
|
|
|
I-RT REALZEITSYSTEME WS0304
|
In der letzten Vorlesung wurde die Dimension der Zeit parallel zur logischen Dimension eingeführt. Die Zeit ist extern zur Logik. Es wurde aufgezeigt, wie man technisch Zeit im Computer erzeugen bzw. messen kann. Parallel wurde das Konzept der Tasks und der Interrupts eingeführt. Schon hier konnte man im Wechselspiel von Interrupts, Deadlines und Ausfühungszeiten ein potentielles Konfliktfeld erkennen. Es wurde dann auf die Notwendigkeit hingewiessen, zur Erfassung des realen Zeitbedarfs, ausgehend von den höchsten Abstraktionseben die Projektion in die jeweils tiefere Realisierungseben zu klären, um so zu verbindlichen Aussagen über Ressourcenbedarf zu kommen. Auf die Schwierigkeit bzw. Unmöglichkeit, dieses zu tun, wurde hingewiessen.
Gegenstand der heutigen Vorlesung ist die Modellierung von Planugsalgorithmen zur Vermeidung von Zeitkonflikten.
Will man Planungsalgorithmen zur Vermeidung von Zeitkonflikten modellieren, dann muss man zunächst klären, welches die 'Mitspieler' im Spiel sind, welche Eigenschaften haben diese, und wie lassen sich diese kombinieren. Die Gesamtheit solcher Akteure und ihrer Eigenschaften nennen wir ein Paradigma (im Englischen stattdessen oft 'framework', nicht 'paradigm').
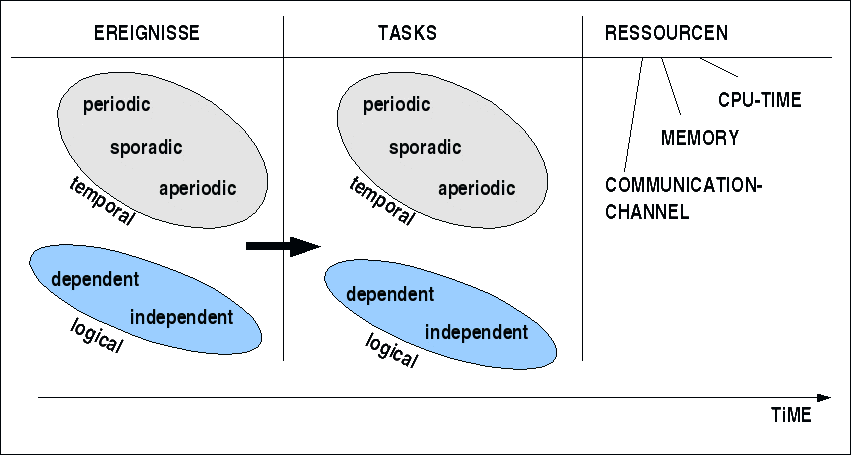
Paradigma Realzeitsysteme
Innerhalb des Paradigmas Realzeitsysteme bilden die Ereignisse die Umgebung des Systems erweitert um die Dimension der Zeit, innerhalb deren sich Deadlines auszeichnen lassen. Die Menge der Tasks und Ressourcen repräsentieren das System, das auf die Ereignisse unter Berücksichtigung der Deadlines reagieren soll.
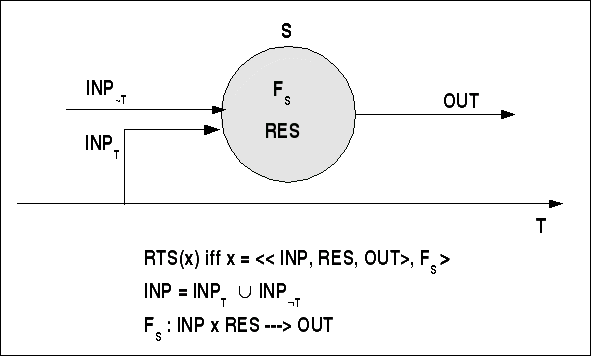
RT-Systeme paradigmatisch
In systemtheoretischer Darstellung haben wir es bei RT-Systemen mit Input-Output-Systemen zu tun, deren Input durch Ereignisse und Zeitmarken gebildet wird; die Zeitmarken repräsentieren eine Zeitdimension. Alle Operationen von RT-Systemen sind an endliche Ressourcen gebunden. Auf der Basis von Input und verfügbaren Ressourcen berechnet dann die Systemfunktion FS jeweils einen Output.
Die Ereignisse kann man nach ihrer 'Herkunft' charakterisieren oder nach dem zeitlichen Muster ihres Auftretens. Nach Herkunft kann man unterscheiden zwischen externen (ein Stimulus), internen (ein Interrupt) und zeitbedingten (ein Taktereignis). Nach dem zeitlichen Muster ihres Auftretens kann man unterscheiden periodische, sporadische oder aperiodische Ereignisse. Periodische Ereignisse sind solche, die nach bekannten, festen Zeitintervallen auftreten. Sporadische Ereignisse treten 'irgendwann' auf, man weiss nicht, wann, aber, wenn sie auftreten, dann vergeht eine bekannte definierte minimale Zeitspanne bis zum nächsten Auftreten. Aperiodische Ereignisse sind hinsichtlich ihres Verhaltens in der Zeit völlig unbestimmt; sie können zu beliebigen Zeitpunkten mit beliebigen Intervallen auftreten. Weitere Charakterisierung von Ereignissen ist möglich, z.B. eine Charakterisierung bzgl. der Abhängigkeit der Ereignisse untereinander. Weitere häufig vorkommende Unterscheidungen sind z.B. auch gebundene Ereignisse; dies sind solche, die entweder mit einer minimalen oder einen maximalen Zeit zwischen ihrem auftreten bschreibbar sind. Ferner gibt es noch die Unterscheidung gehäufte ('bursty') Ereignisse. Diese sind gekennzeichnet durch ein Häufungsintervall ('burst interval') und eine Häufungsgrösse ('burst size'); beide Grössen zusammen liefern die Häufungsdichte ('burst density'). Ein Beispiel wäre eine Anzahl von 50 Transaktionen innerhalb von 1 Sekunde, wobei das genaue Auftreten dieser Transaktionen innerhalb dieser Sekunde offen ist. Statt von aperiodischen Ereignissen kann man dann auch von ungebundenen Ereignissen sprechen; diese haben keinerlei Beschränkungen.
Die Ressourcen des Systems werden gebildet durch alle Betriebsmittel, die vom System in Anspruch genommen werden. Am wichtigsten sind hier natürlich die verfügbare CPU-Zeiten, die verfügbaren Speicher und Komunikationskanäle mit den daran geknüpften Transaktionszeiten. Zu beachten sind auch Latenzzeiten hrvorgerufen z.B. durch Unterbrechungen ('interrupts'), Speicherzugriffe, komplexe Befehle (wie Divison), Sprünge und damit verbundene Umgruppierungen in der CPU-Pipeline) oder auch Umschaltzeiten durch Kontextwechsel). Welche Systemfunktion auch immer ausgeführt werden mag, die durch die Ressourcen vorgegebenen Eckwerten können nicht unterlaufen werden und müssen daher vollständig in der Analyse eines Realzeitsystems einmgebracht werden.
Die Systemfunktion FS wird gebildet durch die Menge der Tasks und deren Verwaltung. Die Verwaltung der Tasks --meist Scheduling genannt-- hat darüber zu entscheiden, welcher Task bei welchem Ereignis welche Ressource zugeteilt bekommt. Dabei ist zu beachten, dass die Task-Verwaltung selbst auch Ressourcen benötigt! In einem schlecht aufgesetzten System kann die Task-Verwaltung u.U. mehr Ressourcen benötigen als die Tasks selbst (Es sei hier nochmals erinnert an den Begriff des WCAO := Worst Case Administrative Overhead aus der vorausgehenden Vorlesung).
Im Falle der Tasks sind zwei Unterscheidungen wichtig: ob ein Task T von einem Task T' abhängig ist oder nicht, sprich unabhängig ist, oder ob ein Task während seiner Ausführung unterbrochen werden darf --Prememption-- oder nicht.
Unter Berücksichtigung der hier genannten Eigenschaften wären also Systeme mit Systemfunktionen, die nur unabhängige Tasks zulassen, die nicht preemptiv sind (nicht unterbrochen werden dürfen), die 'theoretisch einfachsten' Systeme.
Auch im Bereich der Tasks ist die Unterscheidung in periodische, sporadische sowie aperiodische üblich. Die Bedeutung ist analog zur Menge der Ereignisse.
