|
|
I-TI04 WS 04 - Vorlesung mit Übung
|
Vor dem Hintergrund des Sprechens über Grammatiken sollen heute die Typ3-Sprachen anhand von regulären Ausdrücken sowie dem Scannergenerator flex weiter behandelt werden.
Ausgehend von den Token eines Textes wird informell und formal beschrieben, was reguläre Ausdrücke sind. Es wird dann gezeigt, wie eine Beschreibung und Analyse von regulären Ausdrücken durch eine flex-Beschreibungsdatei mit der Endung .l (kleines L, Hinweis darauf, dass flex ursprünglich lex hiess.) geleistet werden kann. Da Automaten dazu benutzt werden, um die durch Grammatiken definierte Sprachen zu erkennen --in diesem Fall endliche Automaten für die Menge regulärer Ausdrücke--, wird hier nochmals eingegangen auf den Begriff des endlichen Automaten. Die Familie der endlichen Automaten wird vorgestellt. Speziell werden auch die deterministischen und nichtdeterministischen Varianten erklärt. Es folgt ein Hinweis darauf, dass der Scannegenerator flex die regulären Ausdrücke einer flex-Beschreibungsdatei intern in deterministische endliche Automaten übersetzt. Am Beispiel der Simulation eines Mealy Automat wird dann verdeutlicht (i) wie man reguläre Ausdrücke benutzen kann, um den Input des Automaten zu beschreiben sowie (ii) wie man statt mit einem Simulator auch die Menge aller Automatenprogramme abdecken kann. Abschliessend wir auf einige allgemeine Beziehungen zwischen endlichen Automaten und regulären Ausdrücken hingewiesen.
In der lexikalischen Analyse geht man davon aus, dass sich die Folge von Buchstaben, die einen Text konstituieren, sich einer endlichen Menge von Wörtern -- terminale Elemente oder Token genannt, zuordnen lässt. Diese Token können in beliebiger Reihenfolge auftreten. Die Aufgabe der lexikalischen Analyse besteht dann darin, das Auftreten dieser Token zu erkennen. Im einfachsten Fall besitzt man von vornherein eine endliche Liste dieser Token und vergleicht dann die Buchstaben eines Textes --von links nach rechts bzw. vom Anfang bis zum Ende-- daraufhin, welche Sequenzen von Buchstaben welches der vorausgesetzten Token entspricht. Schlägt die Zuordnung fehl, liegt ein Fehler vor. Andernfalls wird ein Token erkannt.
Angenommen, die folgende Liste von Token ist vorgegeben:
nord
ost
sued
west
und dazu der folgende Text:
westnordnordsuedostsuedwestsuednordostnordostostwest
Eine korrekte lexikalische Analyse müsste dann jedes vorgegebene Token in dieser Zeichenkette erkennen. Andernfalls müsste eine Fehlermeldung erscheinen.
In der vorausgehenden Vorlesung wurde ds Konzept der formalen Grammatik eingeführt zusammen mit dem Klassifikationsvorschlag der Chomsky Hierarchie. In dieser Hierarchie stehen die sogenannten Typ3-Grammatiken für die schwächste Klasse von formalen Sprachen. Alternativ zur Schreibweise der durch die Typ3-Grammatiken definierten Typ3-Sprachen gibt es in der Praxis auch die Bezeichnung reguläre Ausdrücke. Damit sind Sprachen gemeint, die formal genauso mächtig sind wie die Typ3-Sprachen, sie werden aber nicht durch eine Typ3-Grammatik beschrieben, sondern eben durch reguläre Ausdrücke.
In der nachstehenden Tabelle (siehe das ausgezeichnete Online-Skript von [Richter 2002](Dort auch eine Postscript-Version)) sind die verbreitetsten Notationen für reguläre Sprachen zusammengestellt, und zwar:
Theorie: die in der Theorie der formalen Sprachen übliche Notation
ERE: Extended Regular Expression (=erweiterter regulärer Ausdruck) gemäß X/Open CAE Specification "System Interface Definitions", Issue 4
BRE: Basic Regular Expression (=einfacher regulärer Ausdruck) gemäß dem selben Dokument
Shell: Wildcards (=Joker) nach den Konventionen von Unix-Shells
SQL: Wildcards (=Joker) nach den Konventionen von SQL-Datenbankabfragen, die ansonsten hier nicht weiter diskutiert werden.
Nicht in dieser Tabelle enthalten sind:
| Theorie | ERE | BRE | Wildcard | ||
|---|---|---|---|---|---|
| Shell | SQL | ||||
| leere Menge | Ø | (fehlt) | (fehlt) | (fehlt) | (fehlt) |
| einzelnes Zeichen | a | a | a | a | a |
| Konkatenation (Hintereinanderschreiben) | xy | xy | xy | xy | xy |
| Alternative, Vereinigung | x | y | x | y | (fehlt) | (fehlt) | (fehlt) |
| Klammer | ( . . . ) | ( ... ) | \( ... \) | (fehlt) | (fehlt) |
| Rückverweis auf Inhalt der i-ten Klammer | (fehlt) | (fehlt) | \i | (fehlt) | (fehlt) |
| einzelnes Zeichen aus endlicher Menge | a | b | c | [abc] | [abc] | [abc] | (fehlt) |
| einzelnes Zeichen nicht aus endlicher Menge | (fehlt) | [^abc] | [^abc] | [!abc] | (fehlt) |
| beliebiges einzelnes Zeichen | (fehlt) | . | . | ? | _ |
| beliebiger Text | (fehlt) | .* | .* | * | % |
| Kleenescher Abschluss (0..?-fache Wiederholung) | x* | x* | x* | (fehlt) | (fehlt) |
| optionaler Teilausdruck (0..1-fache Wiederholung) | ( | x) | x? | (fehlt) | (fehlt) | (fehlt) |
| 1..?-fache Wiederholung | xx* | x+ | xx* | (fehlt) | (fehlt) |
| m-fache Wiederholung | (fehlt) | x{m} | x\{m\} | (fehlt) | (fehlt) |
| m..n-fache Wiederholung | (fehlt) | x{m,n} | x\{m,n\} | (fehlt) | (fehlt) |
| m..?-fache Wiederholung | (fehlt) | x{m,} | x\{m,\} | (fehlt) | (fehlt) |
Erläuterungen zur Tabelle:
Der Begriff "Wiederholung" wird hier so verwendet, dass damit nicht Wiederholungen zusätzlich zu einem Original gemeint sind, d.h. eine 5-fache Wiederholung von a ist ein String von fünf, nicht von sechs a.
