
|
|
I-RT REALZEITSYSTEME WS0304
|
Schon in der letzten Vorlesung wurde sichtbar, wie durch die Einbeziehung der Dimension der Zeit eine Fülle neuer interessanter Begriffe ins Spiel kommen, die es möglich machen, technische Systeme nicht nur nach ihrem logischen Verhalten zu charakterisieren, sondern auch nach ihrem zeitlichem Verhalten. Darauf aufbauend sind dann so grundlegende Begriffe wie MTTF, MTTR usf. möglich geworden.
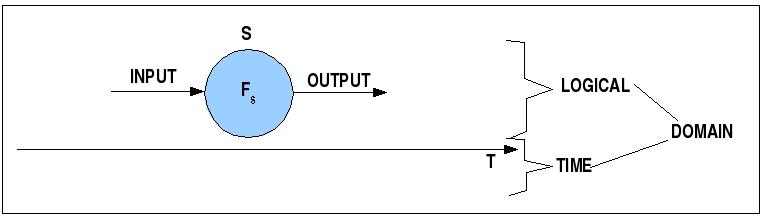
Der logische und der zeitliche Gegenstandsbereich
In der heutigen Vorlesung soll die Eigenart der zeitlichen Dimension und ihr Wechselspiel mit der logischen Dimension weiter vertieft werden. Als zentraler Grundsatz gilt hier, dass die Zeit Priorität über die Logik hat! Damit ist nicht gemeint, dass die Logik gleichgültig oder weniger Wert ist, sondern dass die Einhaltung der zeitlichen Anforderungen absolute Priorität besitzt. Ein Programm mag logisch noch so 'schön' sein, wenn es die Zeitanforderungen nicht einhalten kann, dann kann es nicht verwendet werden. Dies bedeutet, dass jede Programmlogik im Kontext von Realzeitsystemen immer auch unter dem Aspekt ihres zeitlichen Verhaltens zu betrachten ist. Für jede einzelne Funktion muss offen liegen, wieviel Zeit sie benötigt, und im Falle von interagierenden Funktionen muss deren Gesamtbedarf an Zeit zweifelsfrei geklärt sein. mehr noch, dieser analysierte Zeitbedarf muss innerhalb bestimmter Eckwerte garantiert werden! Ohne solche Garantien sind Realzeitsysteme nicht möglich bzw., würde man Systeme ohne solche Garantieren bauen, der Einsatz solcher nicht vollständig garantierter Systeme wäre ein nicht vertretbares Sicherheitsrisiko.
Aus diesen Überlegungen folgt u.a., dass die Anforderungen an das Softwareengineering von Realzeitsystemen erheblich höher sind als für Nicht-Realzeitsysteme. Und wenn man weiss, wie schwer schon die Bereitstellung guter softwaretechnischer Verfahren für Nicht-Realzeitsysteme ist, dann wird man sich nicht wundern, dass es im Bereich Softwareengineering von Realzeitsystemen noch erhebliche Lücken zu verzeichnen gibt. Hier liegt eine grosse Herausforderung an die Informatik.
Einige der zentralen Aspekte bei der Analyse des Realzeitbedarfs von Realzeitsystemen sollen nun weiter herausgearbeitet werden.
(Für die nachfolgende Darstellung zur Realisierung von Zeit durch Timer sei auch verwiesen auf die Darstellung von [Klaus Wüst 2003:194ff], der wir hier weitgehend folgen.)
Was auch immer ein Realzeitsystem tun soll, es wird operationale Zeit in unterschiedlichsten Formen benötigen. Diese wird heute in der Regel mittels Timer-Chips realisiert, die so verschaltet werden, dass man unterschiedlichste Anforderungen damit erfüllen kann. Das nachfolgende Diagramm gibt dazu ein Beispiel:
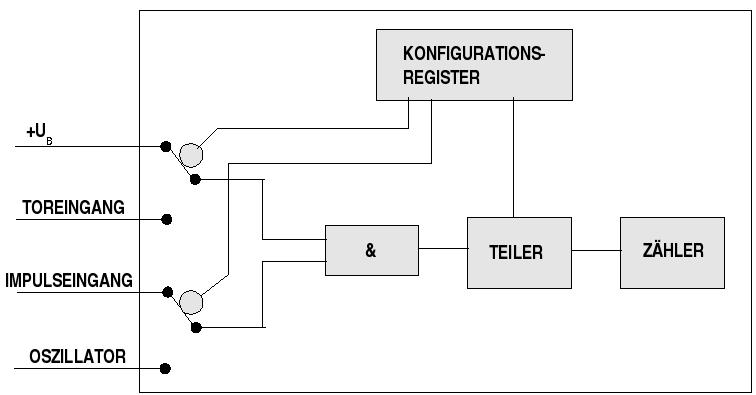
Vielseitige Timerschaltung
Diese Schaltung lässt folgende grundsätzliche Schaltungseinstellungen erkennen:
Bei konstanter Vorspannung durch +UB zählt ein Zähler einzelne Impulse.