Für manche Analysen erweist es sich als hilfreich, wenn man den Begriff des 'Task' nochmals weiter herunterbricht auf das Konzept der Aktion als kleinstmöglichster Analyseeinheit. Eine Aktion selbst ändert laut Definition keine Ressourceneinstellung, wohl aber beginnen und enden Aktionen mit sogenannten Planungs-Punkten ('scheduling points'). Die Planungspunkte korrelieren mit Zeitpunkten, an denen Entscheidungen bzgl. Ressourcennutzung vorgenommen werden können (z.B. Änderung der Priorität, Start/Stopp von I/O-Aktivitäten, Synchronisierung mit anderen Aktionen).
Schliesslich muss man die Typen der Interaktion der Tasks/Aktionen festlegen. Mindestens zwei Typen erweisen sich als wichtig: in einer sequentiellen ('sequential') Ordnung folgen die Tasks einer nach dem anderen; in einer parallelen ('perallel') Ordnung können die Tasks zeitlich gleichzeitig auftreten. Formal kann man die Menge der Tasks und deren Anordnung als Graphen repräsentieren.
TGRAPH(g) iff t = < < K,O >, TU>
mit
K := Endliche Menge von Knoten ('nodes', 'vertices')
O = {s,p}; Ordnungstyp s := sequentiell, p := parallel
TU subset K x O x K; eine Taskunit besteht also aus zwei Tasks die entweder sequentiell oder parallel angeordnet sind.
Beispiele:
<t1,s,t2 > auch geschrieben als t1 --> t2
<t1,p,t2 > auch geschrieben als t1 || t2
Man kann dann Operatoren definieren, die solche Tasksunits dann zu kompletten Graphen 'zusammenbauen', z.B.:
A --> ( B || (C --> D) || ( E --> F --> G )) --> H
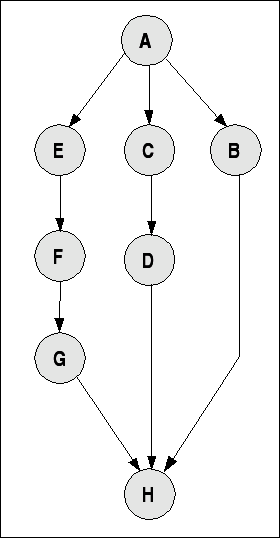
Einfacher Taskgraph
Da wir schon wissen, dass ein Task mit seinen Aktionen nicht nur eine rein 'logische' Grösse ist, sondern unterschiedlichste Ressourcen benötigt, die wiederum eine Auswirkung auf den Zeitbedarf haben, muss man den Taskgraphen mit zusätzlichen Informationen anreichern (siehe Bild):
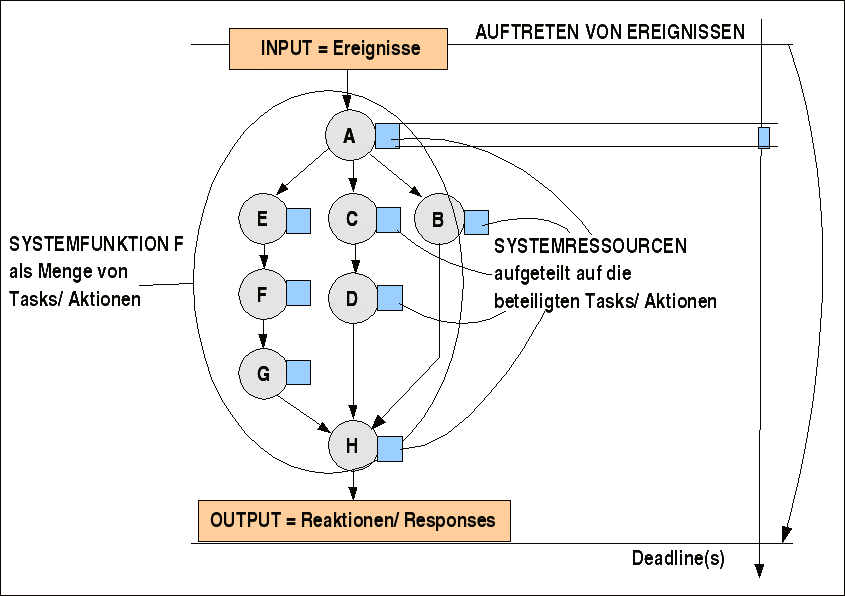
Angereicherter Taskgraph
Für jede Aktion muss eine Reihe von Eigenschaften geklärt werden, die die Basis für die weitere Analyse bilden. Die wichtigsten Eigenschaften sind hier aufgeführt:
|
RESSOURCEN |
Welche Ressourcen eine Aktion benötigt, z.B. CPU, Datenobjekt, Device, Bus, LAN, anderes |
|
PRIORITÄT |
Prioritäten sind geordnete Werte, die bei der Zuteilung von Ressourcen benutzt werden, um Präferenzen zu realisieren. Z.B. (höchster Wert zuerst) Hardware, Kernel, very high, high, medium, low, very low, +. '+' wird benutzt, um anzuzeigen, dass die Priorität von einer vorausgehenden Aktion geerbt wird. |
|
NUTZUNGSZEIT |
Jene Zeit ('usage', 'time used'), für die eine Aktion eine Ressource benötigt, wenn sie nicht konkurrieren muss. Falls die Ressource eine CPU ist, spricht man von Ausführungzeit ('execution time'). Gewöhnlich wird die 'worst-case' Zeit genommen; es gibt aber auch Fälle, wo eine durchschnittliche Zeit ('average time') nützlich ist. |
|
RESSOURCEN-ALLOKATIONS-POLICY |
Diese ist abhängig von der jeweiligen Ressource.
|
|
EXKLUSIVITÄT |
Kann die Aktion die Ressourcen alleine benutzen oder muss die Aktion die Ressourcen mit anderen Aktionen teilen. |
|
WELCHER JITTER |
Man muss festlegen, welche Art von Jitter --falls überhaupt-- berücksichtigt werden soll (s.u.). |
Eine andere bewährte Darstellungsform ist die Tabelle. Sehr ausführliche Darstellungen findet man z.B. in dem exzellenten Hanbuch [Mark H.KLEIN et al. 1993:3-35ff]. Wir übernehmen für unsere Zwecke eine vereinfache Form, die bei [Mark H.KLEIN et al. 1993:3-40] 'technique table' heisst; wir nennen sie analog technische Tabelle
| EVENT ID (e) | ARRIVAL PERIOD (T) | ACTION ID | EXECUTION TIME (C) | PRIORITY (P) | BLOCKING DELAYS (B) | DEADLINE (D) |
| e1 | 40 | a1 | 4 | v.high | 0 | 40 |
| e2 | 150 | a2 | 10 | high | 15 | 150 |
| e3 | 180 | a3 | 20 | medium | 0 | 180 |
| e4 | 250 | a4 | 10 | low | 5 | 250 |
| e5 | 300 | a5 | 80 | v.low | 0 | 300 |
Aus den zuvor geschilderten Rahmenbedingungen ergeben sich eine Reihe von fundamentalen Begriffe, die für die Beschreibung und Berechnung von Zeitverhältnissen wichtig sind.
Zuvor wurde schon der Begriff Jitter definiert. Neben dem Jitter jitterS, der eine aktuelle Eigenschaft eines Realzeitsystems S darstellt, muss man noch die Jittertoleranz jeS für ein System S berücksichtigen. Jittertolranz jeS repräsentiert eine Anforderung von der Problemstellung an das System. Sie sagt aus, welche Abweichung maximal zulässig ist, als es muss gelten
jitterS < jeS
Dabei wird zwischen einer absoluten und einer relativen Jittertoleranz unterschieden. Die relative Jittertoleranz bezieht sich nur auf den Zeitpunkt eine Aktion später, also
ti+1 = ti T + jeS
Die absolute Jittertoleranz bezieht sich auf alle Zeitpunkte seit der ersten Aktion, also
ti+1 = ( t1 + (i * T) + jeS )
Während ein relativer Jitter von z.B. 0.1 s nicht viel sein mag kann dieser aber nach 10 Aktionen schon zu 1 s kumulieren und sehr schnell das erlaubte Mass sprengen. Ein absoluter Jitter von 0.1 s für alle bisherigen Aktionen ist dagegen ein klarer Referenzpunkt.
Zu einem Ereignis ei gehört immer eine relative Deadline Di, das ist die höchste erlaubte Verzögerung bis zur Ausführung des zugehörigen Tasks. Ereignis ei zusammen mit der Deadline Di bilden ein Zeitfenster (t(ei),Di).