Der gelb unterlegte Teil der Tabelle zeigt den Bereich an, in welchem sich die Unterschiede zwischen Shell-Namensmustern einerseits und ERE/BRE andererseits befinden.
Die zur Darstellung aller regulären Sprachen notwendigen Sprachmittel sind hellgrün unterlegt (außer in den gelben Bereichen). Man sieht daraus, dass nur ERE die Bezeichnung "reguläre Ausdrücke" verdienen, während mit allen anderen Notationen nur ein Teil der regulären Sprachen dargestellt werden kann. Das rot unterlegte Feld deutet an, dass mit dieser Notation die Menge der regulären Sprachen überschritten wird.
Die hellblau unterlegten Teile sind Abkürzungen für solche Ausdrücke, die zwar nur geringes theoretisches Interesse wecken können, aber in der Praxis oft vorkommen, z.B. a{2,4} als Abkürzung für aa|aaa|aaaa.
Eine informelle Darstellung von regulären Ausdrücken in Form einer induktiven Definition ist die folgende:
Ø ist ein regulärer Ausdruck, der die leere Sprache beschreibt, d.h. die Sprache, die kein Wort enthält, nicht einmal das leere.
Für jedes Zeichen a ist a ein regulärer Ausdruck, der die Sprache beschreibt, die genau ein Wort enthält, wobei dieses Wort genau aus dem Zeichen a besteht.
Sind E1 und E2 reguläre Ausdrücke, die die Sprachen L1 und L2 beschreiben, so ist (E1)(E2) ein regulärer Ausdruck, der die Sprache beschreibt, deren Wörter jeweils aus einem Wort aus L1 und einem Wort aus L2 konkateniert sind.
Ist E ein regulärer Ausdruck, der die Sprache L beschreibt, so ist (E)* ein regulärer Ausdruck, der die Sprache beschreibt, deren Wörter sich als endliche (auch leere) Konkatenationen von Wörtern aus L schreiben lassen. Diese Sprache heißt auch der Kleene'sche Abschluss von L nach Stephen Cole Kleene (1909-1994); Aussprache: ['kli:ni].
Sind E1 und E2 reguläre Ausdrücke, die die Sprachen L1 und L2 beschreiben, so ist (E1)|(E2) ein regulärer Ausdruck, der die Sprache beschreibt, deren Wörter in L1 oder in L2 vorkommen, also die Vereinigungsmenge der beiden Sprachen.
Sind E1 und E2 reguläre Ausdrücke, die die Sprachen L1 und L2 beschreiben, so ist (E1)&(E2) ein regulärer Ausdruck, der die Sprache beschreibt, deren Wörter in L1 und in L2 vorkommen, also den Durchschnitt der beiden Sprachen.
Sind E1 und E2 reguläre Ausdrücke, die die Sprachen L1 und L2 beschreiben, so ist (E1)\(E2) ein regulärer Ausdruck, der die Sprache beschreibt, deren Wörter in L1, aber nicht in L2 vorkommen, also die Differenzmenge der beiden Sprachen.
Die Klammern dürfen weggelassen werden, wenn trotzdem Eindeutigkeit besteht, zum Beispiel bei der Konkatenation oder Vereinigung von mehr als zwei Sprachen nach Regel 3 bzw. 5. Außerdem bindet der Stern für den Kleene'schen Abschluss stärker als die anderen Operatoren und das Hintereinanderschreiben für die Konkatenation stärker als die explizit hingeschriebenen zweistelligen Operatoren. Das Zeichen \ klammert nach links: K\L\M bedeutet also (K\L)\M. Man kann diese Klammerungs- und Vorrangregeln auch direkt in die Definition aufnehmen, was aber zur leichten Verständlichkeit nicht unbedingt beiträgt; dafür lassen sich aus so geschriebenen Definitionen leichter auf automatischem Weg Programme generieren, die Ausdrücke in ihre Bestandteile zerlegen.
Eine formale induktive Definition für z.B. die theoretische Version der regulären Sprachen (TRE) lautet wie folgt:
TRE(s) gdw s = <TRE,ALPH, OperTRE >
und es gilt:
ALPH C TRE
(A:x,y)( x,y ∈ TRE & ^ ∈ OperTRE ==> x^y ∈ TRE )
(A:x,y)( x,y ∈ TRE & | ∈ OperTRE ==> x|y ∈ TRE )
(A:x)( x ∈ TRE & () ∈ OperTRE ==> (x) ∈ TRE )
(A:x)( x ∈ TRE & * ∈ OperTRE ==> x* ∈ TRE )
Ferner müssen die Operatoren aus der Menge OperTRE noch definiert werden, z.B.:
x^y = xy = {<a,b>| x,y,a,b ∈ TRE & a = x & b = y}
x|y = {<a>| x,y,a ∈ TRE & a = x or a = y}
(x) = {<a>| x,a ∈ TRE & a = x }
x* = {<a>| x,a ∈ TREn & (A:i)(i ∈ n ==> ai = xi })
Ein Beispiel für reguläre Ausdrücke wären die Zugangaben bei dem Damespiel. Dort gilt, dass der Zug eines Steines von einem Startfeld zu einem Zielfeld --eventuell über mehrere Zwischenstationen beim Überspringen gegenerischer Steine-- wie folgt geschrieben werden soll:
STARTFELD:ZIELFELD[,ZIELFELD]*Diese Schreibweise kommt einem regulären Ausdruck schon sehr nahe. Eine ausführliche Darstellung eines Spielzuges in einem Damespiel könnte wie folgt aussehen:
[a-h][1-8]:[a-h][1-8](,[a-h][1-8])*Dies bedeutet: Erst ein Zeichen aus [a-h], dann ein Zeichen aus [1-8], dann das Zeichen ':' selbst, dann wieder ein Zeichen aus [a-h] gefolgt von einem Zeichen aus [1-8]. Optional können dann keinmal, einmal oder mehrmals folgen ein Komma ',', ein Zeichen aus [a-h] gefolgt von einem Zeichen aus [1-8]. Damit wären alle Zugeingaben des Damespiels erfasst. Schauen wir uns dies im Beispiel an.