Nur bei Vorliegen einer bestimmten Torspannung zählt ein Zähler einzelne Impulse
Bei konstanter Vorspannung durch +UB zählt ein Zähler die Impulse eines Oszillators.
Nur bei Vorliegen einer bestimmten Torspannung zählt ein Zähler die Impulse eines Oszillators.
Zusätzlich kann in allen vier Fällen der Zählvorgang durch einen Teiler modifiziert werden.
Ein Zähler kann aufwärts oder abwärts laufen.
Beim Zählerüberlauf kann ein Zähler aus einem Register mit einem bestimmten Wert geladen werden.
Beim Zählerüberlauf kann ein Zähler einen Interrupt auslösen und/oder einen Pegelwechsel an einem Anschluss.
Die abfrage eines Zählers kann mittels capture erfolgen oder mittels compare. Im Falle von capture wird der Inhalt des Zählerregisters gelesen, ohne dass der Zähler angehalten wird; im Falle von compare wird der Inhalt des Zählerregisters mit einem anderen Wert verglichen. Falls ungleich läuft der Zähler weiter, falls gleich wird ein Interrupt oder ein Pegelwechsel ausgelöst.
Bei einem Zähler mit N-Bit Breite, einem Startwert S und einer Inkrementzeit Ti beträgt die Zeitdauer TO zwischen zwei Überläufen:
TO = (2N - S) * TiBei einem Systemtakt von z.B. 1 MHz würde ein Takt 1/1 MHz = 1*10-6sec = 1 Mikrosekunde dauern.
Mit diesem Arrangement lassen sich unterschiedlichste Aufgaben lösen. Einige seien hier kurz genannt:
Impulszählung:
Bewegungen von mechanischen Teilen lassen sich z.B. durch Dehungssensoren erfassen, die pro Wegstrecke eine bestimmte
Anzahl von Impulsen senden. Durch Zählen der Impulse kann man Rückschlüsse über die ausgeführten Bewegungen bekommen.
Impulsdifferenzen:
In Erweiterung der Impulszählng kann man die Diferenz zu unterschiedlichen Zeitpunkten bilden und somit Teilstrecken
ermitteln.
Impulsabstandsmessung:
Sensoren kodieren häufig ihre Messwerte duch digitale Abstände. Um diese zu erfassen muss man den Capture-Wert eines
Zählers sowohl bei der ersten aufsteigenden (oder fallenden) Flanke erfassen als auch bei der nächsten; die Differenz gibt
den 'Abstand' zwischen zwei Impulsen an bzw. die Zeitdauer.
Impulsfrequenzmessung:
Hat man den Impulsabstand, dann hat man die Dauer zwischen zwei Impulsen. Daraus kann man dann als Kehrwert die Frequenz
ermitteln.
Impulslängenmessung:
Misst man anstatt den aufsteigenden (bzw. fallenden) Flanken von zwei aufeinanderfolgenden Impulsen die aufsteigende und
die absteigende Flanke eines Impulses, dann hat man seine Länge.
Pulsweitenmodulation:
Mit Hilfe der Capture-Methode kann man auch Impulse bestimmter Länge erzeugen. Man startet einen Impuls, wenn der erste
Capture Wert erreicht ist, und man schaltet ihn wieder ab, wenn der zweite Capture-Wert erreicht wird.
Die Steuerung von Pulsweiten ist z.B. hilfreich, um den Verbrauch von Ressourcen bei bestimmten Aggregaten zu reduzieren,
indem man ihnen nur noch partiell Leistungen zuführt, nicht mehr 100%.
Zyklischer Interrupt:
Umgekehrt kann man Pulsweiten ach zur Erzeugung zyklischer Interrupts benutzen. Immer dann, wenn der Zähler nach einem
bestimmten Reload-Wert einen Überlauf erzeugt (festes Zeitintervall), dann wird z.B. ein Interrupt gesetzt.
Durch Kombination von mehreren Timereinheiten lassen sich noch weitere komplexere Schaltungen realisieren. Moderne Mikrokontroller besitzen 5 und mehr solche Einheiten, die frei konfigurierbar sind.