Jeder Task i hat eine spezifische Ausführungszeit ('execution time') ci. Die restliche Ausführungszeit zum Zeitpunkt t ist C(t) (0 < C(t) < C
Ein periodisches Ereignis ei hat eine Periode pi (oder auch Ti).
Mit der Auftretenszeit ('release time', request time', 'arrival time', 'ready times') ri eines Ereignisses ei ist der Zeitpunkt gemeint, an dem ein Ereignis einem System bekannt wird und einen zugehörigen Task anfordert. Wenn ri.0 die Auftretenszeit des Ereignisses ei zum 0-ten Zeitpunkt ist, dann gilt die Auftretenszeit vom k-ten sukzessiven Ereignis ist: ri.k = ri.0 + k*Ti
Neben der relativen Deadline Di eines Ereignisses ei gibt es auch die absolute Deadline di = ri + Di. Die restliche relative Deadline zum Zeitpunkt t ist D(t) = d -t.
Ein Task ist 'well formed' wenn gilt: 0 < C < D < T.

Taskmodell Symbole
Ausgehend von der absoluten Deadline di und der Ausführungszeit ci eines Tasks kann man die laxity li des Tasks berechnen bezogen auf den aktuellen Zeitpunkt: li = di - ci
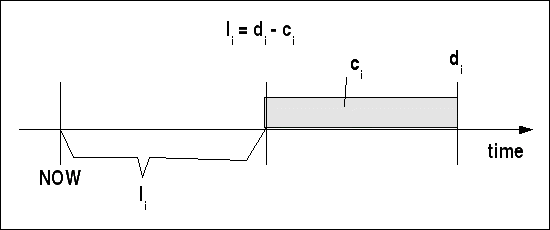
Laxity
Die restliche nominale Laxity L(t) berechnet sich mit L(t) = D(t) - C(t) oder L(t) = r+D-t-C(t) (siehe Beispiel mit LLF-Algorithmus unten).
Mit der Periode kann ein Offset verbunden sein, z.B. 3 msec offset nach der Periode. Ferner kann auch das durch das Ereignis verursachte Signal einen Jitter haben. Wird eine Nachricht zur Netzwerk-Queue gesendet, spricht man auch von einer Release time; zusammengenommen ergibt sich also die Formel (bei perfekter Zeitmessung):
Release timen= (n*period) + offset + jitter
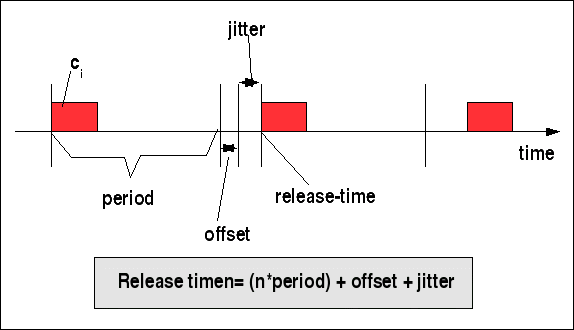
Periode
s ist die Startzeit einer Task Ausführung
e ist die Endzeit einer Task Ausführung
TR = e-s ist die Task-Antwortzeit.
Die Auslastung bzw. den Nutzungsgrad ('utilization') myi bezogen auf einen einzelnen Task i und eine CPU bekommt man durch myi = ci / Ti. Die Auslastung gibt an, zu wieviel Prozent ein Task i die Zeit bis zu seiner 'Wiederkehr' verbraucht. pi ist die Periode des Tasks.
Die totale Auslastung ('utilization') U(S,n) eines Systems S erhält man dann durch den Ausdruck
U(S,n) = SUM(i=1,n) ci/pi
mit
n := Anzahl der verschiedenen Tasks (bzw. Aktionen). Es muss gelten U(S,n) < 1
Für den Prozessor Beladungsfaktor ('proessor load factor') gilt
ch(S,n) = SUM(i=1,n) ci/di
Für den restlichen Prozessor Beladungsfaktor gilt
CH(S,n,t) = SUM(i=1,n) Ci(t)/Di(t)
Im Fall von geteilten Ressourcen kann es passieren, dass ein Task tj einen Task ti blockiert. Daraus entsteht eine Verzögerungszeit. Es soll Bi die gesamte Verzögerungszeit sein, die ein Task Task ti erfahren kann. Dann kann man die totale Verzögerungszeit B(S,n) eines Systems S berechnen durch den Ausdruck
B(S,n) = MAX(i=1,n) Bi/pi
mit
n := Anzahl der verschiedenen Tasks (bzw. Aktionen).
Wenn Tasks geswitched werden können (Präemption), dann kann man eine obere Schranke ('upper bound') für die Auslastbarkeit UB(S,n) der Ressourcen berechnen. Die Formel lautet:
UB(S,n)= n(21/n-1)
Der Grenzwert des Ausdrucks liegt bei 0.72.
Planungsperiode ('scheduling period' or 'major cycle' or 'hyper peruid': bei quasi unendlich lang laufenden Prozessen genügt es für die Planung, nur denjenigen Zeitabschnitt zu untersuchen, der sich dann wiederholt. Diese Auswertungsperiode ('evaluation period', 'pseudo-period', 'scheduling period', 'schedule length', 'hyper period') beginnt bei der frühesten Release-Zeit eines Ereignisses und erstreckt sich bis zum {Maximum entweder einer Releasezeit eines periodischen Ereginisses oder der Releasezeit eines aperiodischen Ereignisses + Deadline } plus 2* dem kleinsten gemeinsamen Vielfachen ('Least Common Multiple, LCM') der Perioden der periodischen Tasks.
MAX{ri.0, (rj.0 + Dj)} + 2 * LCM(Ti)
Bei der Analyse von Realzeitsystemen ist es von grundlegendem Interesse, ob die für die Lösung eines Realzeitproblems identifizierten Tasks in der Lage sind, die geforderte aufgabe in der geforderten Zeit zu lösen. Einen Test, der dieses prüft, nennt man einen notwendigen Planbarkeits-Test ('schedulability test'). Mit den bislang eingeführten Begriffen kann man einen ersten einfachen Planbarkeits-Test formulieren.
Nimmt man als Randbedingungen an, dass gilt: (i) Deadlines sind gleich der Periode und die Perioden sind umgekehrt proportional zur Länge der Deadlines, also kürzeste Deadline mit höchster Priorität, dann gilt folgende Gleichung:
U(S,n) + B(S,n) < UB(S,n)
Ist die Gleichung nicht erfüllt, ist eine Planbarkeit nicht gegeben. Ist sie erfüllt, dann kommt es auf die konkrete Ausführung des Algorithmus an, ob sie erfüllt wird; prinzipiell kann sie erfüllt werden.
Hier ist eine Beispielsrechnung auf der Basis der vorausgehenden Tabelle. Man sieht, dass theoretisch die benötigten Nutzungszeiten kleiner sind als die theoretisch ermittelte oberste Grenze.
| EVENT ID (e) | ARRIVAL PERIOD (T) | ACTION ID | EXECUTION TIME (C) | PRIORITY (P) | BLOCKING DELAYS (B) | DEADLINE (D) | U(S,5) | B(S,5) | UB(S,5) |
| e1 | 40 | a1 | 4 | v.high | 0 | 40 | 0,1 | 0 | 5 |
| e2 | 150 | a2 | 10 | high | 15 | 150 | 0,07 | 0,1 | |
| e3 | 180 | a3 | 20 | medium | 0 | 180 | 0,11 | 0 | |
| e4 | 250 | a4 | 10 | low | 5 | 250 | 0,04 | 0,02 | |
| e5 | 300 | a5 | 80 | v.low | 0 | 300 | 0,27 | 0 | |
| 0,58 | 0,1 | 0,74 | |||||||
| 0,68 | 0,74 |
Der nächste Planbarkeitstest hat veränderte Voraussetzungen: (i) die Deadlines können kürzer sein als die Periode und (ii) die Prioritäten sind nicht monoton an der Länge der Deadline fixiert und (iii) es wird die Planbarkeit nur für einzelne Ereignisse ermittelt.
Als Beispielmenge dient die folgende Tabelle:
| EVENT ID (e) | ARRIVAL PERIOD (T) | ACTION ID | EXECUTION TIME (C) | PRIORITY (P) | BLOCKING DELAYS (B) | DEADLINE (D) |
| e1 | 40 | a1 | 4 | v.high | 0 | 10 |
| e2 | 300 | a2 | 80 | high | 0 | 300 |
| e3 | 180 | a3 | 20 | medium | 0 | 140 |
| e4 | 250 | a4 | 10 | low | 5 | 150 |
| e5 | 150 | a5 | 10 | v.low | 0 | 150 |
Die Berechnung der Planbarkeit eines einzelnen Ereignisses in solch einem Kontext erfolgt nach folgenden Schritten:
Es soll geprüft werden, ob Ereignis ei planbar ist.