In der Praxis finden sich reguläre Ausdrücke fast überall. Z.B. gibt es Editoren --wie den xemacs oder quanta-- bei denen kann man bei der Such- oder bei der Ersetzungsfunktion reguläre Ausdrücke eingeben. Entsprechend bei dem Arbeiten mit der Shell unter Unix und Linux. Weniger sichtbar aber deswegen nicht weniger bedeutend ist der Einsatz von sogenannten Scannern als Vorstufe zu Parsern. Scanner analysieren die Token eines Textinputs daraufhin, ob sie zu bestimmten Ausdrucksklassen gehören. Solche Scanner sind Programme --z.B. geschrieben in C oder C++--, die das Vorliegen bestimmter Zeichenkombinationen (pattern) überprüfen. Solche Scanner per Hand zu schreiben kann sehr schnell äusserst mühsam werden. Um diese Aufgabe zu erleichtern wurden schon sehr früh sogenannte Scanner Generatoren entwickelt. So wurde schon 1975 das Konzept des Scannergenerators lex (später in einer GNU-Version flex) durch M.E.Lesk in einem Report der AT & T Bell Labs vorgestellt. Anstatt für jede Aufgabe einen eigenen Parser zu schreiben, übergibt man an flex eine Beschreibungsdatei mit Endung .l, in der man mittels regulärer Ausdrücke die zu erkennenden Token beschreibt. flex generiert dann daraus automatisch eine C-Datei (oder neuerdings auch eine C++-Datei), die eine Realisierung eines lexikalischen Scanners darstellt.
Für eine detaillierte Beschreibung von flex kann man den Befehl 'info flex' auf der Shell-Kommandozeile eingeben. Für weitere Informationen kann man auch das sehr ausführliche Buch [HEROLD 1992] konsultieren.
Erzeugung eines Scanners aus einer flex-Datei
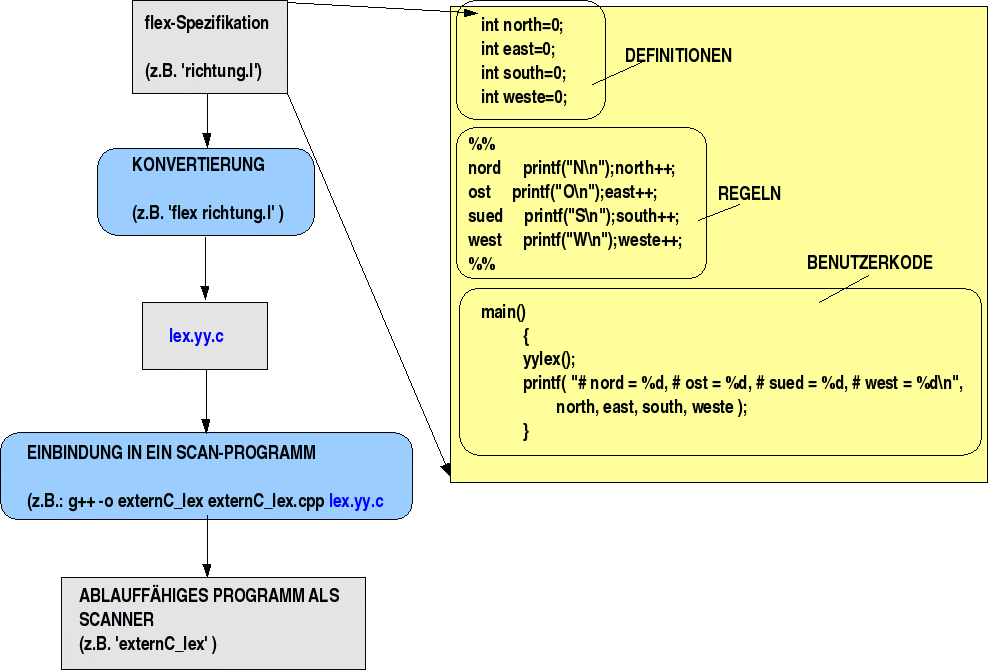
Eine flex-Datei kann aus drei Abschnitten bestehen (s.u.): Definitionen, Regeln und Benutzer Code. In den Definitionen können Variablen deklariert werden, die dann im aufrufenden C-Programm benutzt werden können. Jede Regel besteht aus einem Paar PATTERN ACTION, wobei PATTERN ein regulärer Ausdruck ist und ACTION einen C-Befehl darstellt, d.h. im PATTERN wird ein mögliches Token-Ereignis beschrieben und in dem ACTION-Teil wird die gewünschte Reaktion auf dieses Ereignis festgelegt. Eine Regel hat dann also die Struktur 'if PATTERN then ACTION' oder 'Wenn PATTERN, dann ACTION'. Im Benutzerkode kann man beliebige C-Funktionen definieren, auch natürlich eine main-Routine. Liegt eine flex-Spezifikationsdatei --auch flex-Programm genannt-- mit dem suffix '.l' vor, dann generiert flex eine C-Datei `lex.yy.c', die intern eine Routine `yylex()' definiert. Die Datei lex.yy.c kann dann in einen ausführbaren Objektkode umgewnadelt werden.