Diese Ausführungen zeigen, dass das Zeitverhalten eines Realzeitsystems maximal begrenzt ist durch seine Timer-Architektur. Wenn die kleinste realisierbare Einheit 1 Mikrosekunde ist, dann können Ereignisse mit kleineren Zeiteinheiten nicht behandelt werden. Wie die weiteren Überlegungen zeigen werden, ist aber das tatsächliche Zeitverhalten eines Systems durch zahlreiche weitere Randbewingungen zusätzlich eingeschränkt.
Wie schon in der letzten Vorlesung bemerkt, unterscheidet man Systeme u.a. nach dem Aspekt 'zeitgetrieben' oder 'ereignisgetrieben'. Zeitgetriebene Systeme ('time triggered') sind vollständig von einem Systemtakt gesteuert; die Reaktion auf externe Ereignisse erfolgt ausschliesslich nach einem festen Plan. Für die meisten Situationen, in denen ein Realzeitsystem zum Einsatz kommen muss, ist dies aber ungenügend; typischerweise muss ein Realzeitsystem auf Ereignisse reagieren, deren Auftreten meist nicht vorausgesehen werden kann. Ausserdem kann die Zahl solcher unterschiedlicehr Ereignisse sehr gross sein. Ein festes Abfrageschema, wie es zeitgetriebene Systeme nur ermöglichen, kommt da schnell an seine Grenzen (z.B. ein System soll 50 verschiedene Ereignisse überwachen; eine Einzelüberprüfung sei mit 8 Systemtakten angenommen. 50 Überprüfungen wären dann 400 Systemtakte. Im worst-case Fall tritt das Ereignis Nr. 49 gerade dann ein, wenn das System Ereignis 50 überprüft. D.h. das System würde erst in 8 * 48 Takteinheiten feststellen, dass ein Ereignis vorliegt. Ferner wäre im worst-case Fall denkbar, dass alle Ereignisse 1-47 in der Zwischenzeit auftreten und eine Reaktion erzwingen. Bei einer durchschnittlichen Realtionsdauer von z.B. 10 *2 Takteinheiten pro Routine ergäbe dies eine Gesamtreaktionszeit von 8 * 48 + 47 * (10 * 2) = 1324 Takteinheiten. Angenommen, das System sollte im Falle von Ereignis 49 in spätestens 20 Mikrosekunden reagieren, dann wäre dies völlig inakzeptabel.
In dieser Situation macht es Sinn, ereignisgetriebene Systeme ('event triggered') einzusetzen. Solche Systeme reagieren nur dann, wenn ein Ereignis Ei auftritt. Eine solche ereignisgetriebene Reaktion muss in der Hardware des Systems (z.B. in einer CPU oder direkt in einem Mikrokontroller) fest eingebaut sein. Folgende Eigenschaften sind hier wichtig:
ID, Priorität:Jeder Interrupt besitzt eine eindeutige ID, eine eindeutige Priorität und innerhalb der Priorität evtl. noch einen Rang
Feste Abfolge:Die Zeit zwischen Interruptanforderung und Reaktion muss einer festen Abfolge folgen und darf eine definierte Zeitspanne nicht überschreiten. Dies beinhaltet, dass möglcherweise laufende Interruptbehandlungen unterbrochen werden müssen um einen Interrupt mit höherer Priorität vorzuziehen.
Multiple Interrupts: die Behandlung von mehreren Interrupts zur gleichen Zeit muss möglich sein, d.h. Interrupts müssen maskiert werden können.
Aktivierung einzeln: man kann die Abfragemaske für jeden Interrupt einzeln setzen bzw. nicht setzen.
Deaktivierung von allen: man muss alle Interrupts ausschalten können.
Jedem Interrupt seinen Interrupthandler: man muss für jeden Interrupt einen eigenen Handler bereithalten können.
Umkonfiguration im laufenden Betrieb: um z.B. 'Wechsel im Betriebsmodus' ('mode change') realisieren zu können, muss man die Zuordnung von Masken und Routinen im laufenden Betrieb ändern können; dazu gehört z.B., dass man die Interrupthandler für ein und denselben Interrupt je nach Modus an unterschiedlichen Stellen ablegen kann.
Dabei ist zu beachten, dass zusätzlich zu den Interrupts auch noch Ausnahmen auftreten können; Ausnahmen sind keine Interrupts, sondern dies sind definierte Fehlverhaltensereignisse die mit allerhöchster Priorität zu behandeln sind noch vor den Interrupts (z.B. Division durch 0).