Identfiziere eine Menge (H) von Ereignissen, deren Priorität höher oder gleich der Priorität Pi von ei sind. Teile dann die Menge (H) auf in zwei Mengen (H1) und (Hn). (H1) enthält solche Ereignisse, deren Perioden T grösser oder gleich der Deadline Di von ei sind. (Hn) soll solche Ereignisse enthalten, deren Perioden T kleiner als die Deadline Di von ei sind.
Berechne die totale effektive Nutzungszeit fi von Ereignis ei. Diese totale Nutzungszeit setzt sich aus zwei Bestandteilen zusammen: (i) die totale Nutzungszeit der Ereignisse in (Hn), sowie (ii) die Ausführungszeit von ei plus Verspätungszeiten durch Blockaden plus Präemptionszeiten verursacht durch Ereignisse aus (H1), alles dividiert durch die Periode von ei:
fi = SUM(j in (Hn))Cj/Tj + 1/Ti*(Ci + Bi + SUM(k in (H1))Ck)
Berechne die Nutzbarkeitsgrenze U(n,Dti) mit n = Anzahl Elemente in (Hn) + 1 sowie Dti = Di/Ti. Es gilt:
U(n,Dti) =
(i) n*((2*Dti)^1/n -1) +1 - Dti falls 0.5 < Dti < 1.0
(ii) Dti falls 0 < Dti < 0.5
Vergleiche die effektive totale Nutzungszeit von ei mit der oberen Schranke:
fi < U(n,Dti)
Falls fi kleiner oder gleich der Grenze ist, dann kann dieses Ereignis seine Deadline einhalten.
Angewendet auf die vorausgehende Tabelle ergibt dies die folgenden Werte:
| EVENT ID (e) | ARRIVAL PERIOD (T) | ACTION ID | EXECUTION TIME (C) | PRIORITY (P) | BLOCKING DELAYS (B) | DEADLINE (D) |
| e1 | 40 | a1 | 4 | v.high | 0 | 10 |
| e2 | 300 | a2 | 80 | high | 0 | 300 |
| e3 | 180 | a3 | 20 | medium | 0 | 140 |
| e4 | 250 | a4 | 10 | low | 5 | 150 |
| e5 | 150 | a5 | 10 | v.low | 0 | 150 |
| H(e4) = | {e1,e2,e3} | |||||
| H1 = | {e2,e3} | |||||
| Hn = | {e1} | |||||
| c4/t4 = | 0,1 | |||||
| 1/t4 = | 0,0040 | |||||
| Ci + Bi + SUM(k in (H1))Ck = | 115 | |||||
| fi = | 0,56 | |||||
| n = | 2 | |||||
| Dti = Di/Ti = | 0,6 | |||||
| n*((2*Dti)^1/n -1) +1 - Dti = | 0,59 | |||||
| fi < U(n,Dti) = | TRUE |
Das folgende Schaubild gibt einen systematischen Überblick über die unterschiedlichen Varianten, unter denen man einen Plan ('schedule') aufstellen kann.
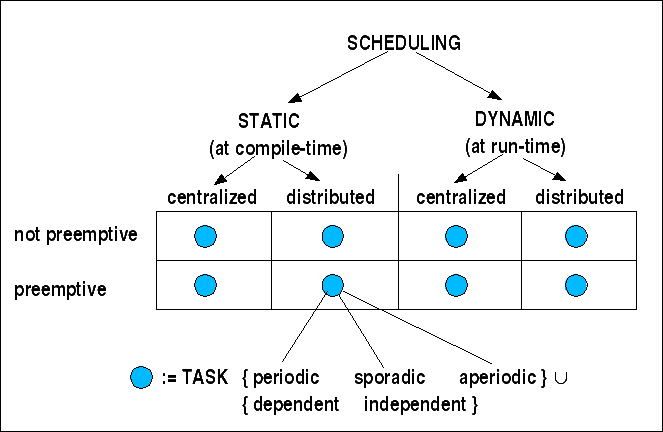
Überblick über Scheduling-Ramenbedingungen
Statisches Scheduling definiert sich über die Tatsache, dass der Zeitpunkt des Auftretens der Ereignisse bekannt ist, d.h. statisches Scheduling behandelt periodische Ereignisse. Entsprechend kann man die zugehörigen Tasks dann auch als periodische Tasks konzipieren.
Obwohl die Aufgabenstellung eines statischen Schedulings auf den ersten Blick 'trivial' erscheinen mag, kann sie doch in den Bereich NP-vollständiger Probleme fallen, nämlich dann, wenn mehrere Prozessoren beteiligt sind und zusätzlich --womöglich-- noch Kommunikationsprozesse organisiert werden müssen.
Da die Voraussagbarkeit ('predictability') die wichtigste Anforderung an Realzeitsysteme ist, ist der Ansatz mit einem statischen Scheduling oftmals der einzige Ausweg, die Komplexität in den Griff zu bekommen. Zum statischen Scheduling gehört es dann, dass man den Ausführungsplan ('schedule') im voraus ('pre-runtime') berechnet und das System dadurch 'off line' compiliert.
So ideal die Annahme periodischer Ereignisse ist, so unflexibel ist diese Annahme für den praktischen Einsatz. Es gibt daher verschiedene Versuche, den Ansatz des statischen Schedulings auszudehnen in Richtung sporadischer Ereignisse. Drei Ansätze seien hier genannt (siehe dazu auch [KOPETZ 1997:239f]):
Man übersetzt sporadische Ereignisse in pseudo-periodische Ereignisse, die Ressourcen für den Fall allokieren, dass ein 'echtes' sporadisches Ereignis auftritt. In einem vordefinierten Umfang kann das System dann auf solche sporadischen Ereignisse ragieren.
Man reserviert einen sporadischen Server-Task für die Bearbeitung sporadischer Ereignisse.
Man unterteilt die verfügbaren Tasks entsprechend typischer Aufgaben in 'Modes', so dass innerhalb eines bestimmtes Modes nur eine Untermenge von Tasks verfügbar sein muss; entsprechend kann man die Schedules für die verschiedenen Modes optimieren.
Im Falle des dynamischen Schedulings ist die Lage nicht so eindeutig, da die Dynamik von unterschiedlichen Faktoren herrühren kann. Der häufigste Faktor ist die dynamische Vergabe von Prioritäten bei präemptiven Systemen. Dynamisches Scheduling würde aus theoretischer Sicht aber auch vorliegen, falls die Tasks sporadisch oder gar aperiodisch wären; da bisher für diese Fälle aber keine befriedigenden dynamischen Lösungen existieren, kommen diese Fälle praktisch nicht vor.
Will man einen Algorithmus für Planung einsetzen, dann müssen vorher zwei Dinge geklärt sein: Abgeschlossenheit und Planbarkeit:
Abgeschlossenheit ('optimality') eines Algorithmus A bedeutet, dass es keinen anderen Algorithmus gibt, der unter den gegebenen Voraussetzungen ein Problem löst, das Algorithmus A nicht auch löst.
Planbarkeit ('schedulability') eines Algorithmus A besagt, dass die von den Ereignissen geforderten Ressourcen im vorgegebenen Rahmen des Algorithmus in allen denkbaren Fällen verfügbar sind.
Der Fall eines statischen Planens mit periodischen Ereignissen (und Tasks) und statischen Prioritäten ist durch folgende Annahmen gekennzeichnet:
Es wird Präemption angenommen und zusätzlich die folgenden 5 Beschränkungen ('restrictions'):
Die Menge der Tasks {Ti} ist periodisch, mit harten Deadlines and keinem Jitter
Die Tasks sind vollständig unabhängig
Die Ausführungszeit ci eines Tasks i ist bekannt und konstant
Kontext-switching benötigt keine Ressourcen; dies soll auch für den Fall gelten, dass die Kontextinformationen über das Netzwerk zu einer anderen CPU geschickt werden.
Prioritäten werden apriori nach einer festen Regel zugeordnet und während des Laufs nicht wieder gändert.
RM := Rate Monotonic
Für die Deadline eines Tasks i gilt: Deadline = Periode, pi = di
Die Policy für die Zuordnung der Prioritäten lautet: Die kürzeste Periode hat die höchste statische Priorität. Die höchste Priorität soll immer zuerst ausgeführt werden.
Die Abgeschlossenheit des RM-Algorithmus lässt sich beweisen (siehe z.B. [COTTET et al. 2001:24ff]).