Ein einfaches Beispiel. Eine lex-Spezifikation für das Programm 'richtung.l'. Im Definitionsteil werden vier Variablen eingeführt, die zum Zählen von Ereignissen benutzt werden sollen (Achtung: diese Deklarationen dürfen nicht in der ersten Spalte beginnen!). Im Regelteil wird jedem Richtungswort eine Aktion zugeordnet (Ausgabe auf den Bildschirm und zählen)(Achtung: diese PATTERN müssen in der ersten Spalte beginnen!). Im benutzerspezifischen Teil wird eine main-Routine beschrieben, die nach Beendigung von yylex() die Anzahl der gezählten Ereignisse ausgibt.
int north=0;
int east=0;
int south=0;
int weste=0;
%%
nord printf("N\n");north++;
ost printf("O\n");east++;
sued printf("S\n");south++;
west printf("W\n");weste++;
%%
main()
{
yylex();
printf( "# nord = %d, # ost = %d, # sued = %d, # west = %d\n",
north, east, south, weste );
}
Ein Übungstext mit Namen 'commands1.txt' sieht wie folgt aus:
gerd@kant:~/public_html/fh/I-PROGR3/I-PROGR3-TH/VL3> cat commands1.txt nordnordsuednordwestnordnordostsuednord
Die Kompilierung des flex-Programmes 'richtung.l' geschieht wie folgt:
gerd@kant:~/public_html/fh/I-PROGR3/I-PROGR3-TH/VL3> flex richtung.l
Damit wird die Datei 'lex.yy.c' erzeugt. Diese Funktion kann nun als Funktion in einem anderen Programm aufgerufen werden, z.B. in einer eigenen main-Routine. In diesem Fall ist die Kompilierung recht einfach:
gerd@kant:~/public_html/fh/I-PROGR3/I-PROGR3-TH/VL3> gcc -o richtung lex.yy.c -lfl
(die Bibliothek '-lfl' wird nur benötigt, wenn keine eigene main-Routine ausserhalb der Datei 'lex.yy.c' existiert.)
Damit steht einer Anwendung dann nichts mehr im Wege:
gerd@kant:~/public_html/fh/I-PROGR3/I-PROGR3-TH/VL3> ./richtung < commands1.txt N N S N W N N O S N # nord = 6, # ost = 1, # sued = 2, # west = 1
Die obigen Beispiele benutzen für die PATTERN individuelle Wort-Token als ganze Einheiten. Dies ist zwar möglich, bleibt aber hinter den Möglichkeiten von flex weit zurück, denn flex kann als PATTERN auch sogenannte reguläe Ausdrücke verarbeiten. Für flex und die regulären Ausdrücke in flex siehe [HEROLD 1992] sowie die Informationen unter Linux mit info flex.
Als erstes wird eine flex-Datei angegeben, die solche PATTERN benutzt, die reguläre Ausdrücke für Züge im Damespiel darstellen.
/****************
*
* dame1.l
*
* author: gdh
* first: oct-31, 2003
* last:-
* idea: flex-demo-datei fuer zug im damespiel
*
****************/
%{
#include "dame1.h"
%}
%%
[ \t]+ ; /* Blanks und Tabs werden ueberlesen */
\n {return(ZEILENENDE);}
[a-h][1-8]:[a-h][1-8](,[a-h][1-8])* {return(ZUG);}
%%
Aus dieser Datei dame1.l lässt sich dann schon die Datei lex.yy.c erzeugen:
gerd@kant:~/public_html/fh/I-PROGR3/I-PROGR3-TH/VL5> flex dame1.l
Dann wird eine Headerdatei dame1.h angelegt, da sowohl flex als auch das aufrufende Hauptprogramm bestimmte Konstanten gemeinsam nutzen sollen.
/**************** * * dame1.h * * author: gdh * first: oct-31, 2003 * last:- * idea: flex-demo-datei fuer zug im damespiel * ****************/ #include <stdio.h> #define ZUG 256 #define ZEILENENDE 257
Dazu benötigen wir noch die Usage Datei, die die Funktion yylex() aus der Datei lex.yy.c benutzt:
/****************
*
* usage_dame.cpp
*
* author: gdh
* first: oct-31, 2003
* last:-
* idea: Benutzung einer lex-datei
*
* compilation: gcc -o usage_dame usage_dame.cpp lex.yy.c -lfl
* usage: usage_dame
*
****************/
#include <iostream>
#include "dame1.h"
using namespace std;
int main(void){
extern int yylex(void);
int token;
while(token=yylex() ){
switch(token){
case ZUG: {cout << "ZUG" << endl; break; }
case ZEILENENDE: {cout << "ZEILENENDE" << endl; break; }
default: {cout << "FEHLER" << endl; break;}
}/* End of token */
}/* End of while */
return (1);
}
Jetzt lässt sich der Scanner kompilieren, der die flex-Funktion zum erkennen der regulären ausdrücke für Züge im Damespiel enthält:
gerd@kant:~/public_html/fh/I-PROGR3/I-PROGR3-TH/VL5> g++ -o usage_dame usage_damelex.cpp lex.yy.c -lfl
Es folgt ein Aufruf mit Beispielen:
gerd@kant:~/public_html/fh/I-PROGR3/I-PROGR3-TH/VL5> ./usage_dame a1:b2 ZUG ZEILENENDE a1:b2,c5 ZUG ZEILENENDE a1:b4t3 /* <--- Falsche Eingabe mit 't3' */ ZUG t3ZEILENENDE
Natürlich kann man in flex zur Vereinfachung von längeren Ausdrücken auch Makros einführen. Dazu schreibt man
im Definitionsteil ausserhalb des durch %{ %} geklammerten Teils eine Kombination
NAME ERSETZUNGSTEXT
z.B. (siehe unten)
FELD [a-h][1-8]
Hier steht der Name 'FELD' als Abkürzung für den regulären Ausdruck '[a-h][1-8]'. Man kann dann den Namen 'FELD' im Regeltext benutzen, indem man dieses Makro durch geschweifte Klammern '{FELD}' markiert. Das bisherige Beispiel sieht dann wie folgt aus:
/****************
*
* dame2.l
*
* author: gdh
* first: nov-1, 2003
* last:-
* idea: flex-demo-datei fuer zug im damespiel
*
****************/
%{
#include "dame1.h"
%}
FELD [a-h][1-8]
%%
[ \t]+ ; /* Blanks und Tabs werden ueberlesen */
\n {return(ZEILENENDE);}
{FELD}:{FELD}(,{FELD})* {return(ZUG);}
%%
Kompilierung und Gebrauch (Usage) folgt:
gerd@kant:~/public_html/fh/I-PROGR3/I-PROGR3-TH/VL5> flex dame2.l gerd@kant:~/public_html/fh/I-PROGR3/I-PROGR3-TH/VL5> g++ -o usage_dame2 usage_damelex.cpp lex.yy.c -lfl gerd@kant:~/public_html/fh/I-PROGR3/I-PROGR3-TH/VL5> ./usage_dame2 a1:b4 ZUG ZEILENENDE a1:b3,c5,h8 ZUG ZEILENENDE a9:b3 /* <------- Falsche Eingabe mit '9' */ a9:b3ZEILENENDE
Als nächstes kann man die Zeichenkette, die mit einem Pattern erkannt worden ist, als Wert auch direkt ausgeben. Dazu muss man auf die Variable 'yytext' zugreifen, in der flex die erkannten Zeichen speichert.
