system with some parameters
Ausgangspunkt der Problemstellung ist ein Aufzugsystem. Eine Aufzugzelle kann zwischen k-vielen Stockwerken hin- und herbewegt werden. Ausgangsstellung ist das unterste Stockwerk, das hier mit Stockwerksnummer = 0 gesetzt wird. Auf jedem Stockwerk gibt es einen Anforderungsknopf, mit dem man den Aufzug anfordern kann. Eine Leuchtanzeige leuchtet auf, solange eine Anforderung erkannt worden ist. Bei Eintreffen des Aufzugs öffnet sich die Tür. Kunden können den Aufzug verlassen bzw. eintreten. Die Zelle fasst maximal n-viele Personen. Wenn nach Öffnen der Tür die Lichtschranke z-viele Sekunden nicht mehr unterbrochen wurde, dann schliesst die Tür. Kunden, die eintreten, können über ein Tastenfeld die Nummer des Ziel-Stockwerks eingeben. Liegen Anforderungen vor, die noch nicht verarbeitet sind, dann berechnet der Aufzug einen Weg und setzt die Zelle in Bewegung. Sobald keine Anforderungen mehr vorliegen, bleibt die Zelle dort stehen, wo der letzte Kunde den Aufzug verlassen hat. Für die Fahrt von einem Stockwerk i zum nächsthöheren i+1 oder nächstniedrigerem i-1 benötigt der Aufzug durchschnittlich f-viele Sekunden. Zum Öffnen und Schliessen der Tür benötigt der Aufzug jeweils t-viele Sekunden.
Aus Sicht des Betreibers des Aufzugs ist es interessant, zu wissen, wie lange die durchschnittlichen/schlechtesten Wartezeiten sowie die durchschnittlichen/schlechtesten Fahrzeiten eines potentiellen Kunden sind. Natürlich spielt hier die durchschnittliche Kundenzahl pro Stockwerk eine Rolle.
Folgen sie bei der Modellierung dieses Problems den bisherigen methodischen Schritten:
Identifizierung der Systemobjekte: welche Grössen müssen unterschieden werden? Was ist der Input des Systems, was der Output?
Beschreiben Sie die Beziehungen, die zwischen den Objekten herrschen. Welche Teilfunktionen bieten sich an, um die Systemfunktion daraus aufzubauen?
Wenn sie erste Hypothesen über mögliche Funktionen haben: nehmen Sie eine Fallunterscheidungen bzgl. der Inputmenge vor (Vollständigkeit) und ordnen Sie jedem Inputwert genau einen Outputwert zu (Rechtseindeutigkeit).
Wenn Sie Funktionen auf die zuvor beschriebene Weise identifiziert haben, dann erstellen Sie für jede Funktion ein Struktogramm.
Implementieren Sie ihre Funktionen anhand der Struktogramme in scilab.