Für die Planbarkeit gilt die Bedingung (s.o.): U(S,n) < UB(S,n)
Dieses Verfahren garantiert eine Planbarkeit bei einer CPU-Auslastung von 72%. Dies gilt auch bei beliebig gewählten Perioden. Wenn alle Perioden ein Vielfaches der kürzesten Periode sind, dann funktioniert dieser Plan auch bei einer Auslastung der CPU bis zu 100%.
1993 konnten Shih, Liu und Liu zeigen, dass man den RMS-Algorithmus so modifizieren kann, dass man den Auslastungsgrad von 72% auf 84% anheben kann.
Beispiel:
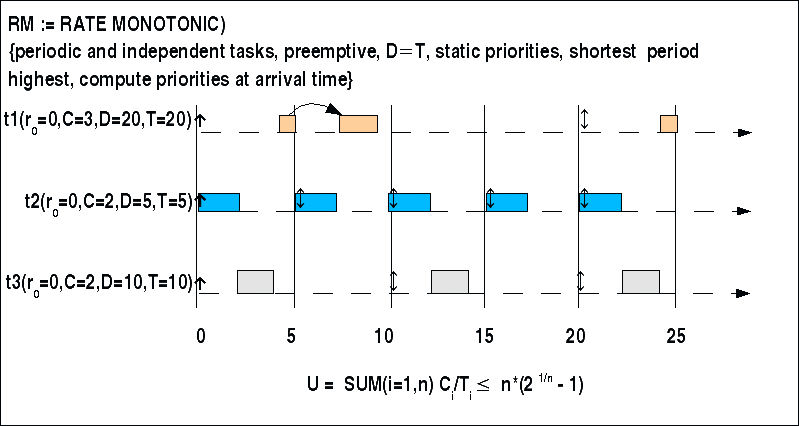
Rate Monotonic, Beispiel
In diesem Beispiel gibt es drei Ereignisse mit zugehörigen Tasks. Das Planbarkeitskriterium ergibt:
3/20 + 2/5 + 2/10 = 0.75
Die obere Schranke liegt bei 0.78. Damit ist das Planbarkeitskriterium erfüllt.
Alle Ereignisse haben die Auftretenszeit ('release time') r=0. Eine Verteilung der Prioritäten anhand der Regel führt dazu dass t2 mit T=5 die höchste Priorität bekommt, dann t3 mit T=10 und dann t1 mit T=20.
Eine Anordnung der Tasks aus Anlass des Auftretens der zugehörigen Ereignisse gelingt (siehe Bild). Aufgrund der Prioritäten wird zunächst Task t2 gestartet, anschliessend t3. Dann kann Task t1 beginnen; aber während seiner Ausführungszeit startet t2 wieder. Wegen der höheren Priorität wird t3 daher unterbrochen ('preempted') und zuerst Task t2 ausgeführt. Da nach Abschluss von t2 kein neuer Task t3 ausgeführt werden muss, kann Task t1 seine Ausführung fortsetzen und beenden.
DM := Deadline Monotonic or ID := Inverse Deadline
Für die Deadline eines Tasks i gilt: Deadline < Periode, pi < di
Die Abgeschlossenheit des DM-Algorithmus lässt sich beweisen (siehe z.B. [COTTET et al. 2001:30]). Sie gilt für alle Algorithmen mit fester Priorität und einer Deadline kleiner-gleich der Periode.
Für die Planbarkeit gilt abweichend vom Rate-Monotonic Algorithmus als hinreichendes Kriterium:
SUM(i=1,n) ci/di <(21/n-1)
Wird dieses Kriterium erfüllt, dann kann es einen ausfhrbaren Plan geben; wird das Kriterium dagegen nicht erfüllt, dann kann es trotzdem in einzelnen Fällen einen ausführbaren Plan geben (dieser Fall liegt im nachfolgenden Beispiel vor).
Die Policy für die Zuordnung der Prioritäten lautet: Die kürzeste relative Deadline D hat die höchste statische Priorität. Die höchste Priorität soll immer zuerst ausgeführt werden.
Ein Beispiel:
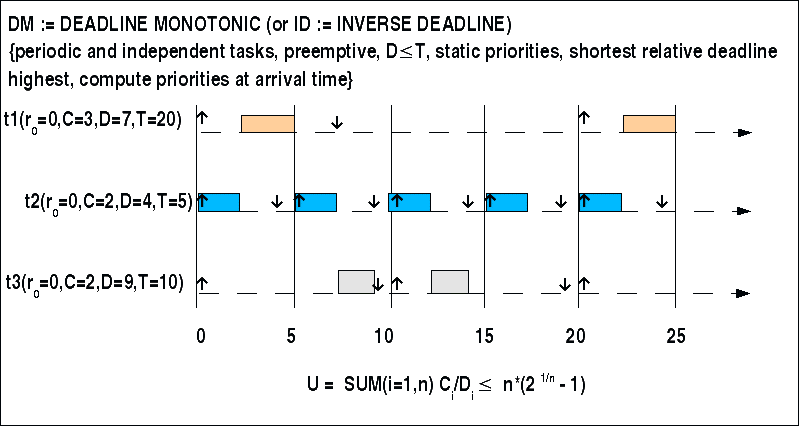
Deadline Monotonic/ Inverse Deadline, Beispiel
In diesem Beispiel gibt es wieder drei Ereignisse mit zugehörigen Tasks. Das Planbarkeitskriterium ergibt:
3/7 + 2/4 + 2/9 = 1.15
Die obere Schranke liegt bei 0.78. Damit ist das Planbarkeitskriterium nicht erfüllt. Es muss also keinen ausführbaren Plan geben; es kann einen geben.
Alle Ereignisse haben die Auftretenszeit ('release time') r=0. Eine Verteilung der Prioritäten anhand der Regel führt dazu dass t2 mit D=4 die höchste Priorität bekommt, dann t1 mit D=7 und dann t3 mit D=9.
Eine Anordnung der Tasks aus Anlass des Auftretens der zugehörigen Ereignisse gelingt (siehe Bild). Aufgrund der Prioritäten wird zunächst Task t2 gestartet, anschliessend t1. Obgleich immer noch t3 wartet, startet bei t=5 nach Beendigung von t1 erst wieder t2 wegen der höheren Priorität. Da nach Abschluss von t2 kein neuer Task t1 ausgeführt werden muss, kann kann endlich Task t3 starten.
Gleicher Ansatz wie bei DM-Algorithmus.
Im Netzwerk gibt es keine Präemption, deswegen sollten alle Perioden sehr kurz sein. Prioritäten werden hier nach der Länge der Perioden bestimmt.
In diesem Fall müssen die CPUs die Kapazität des Netzwerks nutzen. Um dies zu rekonstruieren tue das folgende:
Lege für jede Nachricht die Übertragungszeit im Netz fest (z.B. mit Hilfe einer Tabellenkalkulation)
Lege für jede CPU fest, wieviel Zeit sie benötigt, um eine Nachricht zu berechnen und zu senden
Lege für jede CPU fest, wieviel Zeit sie benötigt, um eine Nachricht zu empfangen und zu verarbeiten.
Wiederhole den Prozess so lange, bis der Plan keine doppelt gebuchten Ressourcen umfasst
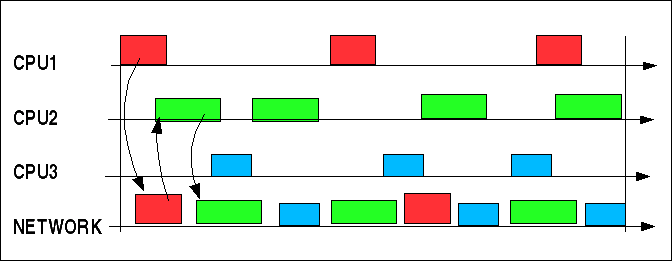
Verteiltes statisches Planen
Wenn man für mögliche Übertragungsprobleme genügend grosse Pufferzeiten einplant, dann ist dieses Verfahren sehr stabil. Bei jeder Änderung muss allerdings der gesamte Plan überarbeitet werden.
Es gelten die Annahmen:
Es wird Präemption angenommen, eine dynamische Prioritätenvergabe und zusätzlich die folgenden 5 Beschränkungen ('restrictions'):
Die Menge der Tasks {Ti} ist periodisch (kann auch nicht periodisch, siehe weiter unten!), mit harten Deadlines and keinem Jitter
Die Tasks sind vollständig unabhängig
Für die Deadline eines Tasks i gilt: Deadline %lt; Periode, pi %lt; di
Die Ausführungszeit ci eines Tasks i ist bekannt und konstant
Kontext-switching benötigt keine Ressourcen; dies soll auch für den Fall gelten, dass die Kontextinformationen über das Netzwerk zu einer anderen CPU geschickt werden.