/****************
*
* dame3.l
*
* author: gdh
* first: nov-1, 2003
* last:-
* idea: flex-demo-datei fuer zug im damespiel
*
****************/
%{
#include "dame1.h"
#include <stdio.h>
%}
FELD [a-h][1-8]
%%
[ \t]+ ; /* Blanks und Tabs werden ueberlesen */
\n {return(ZEILENENDE);}
{FELD}:{FELD}(,{FELD})* { printf(" INPUT = %s\n ",yytext); return(ZUG);}
%%
gerd@kant:~/public_html/fh/I-PROGR3/I-PROGR3-TH/VL5> flex dame3.l gerd@kant:~/public_html/fh/I-PROGR3/I-PROGR3-TH/VL5> g++ -o usage_dame3 usage_damelex.cpp lex.yy.c -lfl gerd@kant:~/public_html/fh/I-PROGR3/I-PROGR3-TH/VL5> ./usage_dame3 a1:b3 INPUT = a1:b3 ZUG ZEILENENDE a1:b4,c5,h3 INPUT = a1:b4,c5,h3 ZUG ZEILENENDE b9:t2 b9:t2ZEILENENDE
Natürlich kann man die Werte von yytext auch in eine andere Variable kopieren, z.B. in den array 'token_input':
/****************
*
* dame4.l
*
* author: gdh
* first: nov-1, 2003
* last:-
* idea: flex-demo-datei fuer zug im damespiel
*
****************/
%{
#include "dame1.h"
#include <string.h>
#include <stdio.h>
char token_input[100];
%}
FELD [a-h][1-8]
%%
[ \t]+ ; /* Blanks und Tabs werden ueberlesen */
\n {return(ZEILENENDE);}
{FELD}:{FELD}(,{FELD})* { printf(" INPUT = %s\n ",yytext);
strcpy(token_input,yytext);
printf(" KONTROLLE = %s\n ",token_input);
return(ZUG);
}
%%
gerd@kant:~/public_html/fh/I-PROGR3/I-PROGR3-TH/VL5> flex dame4.l gerd@kant:~/public_html/fh/I-PROGR3/I-PROGR3-TH/VL5> g++ -o usage_dame4 usage_damelex.cpp lex.yy.c -lfl gerd@kant:~/public_html/fh/I-PROGR3/I-PROGR3-TH/VL5> ./usage_dame4 a1:b4 INPUT = a1:b4 KONTROLLE = a1:b4 ZUG ZEILENENDE c4:b5,d1,h8 INPUT = c4:b5,d1,h8 KONTROLLE = c4:b5,d1,h8 ZUG ZEILENENDE a2:b4,k3,c5 /* <--- Fehler k3 */ INPUT = a2:b4 KONTROLLE = a2:b4 ZUG ,k3,c5ZEILENENDE
Diese Variable 'token_input' kann man dann auch vom Hauptprogramm aus aufrufen. Man muss sie dem Programm nur bekannt machen:
/****************
*
* usage_dame5.cpp
*
* author: gdh
* first: nov-1, 2003
* last:-
* idea: Benutzung einer lex-datei
*
* compilation: gcc -o usage_dame4 usage_dame4.cpp lex.yy.c -lfl
* usage: usage_dame4
*
****************/
#include <iostream>
#include "dame1.h"
using namespace std;
int main(void){
extern int yylex(void);
extern char token_input[];
int token;
while(token=yylex() ){
switch(token){
case ZUG: { cout << "ZUG" << endl;
cout << "C++ Ausgabe von token_input : " << token_input << endl;
break; }
case ZEILENENDE: {cout << "ZEILENENDE" << endl; break; }
default: {cout << "FEHLER" << endl; break;}
}/* End of token */
}/* End of while */
return (1);
}
Kompilierung und Nutzung wie vorher:
gerd@kant:~/public_html/fh/I-PROGR3/I-PROGR3-TH/VL5> g++ -o usage_dame5 usage_dame5.cpp lex.yy.c -lfl gerd@kant:~/public_html/fh/I-PROGR3/I-PROGR3-TH/VL5> ./usage_dame5 a1:b4,c5 INPUT = a1:b4,c5 KONTROLLE = a1:b4,c5 ZUG C++ Ausgabe von token_input : a1:b4,c5 ZEILENENDE c2:b4,c5,d6 INPUT = c2:b4,c5,d6 KONTROLLE = c2:b4,c5,d6 ZUG C++ Ausgabe von token_input : c2:b4,c5,d6 ZEILENENDE
Wie schon zuvor in dieser Vorlesung bemerkt, benutzt man in der Regel Automaten eines Typs T um Sprachen eines Typs G zu erkennen. Im Falle der Typ3-Sprachen bzw. der Menge der regulären Ausdrücke --also BRE = L(g,3)-- sind es endliche Automaten, die geeignet sind, reguläre Ausdrücke zu erkennen.
Leider, wie so oft, ist der Begriff des endlichen Automaten nicht so eindeutig, wie man es gerne hätte. Abhängig von unterschiedlichen Problemlösungskontexten wurden unterschiedliche Varianten von endlichen Automaten definiert. Daher soll hier zu Beginn ein kurzer Überblick über die wichtigsten Spielarten endlicher Automaten gegeben werden, bevor die Thematik in Richtung Erkennbarkeit von regulären Sprachen weiter entwickelt wird (siehe zu solch einem Überblick den Artikel von [YU 1997]).
Siehe für diesen Abschnitt ausserdem [Alexander ASTEROTH/Christel BAIER 2002:Kap.6].
Wir werden den Überblick so aufbauen, dass wir die Definition eines endlichen automaten aus den vorausgehenden Vorlesungen als Ausgangspunkt nehmen, und alle anderen Definitionen darauf beziehen. Auf diese Weise bekommt man eine ganz gute 'Taxonomie' aufgrund struktureller Vereinfachungen bzw. Verkomplizierungen.
Wir bezeichnen den von uns eingeführten endlichen Automaten in diesem Zusammenhang einfach mal als den Prototypen einer endlichen Maschine ('finite state machine' (FSM)), die dadurch gewonnen wurde, dass man aus der Definition der deterministischen Turingmaschine die Bewegung entfernte.
FSM(t) gdw t = < < Q, E, Ti, To, {§}, {q0 } >, < P > >
mit
Q:= endliche nichtleere Menge von Zuständen
E := Menge der Endzustände; E C Q & E != 0
Ti:= endliches Eingabe-Alphabet; |Ti| > 0
To:= endliches Ausgabe-Alphabet; kann leer sein
B = Ti u {§}; das endliche Bandalphabet
§ := das leere Zeichen
q0 := der Anfangszustand; q0 in Q
P ist das Programm des endlichen Automaten t und es gilt
P: (Q -E) x B --->
Q x To
MEALY(t) hat die Programmfunktion PMEALY: Q x B ---> Q x To ([YU 1997:66])
MOORE(t) hat die Programmfunktion PMOORE: Q x B --->
Q x To mit der Zerlegung PMOORE = FMOORE u GMOORE der Art:
FMOORE: Q x B ---> Q
GMOORE: Q ---> To
GENERALIZED_SEQUENTIAL_MACHINE(t) hat die Programmfunktion PGSM: Q x B ---> Q x To* ([YU 1997:67])
FINITE_TRANSDUCER(t) hat die Programmfunktion PFT: Q x Ti* ---> Q x To* ([YU 1997:67])
NON-DETERMINISTIC_FINITE_AUTOMATON(t) hat die Programmfunktion PNFA: Q x B ---> 2Q ([YU 1997:49ff])
DETERMINISTIC_FINITE_AUTOMATON(t) hat die Programmfunktion PDFA: Q x B ---> Q ([YU 1997:45ff])
ALTERNATING_FINITE_AUTOMATON(t) hat die Programmfunktion PAFA: Ti x BQ ---> B, wobei B ein 2-elementige Algebra ist mit <{0,1}, +, &, ¬,0,1 > ([YU 1997:54ff])
In dieser Aufstellung sieht man sofort die strukturelle Ähnlichkeit all dieser endlichen Automaten, aber auch die jeweiligen minimalen Abweichungen. Auf den ersten Blick sehr unterschiedlichen sind die alternierenden Automaten (AFAs); für eine effiziente Implementierung von endlichen Automaten erscheinen sie sehr interessant; wir werden hier nicht auf dies Thema eingehen. Der interessierte Student sei auf die angegebene Literatur verwiesen.
Für die weiteren Überlegungen beschränken wir uns zunächst auf die Varianten DFA. Diese Variante eines endlichen Automaten erzeugen keinen expliziten Output. Er wird nur gesteuert durch die jeweilige Eingabe und durch die unterschiedliche Folgen von Zuständen, die, im Erfolgsfall, in sogenannte Endzustände münden.
Als interessante Erweiterung eines deterministischen Automaten wird auch noch der nichtdeterministe endliche Automat (NFA) betrachtet.
Um die Menge LDFA jener Sprachen definieren zu können, die durch einen DFA erkannt werden können, benötigen wir zusätzlich ein Konzept der Erkennbarkeit eines Inputwortes w durch einen deterministischen Automaten a (siehe zum Folgenden [SCHÖNING 2001:27ff]).
DFA(a) gdw a = < < Q, E, Ti, {q0 } >, P >
mit
Q:= endliche nichtleere Menge von Zuständen
E := Menge der Endzustände; E C Q & E != 0
Ti:= endliches Eingabe-Alphabet; |Ti| > 0
B = Ti u {§}; das endliche Bandalphabet
q0 := der Anfangszustand; q0 in Q
P ist das Programm des endlichen Automaten a und es gilt
P: Q x B --->
Q
Seien (q,z) in Q x B, dann gilt P(q,z) = q' mit q' als dem eindeutigen Nachfolgerzustand von q bei z.
Zusätzlich wird folgende Funktion P' definiert mit P': Q x Ti* ---> Q
P'(q,§) = q
P'(q,ax) = P'(P(q,a),x) (mit a in T und x in T*)
Mit Hilfe der Funktionen P' und P kann man nun jede Eingabe w entweder zu einem Zustand zurückverfolgen, der in E ist oder nicht. Damit kann man definieren:
(A:a)(T(a) = { x | x in T* & DFA(a) & P'a(q0,x) in Ea })
T(a) bezeichnet also die Menge der Ausdrücke, die der deterministische Automat a erkennen kann. Dann kann man weiter eine Konstante LDFA definieren:
LDFA = T(a)
Nichtdeterministische endliche Automaten (NFAs)unterscheiden sich von den deterministischen endlichen Automaten (DFAs) dadurch, dass bei einem DFA für jeden Zustand q aus der Menge der Zustände Q genau nur ein Folgezustand q' aus Q festgelegt ist. Bei NFAs kann es mehr als einen Folgezustand geben, also {q'1, ..., q'k} C Q. Die formalen Definitionen von NFAs zusammen mit dem Begriff der Ableitung und der durch einen NFA A definierte sprache L(A) lautet wie folgt (siehe zum Folgenden z.B. [SCHÖNING 2001:30ff]).