Prioritäten-Policy: Die höchste Priorität hat jeweils der Task mit der aktuell nächsten absoluten Deadline d; die höchste Priorität wird zuerst ausgeführt.
Die Abgeschlossenheit des EDF-Algorithmus lässt sich beweisen in Form einer 'Machbarkeit' ('feasibility'), d.h. wenn es überhaupt einen ausführbaren Plan gibt, dann wird der EDF-Algorithmus ihn finden. (siehe z.B. [COTTET et al. 2001:31]).
Für die Planbarkeit mit periodischen Tasks gilt als notwendige Bedingung:
U(S,n) < 1 mit U(S,n) = SUM(i=1,n) ci/pi
Für die Planbarkeit mit periodischen und aperiodischen Tasks (hybride Taskmenge) gilt als hinreichende Bedingung:
Ud(S,n) < 1 mit U(S,n) = SUM(i=1,n) ci/di
Ein Beispiel:

EDF, Beispiel
In diesem Beispiel gibt es drei Ereignisse mit zugehörigen Tasks. Das Planbarkeitskriterium ergibt:
3/20 + 2/5 + 1/10 = 0.65
Die obere Schranke liegt bei 1. Damit ist das Planbarkeitskriterium erfüllt. Es sollte also einen ausführbaren Plan geben.
Alle Ereignisse haben die Auftretenszeit ('release time') r=0. Eine Verteilung der Prioritäten anhand der Regel führt dazu dass t2 mit D=4 die höchste Priorität bekommt, dann t1 mit D=7 und dann t3 mit D=8.
Eine Anordnung der Tasks aus Anlass des Auftretens der zugehörigen Ereignisse gelingt (siehe Bild). Aufgrund der Prioritäten wird zunächst Task t2 gestartet, anschliessend t1. Bei t=5 startet dann nach Beendigung von t1 nicht zuerst wieder t2, der zu diesem Zeitpunkt die absolute Deadline d2 = 9 hat, sondern Task t3, der zum Zeitpunkt t=5 die absolute Deadline d3=8 hat. Nach Abschluss von t3 gibt es nur Task t2, der wartet, also kann dieser ausgeführt werden. Der Rest ergibt sich.
Es gelten die Annahmen:
Es wird Präemption angenommen, eine dynamische Prioritätenvergabe und zusätzlich die folgenden 5 Beschränkungen ('restrictions'):
Die Menge der Tasks {Ti} ist periodisch, mit harten Deadlines and keinem Jitter
Die Tasks sind vollständig unabhängig
Für die Deadline eines Tasks i gilt: Deadline %lt; Periode, pi %lt; di
Die Ausführungszeit ci eines Tasks i ist bekannt und konstant
Kontext-switching benötigt keine Ressourcen; dies soll auch für den Fall gelten, dass die Kontextinformationen über das Netzwerk zu einer anderen CPU geschickt werden.
Prioritäten-Policy: Die höchste Priorität hat jeweils der Task mit der aktuell kleinsten Laxity; die höchste Priorität wird zuerst ausgeführt. Während der Ausführung eines Tasks i bleibt die Laxity von i konstant. Dadurch ist es möglich, dass während der Ausführung ein anderer Task j plötzlich eine kleinere Laxity als der gerade in Arbeit befindliche Task bekommt; in diesem Fall müsste ein Kontextwechsel stattfinden. Diese Eigenschaft des LL-Verfahrens kann zu grossem Overhead führen. Hier wird --wie in den vorausgehenden Beispielen-- angenommen, dass die Laxity bei jedem Auftreten eines neuen Ereignisses neu berechnt wird.
Die Abgeschlossenheit des LL-Algorithmus lässt sich beweisen [COTTET et al. 2001:32]).
Für die Planbarkeit mit periodischen Tasks gelten die gleichen Bedeigungen wie für EDF.
Im Falle eines einzelnen Prozessors ist die Leistung von EDF und LL etwa gleich; im Falle von Multiprozessoren ist LL etwas flexibler als EDF.
Ein Beispiel:
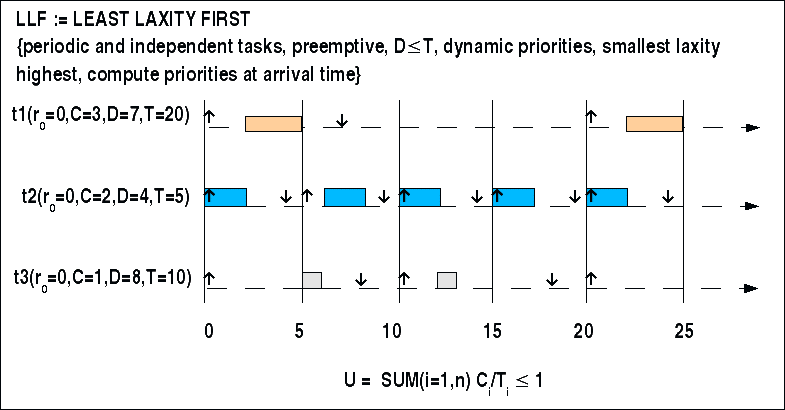
LLF, Beispiel
In diesem Beispiel gibt es drei Ereignisse mit zugehörigen Tasks. Das Planbarkeitskriterium ergibt (wie im Falle des vorausgehenden EDF-Algorithmus):
3/20 + 2/5 + 1/10 = 0.65
Die obere Schranke liegt bei 1. Damit ist das Planbarkeitskriterium erfüllt. Es sollte also einen ausführbaren Plan geben.
Alle Ereignisse haben die Auftretenszeit ('release time') r=0. Eine Verteilung der Prioritäten anhand der Regel führt dazu dass L(t2) mit 4-2=2 die höchste Priorität bekommt, dann t1 mit L(t1) = 7-3 = 4 und dann t3 mit L(t3) = 8-1 = 7.
Eine Anordnung der Tasks aus Anlass des Auftretens der zugehörigen Ereignisse gelingt (siehe Bild). Aufgrund der Prioritäten wird zunächst Task t2 gestartet, anschliessend t1. Bei t=5 gibt es zwei Möglichkeiten. t2 sollte neu starten und hat eine Laxity L(t=5) = r+D-t-C(t) = 5 + 4 - 5 - 2 = 2 und t3 hat eine Laxity L(t=5) = 0 + 8 - 5 - 1 = 2. Für solche fälle benötigt man entweder eine zusätzliche Regel oder man fällt eine Zufallsentscheidung. Im Bild wurde angenommen, dass der länger wartende Task vorgezogen wird. Nach Abschluss von t3 gibt es nur Task t2, der wartet, also kann dieser ausgeführt werden. Der Rest ergibt sich.
Eine mögliche Verteilung der Eigenschaften könnte sein:
Jeder Node benutzt ein EDF-CPU-Scheduling
Jeder Node ordnet ausgehenden Nachrichten eine Priorität mit EDF oder LLF zu
Jeder Node, der eine Nachricht empfängt gibt den durch diese Nachrichten ausgelösten Tasks eine Priorität mit EDF
Dieses Scheduling ist gewöhnlich nicht optimal; die beteiligten CPUs sind streckenweise unterbeschäftigt.
Nachteile von EDF/LL sind,
dass es sich nicht immer in allen Fällen beweisen lässt, dass es in allen Fällen funktioniert; auch wenn es eine zeitlang funktioniert, bedeutet dies nicht, dass es Situationen geben kann, in denen es nicht funktioniert.
Man benötigt grundsätzlich dynamische Prioritäten.
Speziell der LLF-Algorithmus hat eine Schwachstelle darin, dass er zur Darstellung der Zeitsruktur in manchen Fällen zu viele Bits benötigt und damit zu viele Ressorcen benötigt.
Es soll hier auch noch kurz der Fall betrachtet werden, dass neben periodischen Ereignissen auch aperiodische Ereignisse auftreten. Sofern es sich um Ereignisse mit harten Dealines handelt besteht eine Strategie ihrer Behandlung darin, für jedes einzelne Auftreten zu prüfen, ob der neue Task sich mit dem aktuell aufgestellten Plan 'verträgt'; falls positiv, wird der neue Tasks in den Plan übernommen, falls nicht, muss er zurückgewiessen werden. Für diesen speziellen Fall der Zurückweisung werden oft zusätzliche Ressourcen reserviert, die nur solche zurückgewiessenen Fälle bearbeiten. Konkret heisst dies:
Zum Zeitpunkt t gibt es einen Plan P(t) mit periodischen Tasks und schon eingeplanten aperiodischen Tasks, der entweder nach Deadlines organisiert ist oder nach Laxities.