NFA(a) gdw a = < < Q, E, Ti, S >, P >
mit
Q:= endliche nichtleere Menge von Zuständen
E := Menge der Endzustände; E C Q & E != 0
Ti:= endliches Eingabe-Alphabet; |Ti| > 0
B = Ti u {§}; das endliche Bandalphabet
S := Menge von Anfangszuständen; S C Q
P ist das Programm des endlichen Automaten a und es gilt
P: Q x B --->
2Q
Seien (q,z) in Q x Ti, dann gilt P(q,z) = Q' mit Q' als Menge von Nachfolgerzuständen von q bei z.
Zusätzlich wird folgende Funktion P' definiert mit P': 2Q x Ti* ---> 2Q
P'(Q',§) = Q' (mit Q' C Q)
P'(Q',ax) = U(q in Q')( P'(P(q,a),x) ) (mit a in T und x in T*)
Mit Hilfe der Funktionen P' und P kann man nun jede Eingabe w entweder zu einer Menge von Zuständen Q' zurückverfolgen, von denen wenigstens einer in E ist oder nicht. Damit kann man definieren:
(A:a)(TN(a) = { x | x in T* & NFA(a) & P'a(S,x) cut Ea != 0)})
TN(a) bezeichnet also die Menge der Ausdrücke, die der nicht-deterministische Automat a erkennen kann. Dann kann man weiter eine Konstante LNFA definieren:
LNFA TN(a)
Beispiele für endliche Automaten (dfas und nfas) mit regulären Ausdrücken finden sich hier.
Der Scanner-Generator flex erzeugt ein C/C++-Programm yy.lex.c, in dem die regulären Ausdrücke aus der flex-Beschreibungsdatei ___.l in einen deterministischen endlichen automaten (DFA) übersetzt werden. Im folgenden werden entsprechend Abschnitte aus der erzeugten Datei yy.lex.c gezeigt.
/* A lexical scanner generated by flex */ /* Scanner skeleton version: * $Header: /home/daffy/u0/vern/flex/RCS/flex.skl,v 2.91 96/09/10 16:58:48 vern Exp $ */ #define FLEX_SCANNER #define YY_FLEX_MAJOR_VERSION 2 #define YY_FLEX_MINOR_VERSION 5 #include... #define YY_NUM_RULES 4 #define YY_END_OF_BUFFER 5 static yyconst short int yy_accept[17] = { 0, 0, 0, 5, 4, 1, 2, 4, 1, 0, 0, 0, 3, 0, 0, 3, 0 } ; static yyconst int yy_ec[256] = { 0, 1, 1, 1, 1, 1, 1, 1, 1, 2, 3, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 4, 1, 1, 1, 1, 5, 5, 5, 5, 5, 5, 5, 5, 1, 6, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 7, 7, 7, 7, 7, 7, 7, 7, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1 } ; static yyconst int yy_meta[8] = { 0, 1, 1, 1, 1, 1, 1, 1 } ; static yyconst short int yy_base[17] = { 0, 0, 0, 18, 19, 15, 19, 11, 13, 8, 6, 7, 7, 3, 4, 4, 19 } ; static yyconst short int yy_def[17] = { 0, 16, 1, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 0 } ; static yyconst short int yy_nxt[27] = { 0, 4, 5, 6, 4, 4, 4, 7, 13, 15, 14, 13, 12, 11, 10, 8, 9, 8, 16, 3, 16, 16, 16, 16, 16, 16, 16 } ; static yyconst short int yy_chk[27] = { 0, 1, 1, 1, 1, 1, 1, 1, 15, 14, 13, 12, 11, 10, 9, 8, 7, 5, 3, 16, 16, 16, 16, 16, 16, 16, 16 } ; static yy_state_type yy_last_accepting_state; static char *yy_last_accepting_cpos; ... #define YY_RULE_SETUP \ YY_USER_ACTION YY_DECL { register yy_state_type yy_current_state; register char *yy_cp, *yy_bp; register int yy_act; #line 18 "dame1.l" #line 536 "lex.yy.c" if ( yy_init ) { yy_init = 0; #ifdef YY_USER_INIT YY_USER_INIT; #endif if ( ! yy_start ) yy_start = 1; /* first start state */ if ( ! yyin ) yyin = stdin; if ( ! yyout ) yyout = stdout; if ( ! yy_current_buffer ) yy_current_buffer = yy_create_buffer( yyin, YY_BUF_SIZE ); yy_load_buffer_state(); } while ( 1 ) /* loops until end-of-file is reached */ { yy_cp = yy_c_buf_p; /* Support of yytext. */ *yy_cp = yy_hold_char; /* yy_bp points to the position in yy_ch_buf of the start of * the current run. */ yy_bp = yy_cp; yy_current_state = yy_start; yy_match: do { register YY_CHAR yy_c = yy_ec[YY_SC_TO_UI(*yy_cp)]; if ( yy_accept[yy_current_state] ) { yy_last_accepting_state = yy_current_state; yy_last_accepting_cpos = yy_cp; } while ( yy_chk[yy_base[yy_current_state] + yy_c] != yy_current_state ) { yy_current_state = (int) yy_def[yy_current_state]; if ( yy_current_state >= 17 ) yy_c = yy_meta[(unsigned int) yy_c]; } yy_current_state = yy_nxt[yy_base[yy_current_state] + (unsigned int) yy_c]; ++yy_cp; } while ( yy_base[yy_current_state] != 19 ); yy_find_action: yy_act = yy_accept[yy_current_state]; if ( yy_act == 0 ) { /* have to back up */ yy_cp = yy_last_accepting_cpos; yy_current_state = yy_last_accepting_state; yy_act = yy_accept[yy_current_state]; } YY_DO_BEFORE_ACTION; do_action: /* This label is used only to access EOF actions. */ switch ( yy_act ) { /* beginning of action switch */ case 0: /* must back up */ /* undo the effects of YY_DO_BEFORE_ACTION */ *yy_cp = yy_hold_char; yy_cp = yy_last_accepting_cpos; yy_current_state = yy_last_accepting_state; goto yy_find_action; case 1: YY_RULE_SETUP #line 19 "dame1.l" ; /* Blanks und Tabs werden ueberlesen */ YY_BREAK case 2: YY_RULE_SETUP #line 20 "dame1.l" {return(ZEILENENDE);} YY_BREAK case 3: YY_RULE_SETUP #line 21 "dame1.l" {return(ZUG);} YY_BREAK case 4: YY_RULE_SETUP #line 23 "dame1.l" ECHO; YY_BREAK ....