Wenn ein neuer aperiodischer Task zum Zeitpunkt t eintrifft wird berechnet, wieviel freie ('idle') Zeit die CPU von t bis zur Deadline des neuen Tasks noch besitzt.
Wenn noch genügend CPU-Zeit zur Verfügung steht, dann wird der neue Task in den Plan übernommen; andernfalls zurückgwiessen.
Ein Beispiel:
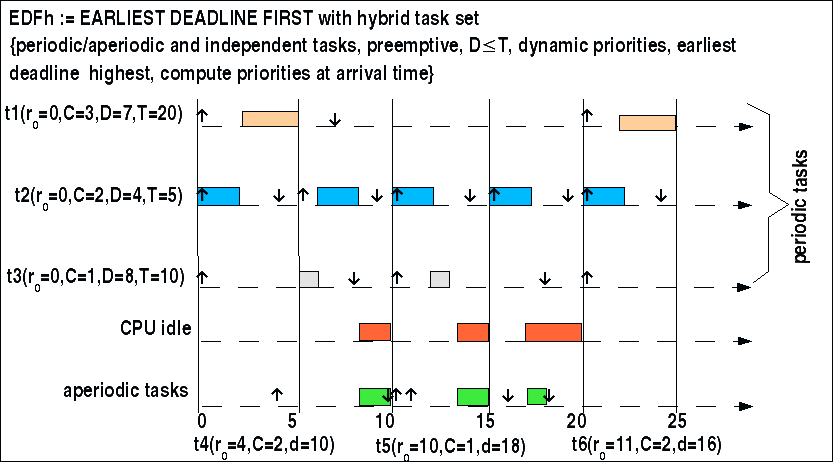
EDF hybrid, Beispiel
In diesem Beispiel gibt es drei periodische und drei aperiodische Ereignisse mit zugehörigen Tasks. Für diesen hybriden Fall kann man das hinreichende Planbarkeitskriterium des EDF-Algorithmus verwenden. Es lautet:
Ud(S,n) < 1 mit U(S,n) = SUM(i=1,n) ci/di
Dies würde ergeben: 3/7 + 2/4 + 1/8 = 1.05 Die obere Schranke liegt bei 1. Damit ist das Planbarkeitskriterium nicht erfüllt, dies bedeutet, dass es keinen ausführbaren Plan geben muss. Im Einzelfall ist zu prüfen, ob es doch gelingt. Da die aperiodischen Ereignisse nicht vorhersagbar sind, ist diese Situation prinzipiell unsicher. Sie könnte nur durch zusätzliches Wissen über Randbedingungen des Auftretens der aperiodischen Ereignisse 'eingegrenzt' werden.
Alle periodischen Ereignisse haben die Auftretenszeit ('release time') r=0. Eine Verteilung der Prioritäten anhand der Regel ist analog dem Fall des EDF-Algorithmus (siehe oben).
Eine Anordnung der Tasks aus Anlass des Auftretens der zugehörigen Ereignisse im Beispiel gelingt (siehe Bild). Dies sagt nichts darüber aus, wie es sich bei dem Auftreten von anderen aperiodischen Ereignissen verhalten würde.
Entsprechend der vorausgehenden Überlegung werden zunächst die periodischen Ereignisse geplant. Dies geschieht analog dem EDF-Beispiel (siehe oben). Nachdem dieser Plan vorliegt --der trotz dem Kriterium einlösbar ist--, werden die Zeiten ermittelt, in denen die CPU untätig ('idle') ist. Dann wird überprüft, welche Tasks der aperiodischen Ereignisse in diesen freien Zeiten ausgeführt werden könnten. Zum Zeitpunkt t=8 beginnt eine freie Zeit. Zu diesem Zeitpunkt wartet der Task t4 auf Ausführung. Diese kann geschehen. Zum Zeitpunkt t=13 gibt es wieder eine freie Zeit. Zu diesem Zeitpunkt warten die Tasks t5 und t6 auf eine Ausführung. Da Task t6 die kürzere Deadline hat, wird dieser zuerst ausgeführt. Zum Zeitpunkt t=17 gibt es wieder eine freie Zeit; jetzt kann der Task t5 abgearbeitet werden.
Bei der Frage, wie man denn nun konkret solch ein Realzeitsystem analysiert und dann konstruiert, begibt man sich in den Bereich des Softwareengineerings von Realzeitsystemen. Dies ist nicht Gegenstand dieser Vorlesung. Generelle Kenntnisse des Softwareengineerings werden hier vielmehr vorausgesetzt. Im Hinblick auf die Besonderheiten von Realzeitsystemen wird hier allerdings ein Schema zum SWE von Realzeitsystemen erwähnt, das der sehr lesenswerten Dissertation [DASDAN 1999] entnommen wurde.
Neben der allgemeinen Unterscheidung in Verhaltensmodell ('requirements model') und Designmodell ('architectural model') kommt es beim SWE von Realzeitsystemen insbesondere auf die präzise Erfassung der Abhängigkeiten der einzelnen Tasks untereinander an und deren Zeitbedarf. Ein Analysemittel ist hier der Task Graph, in dem die möglichen Übergänge zwischen den einzelnen Tasks sowie alle Anforderungen an diese Übergänge dargestellt werden (siehe Schaubild).
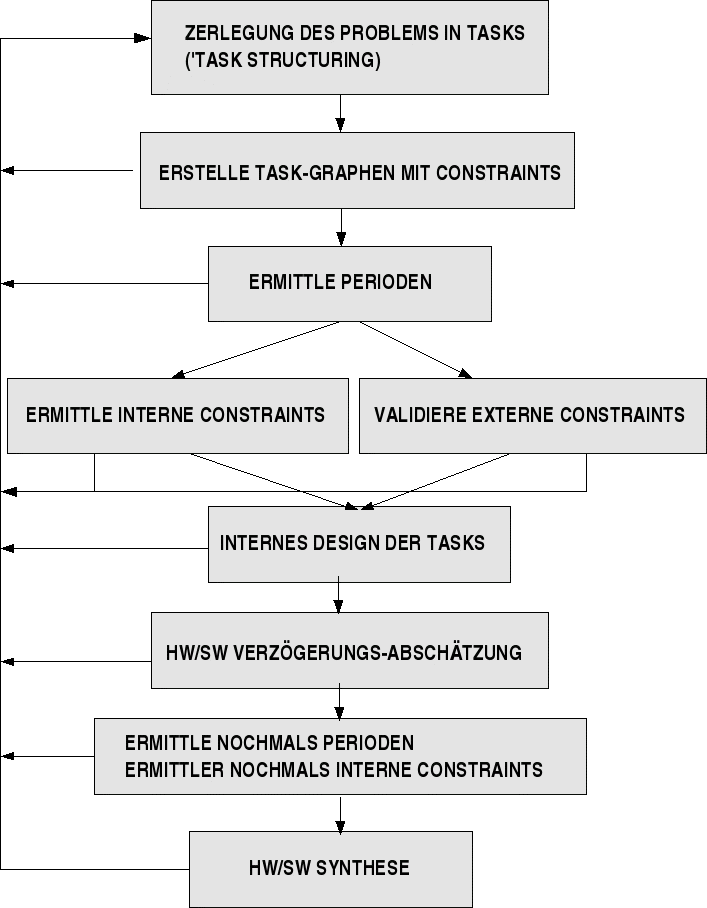
Schema zum SWE von Realzeitsystemen (nach [DASDAN 1999:13])
Ein Task Graph modelliert also alle wesentlichen Anforderungen des gewünschten Verhaltens. Je nach Systemansatz kann solch ein Taskgraph sehr unterschiedliche Daten beinhalten. Wichtig ist nur, dass alle die Daten, die man für die spätere Ermittlung der Zeiten benötigt, auf der Basis dieses Taskgraphen berechnet werden können, entweder exakt oder zumindest in einer Annäherung mit quantifizierter Ungenauigkeit.
Man kann anhand dieses Schemas schon erahnen, wie auf diese Weise methodisch das Problem gelöst werden kann, das in Vorlesung 4 herausgearbeitete Problem der Zuordnung von Ausführungszeiten im Softareentwicklungsprozess selbst in den Griff zu bekommen. In gewisser Weise ersetzt der Taskgraph die Programmierung; idealerweise erlaubt er eine erschöpfende Modellbildung aller gewünschten Tasks und Taskabhängigkeiten unter Einbeziehung der zeitlichen Komponente. Dieses Modell des Taskgraphen wird dann idealerweise konvertiert auf eine Implementierungsebene, auf der dann unter Einbeziehung der konkreten Implementierungsdetails die logischen und temporalen Abhängigkeiten nochmals überprüft und präzisiert werden.
Im Idealfall würde der Taskgraph mittels visueller Programmierung erstellt und dann automatisch auf die anderen Repräsentationsebenen 'herunter konvertiert'.
Das folgende Schaubild zeigt einen einfachen Taskgraphen bei dem neben der sachlichen Abfolge auch die Perioden angegeben sind, z.B. '14' für den Task s.
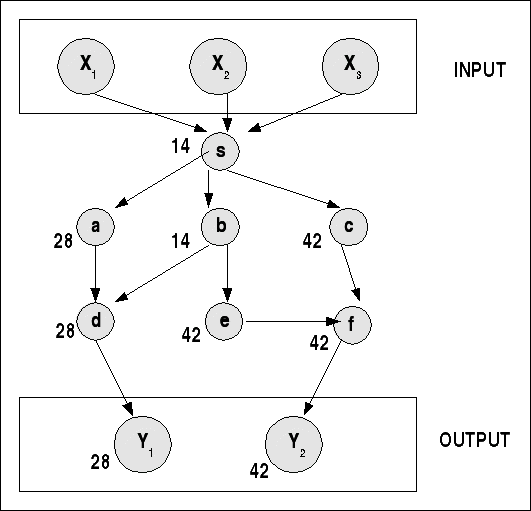
Vereinfachtes Schema eines Task Graphen zitiert nach [DASDAN 1999:83]
Dieser Taskgraph als Verhaltensmodell unterstellt, dass Tasks generell parallel ausgeführt werden können. Erst bei der Implementierung wird entschieden, wieviele CPUs verfügbar sind und inwieweit im Falle von nur einer verfügbaren CPU Präemption möglich ist.
Das nachfolgende Schaubild zeigt eine mögliche Umsetzung des obigen Beispiels in einen Taskgraphen. Die Ereignisse e1 und e2 bilden den Input des Systems. Die Zahlen links vom Pfeil repräsentieren die Periode; die Zahlen rechts davon gesetzte Deadlines. Die Zahl '0' an den Pfeilern repräsentiert die angenommene Reaktionszeit zwischen Auftreten eines Ereignisses und der Reaktion durch den Task. Die Zahlen neben dem Task repräsentieren dessen Periode als Startzeit sowie die mögliche Endzeit unter Berücksichtigung der Deadline. Die Zahlen neben dem Pfeil repräsentieren die Dauer des Tasks bis zur Bereitstellung des Ergebnisses.
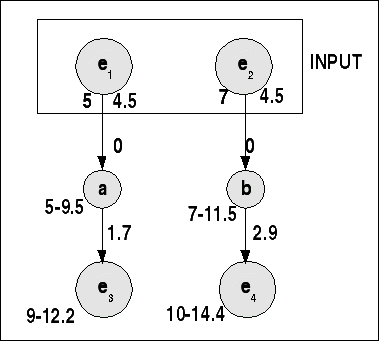
Möglicher Taskgraph zum Beispiel
Schon diese beiden Beispiele machen deutlich, dass die konkrete Ausgestaltung von Tasks sehr divergieren kann. Sie hängt von dem zugrundeliegenden Theoriemodell ab. Als sehr gute Illustration dieser Problematik sei nochmals auf das Buch[DASDAN 1999]verwiesen, hier besonders das Kap.3.
Nach diesen Vorüberüberlegungen sollen nun ein paar konkrete Szenarien betrachtet werden. Danach der Versuch einer systematisierenden Zusammenfassung.
Analog dem oben vorgestellten Schema zum SWE von Realzeitsystemen würde man im Falle des statischen Schedulings auch damit beginnen, einen geeigneten Taskgraphen zu erstellen.
Im nachfolgenden Schaubild wird ein Taskgraph gezeigt mit zwei Nodes und Messages zwischen den Nodes. Vereinfachend wird angenommen, dass die Periodenzahl für jeden Task sich entlang des Pfades um 1 erhöht (das Diagramm folgt [KOPETZ 1997:237]).
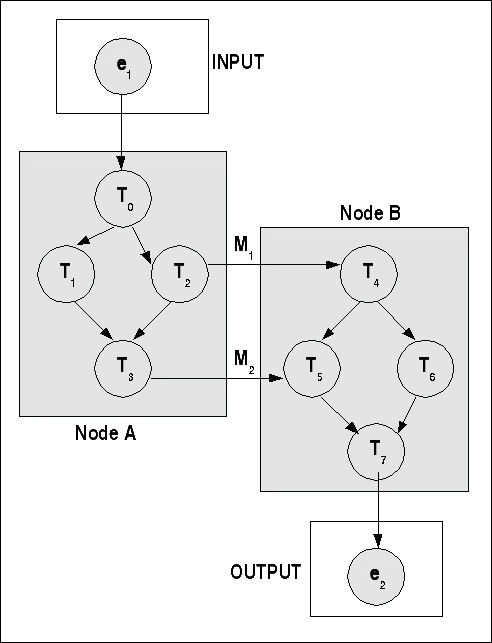
Taskgraph mit zwei Nodes und Messages
Die Aufgabe für die Aufstellung eines Ausführungsplanes ('schedule') besteht nun darin, sämtliche mögliche Pfade zu ermitteln, den Zeitbedarf zu berechnen und diesen abzugleichen mit den bekannten Deadlines.
Eine kleine 'Demo' zum vorausgehenden Taskgraphen ist nachfolgend angeführt. Die möglichen Pfade sind tabellarisch aufgelistet, dazu die angenommenen Verarbeitungszeiten. Im Falle des ereignisses wird statt der Verarbeitungszeit die rot unterlegte Deadline abgeführt. Im Beispiel benötigen alle Pfade mehr Zeit als die extern vorgegebene Deadline zulässt.
| e1 | 5 | |||||
| e1->T0 | ||||||
| T0 | 1 | |||||
| T0->T1,T2 | ||||||
| T1 | 1 | T2 | 1 | |||
| T1->T3 | T2->T3,(M1)T4 | 1 | ||||
| T3 | 1 | T4 | 1 | |||
| T3->(M2)T5 | 1 | T4->T5,T6 | ||||
| T5 | 1 | T5 | 1 | T6 | 1 | |
| T5->T7 | T5->T7 | T6->T7 | ||||
| T7 | 1 | T7 | 1 | T7 | 1 | |
| 6 | 6 | 6 | ||||
Welche Komponenten bilden zusammen das Paradigma Realzeitsysteme?
Welcher Art Input kennzeichnet Realzeitsysteme?
Was haben Tasks mit Ressourcen zu tun?
Wie kann man Ereignisse nach Art ihrer Herkunft charakterisieren?
Was unterscheidet periodische Ereignisse von spontanen oder aperiodischen Ereignissen?
Was versteht man unter gehäuften Ereignissen?
Welche Art von Ressourcen müssen typischerweise bei realzeitsystemen berücksichtigt werden?
Aus welchen Bestandteilen setzt sich die Systemfunktion zusammen?
Was unterscheidet abhängige von unabhängigen Tasks?
Was bedeutet es, dass ein System präemptiv ist?
Was ist der Unterschied zwischen einem Ereignis und einem Task?
Was ist damit gemeint, dass ein Task periodisch ist?
Wie verhalten sich Aktionen zu Tasks?
Angenommen, die Buchstaben 'A' - 'H' repräsentieren Tasks, was bedeutet dann die folgende Schreibweise: A --> ( B || (C --> D) || ( E --> F --> G )) --> H?
Was ist eine technishe Tabelle? Welche Komponenten enthält sie? Erklären sie die Funktion der einzelnen Komponenten.
Was versteht man unter einem Jitter, unter der Jitter-Toleranz und der relativen und der absoluten Jitter-Toleranz?
Wie unterscheidet sich die relative von der absoluten Deadline? Inwiefern kann man mit einer Deadline eine Zeitfenster definieren?
Was unterscheidet die restliche Ausführungszeit eines Tasks von seiner Ausführungszeit?
Was versteht man unter der Periode eines Ereignisses?
Wie berechnet man die Auftretenszeit des k-ten Ereignisses, wenn die Periode des Ereignisses T ist?
Wie berechnet man die absolute Deadline des k-ten Auftretens eines Ereignisses?
Unter welchen Bedingungen sagt man, dass ein Task wohlgeformt ist?
...to be continued....