In der Vorlesung Programmieren 3 wurde das Beispiel durchgespielt, einen automatischen Damespieler mittels eines Mealy-Automaten zu simulieren. In diesem Fall braucht man keinen Parsergenerator, sondern man benutzt einen Simulator für beliebige Programme endlicher Automaten.
Aus praktischer Sicht ist es allerdings in der Regel einfacher, den regulären Ausdruck mittels flex zu formulieren als das entsprechende Programm für einen endlichen Automaten zu beschreiben.
Für diesen Abschnitt siehe auch [Alexander ASTEROTH/Christel BAIER 2002:Kap.6].
Die mit deterministischen endlichen Automaten beschreibbaren Sprachen lassen sich auch mit einfachen regulären Ausdrücken beschreiben.
Zu jedem DFA(a) gibt es ein TRE(s) mit LDFA = L(s)
Die mit nichtdeterministischen endlichen Automaten beschreibbaren Sprachen lassen sich auch mit deterministischen endlichen Automaten beschreiben.
Zu jedem NFA(a) gibt es einen äquivalenten DFA(a)
Es gibt eine Folge von Sprachen Ln (mit n ∈ Nat), die durch NFAs der Grösse Ο(n) akzeptiert werden, während jeder DFA für Ln mindestens Ω(2n) Zustände hat. (Für die Notation Ο(n) und Ω(2n) siehe Big-Oh, Omega).
Einige Fragen
Gegeben sei folgender Text: "Im Rahmen der Theorie der formalen Sprachen nehmen die regulären Ausdrücken in der Chomsky-Hierarchie die unterste Stufe ein". Auf welche Elemente dieses Textes trifft die Bezeichnung Token zu? Welche andere Bezeichnung gibt es noch für die Bezeichnung Token?
Wie verhalten sich die Typ3-Sprachen zu den regulären Ausdrücken?
Wie würden Sie eine induktive Defintion einer Menge von regulären Ausdrücken hinschreiben?
Welche Aufgabe erfüllen Scanner?
Was versteht man unter einem Scanner Generator?
Welche Aufgaben erfüllen die flex-Beschreibungsdateien ?
Geben Sie die Struktur von flex-Beschreibungsdateien an.
Was ist ein Pattern?
Welche Aufgabe erfüllt eine Aktion im Kontext eines Pattern?
Welche Eigenschaften einer Turingmaschine muss man entfernen, um einen endlichen Automaten zu bekommen?
Geben Sie eine formale Definition eines endlichen Automaten an.
Was unterscheidet einen deterministen endlichen Automaten (DFA) von einem MEALY-Automaten bzw. von einem MOORE-Automaten?
Was versteht man unter der Ableitung bei einem endlichen deterministischen Automaten?
Wie definiert man die durch einen endlichen deterministischen Automaten A definierte Sprache L(A)?
Worin unterscheidet sich ein endlicher deterministischer Automat von einem nichtdeterministischen endlichen Automaten
Worin liegt der Unterscied zwischen einem Mealy-Automaten als durch flex generierten Scanner und einem Mealy-Automaten Simulator?
Formal sind DFAs und NFAs äquivalent. Wie unterscheiden sie sich aber im Laufzeitverhalten?
Einige Aufgaben
Gegeben sei die Sprache L(g4,3) = {anne, anke, abzug, ablage}. Geben sie einen regulären Ausdruck an, der diese Sprache beschreibt.
Gegeben sind folgende Klassen von Ausdrücken: Namen (z.B. "Hans"), ganze Zahlen (z.B. "101", "2344") , Fliesskommazahlen (z.B. "20.33"), Fliesskommazahlen mit Exponenten (z.B. "2.5 e5"). Geben Sie für jede dieser Ausdrucksklasse einen regulären Ausdruck an.
Schreiben Sie ein flex-Programm, das die Ausdrucksklassen aus der vorausgehenden Aufgabe erkennen kann, (i) als ein Stand alone Programm, (ii) als eine Funktion, die von einem eigenständigen Hauptprogramm aus als Funktion aufgerufen wird.
Definieren Sie für jede Ausdrucksklasse aus Aufgabe 2 einen endlichen Automaten: (i) mittels eines Zustandsgraphen, (ii) als formale Definition.
Geben Sie für jeden der zuvor definierten Automaten Aleitungen zu folgenden terminalen Ausdrücken an: "Dampfmaschine", "1004", "21.76", "-2.53e3".
Versuchen Sie mit eigenen Worten eine Argumentationslinie zu entwickeln, warum ein DFA reguläre Ausdrücke erkennen kann.
Versuchen Sie mit eigenen Worten eine Argumentationslinie zu entwickeln, warum man die Menge der Zeichenketten, die man mit einem DFA erkennen kann, durch einen regulären Ausdruck erkennen kann.
Versuchen Sie mit eigenen Worten eine Argumentationslinie zu entwickeln, warum ein NFA sich auf einen DFA zurückführen lässt.
Versuchen Sie mit eigenen Worten eine Argumentationslinie zu entwickeln, warum ein DFA sich zu einem NFA erweitern lässt.