Angenommen die zuvor beschriebene Situation beträfe ein ereignisgetriebenes System (ET := Event triggered System), dann könnte man z.B. dem Ereignis Nr. 49 einen hohen Prioritätswert zuweisen, z.B. 1. In diesem Fall würde das System bei Auftreten von Nr.49 die aktuelle Behandlung unterbrechen --bei blossem Umschalten der Speicherbereiche evtl. nur 2 Takteinheiten-- und sofort mit der Bearbeitung von Nr. 49 beginnen, also nach 2 Mikrosekunden anstatt nach 1324.
Schwieriger ist die Frage zu behandeln, wenn es mehr als 1 Interruptreignis der Priorität 1 ergibt. Ofensichtlich müssen die EntwicklerInnen des Systems vor dem Einsatz sehr genau klären, wieviele Interrupts vorkommen können, wie schnell diese jeweils zu bearbeiten sind und wie das gesamte System der Interrupts zu organisieren ist, damit keine 'tödliche Zonen' durch Konflikte zwischen gleichwertigen Interrupts entstehen.
Diese Überlegungen sollen nun noch weiter vertieft werden.-
Für die weiteren Überlegungen ist es notwendig eine mögliche Komplexitätshierarchie innerhalb von Realzeitsystemen anzunehmen. Wir folgen hier wieder dem Buch von [Kopetz 1997:Chapt.4].
Kopetz nimmt an, dass ein Realzeitsystem aus einem Cluster von Fault Toleran Units (FTUs) bestehen kann. Eine FTU wiederum kann aus mehreren Nodes bestehen, die als Smallest Replacable Units (SRUs) gelten, also als kleinste ersetzbare Einheiten. Wenn ein Node in einer FTU ausfällt, dann könnte dieser sofort von einer anderen Node ersetzt werden. Ein Node wiederum besteht aus Tasks, die als kleinste funktionale Einheiten einer Node angesehen werden.
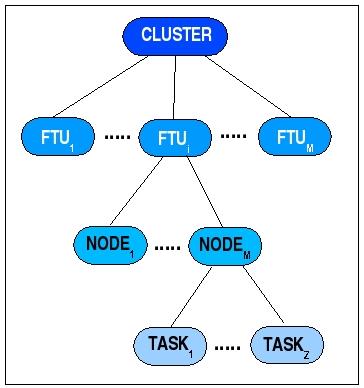
Komplexitätsebenen in Realzeitsystemen
Auch wenn ein Task als kleinste funktionelle Einheit in einer Node gilt, so mus man hier doch noch eine wichtige Unterscheidung machen, nämlich die zwischen 'einfachen' und 'komplexen' Tasks.
Ein einfacher ('simple') Task ('S-Task') ist ein Prozess, der --wird er einmal gestartet-- auf keinen anderen Task mehr warten muss; ein einfacher Task hat alle Ressourcen, die er zur Erfüllung seiner Aufgabe benötigt. So gesehen ist er 'autonom'.
Demgegenüber zeichnet sich ein komplexer ('complex') Task ('C-Task') dadurch aus, dass er mindestens an einer Stelle die Ergebnisse eines anderen Tasks benötigt, d.h. er muss warten ('wait'-statement), bis der andere Task ihm diese Ergebnisse liefert.
|
|
SIMPLE |
COMPLEX |
|
NO SYNCHRONISATION |
+++ |
--- |
|
SYNCHRONISATION |
--- |
+++ |
Nennt man die Zeit, die ein Task a benötigt, um seine Aktion auszuführen,
dact,a(x,z,s)(mit x := Input Daten von a, z := Kontrollsignal für a, s := interne Zustände von a), dann ist diese Zeit im Falle eines einfachen S-Tasks wohldefiniert, im Falle eines komplexen C-Tasks muss dies nicht der Fall sein. Wie später deutlich wird, kann das Auftreten von C-Tasks zu NP-harten Problemen führen.
Von der Eigenschaft der Synchronisation zu unterscheiden ist die Eigenschaft der Präemption. Präemption liegt vor, wenn ein Task --auch ein S-Task!-- aufgrund eines Interrupts unterbrochen werden muss.
Zuvor wurde herausgestellt, wie vorteilhaft ereignisgetriebene Systeme gegenüber zeitgetriebenen Systeme sein können, wenn es darum geht, schnell und flexibel auf unerwartete Ereignisse zu reagieren. Allerdings darf nicht übersehen werden, dass die Unterbrechung eines laufenden Task a gefolgt von dem Umschalten ('switching') auf einen neuen Task b auch minimale Zeit benötigt, und zwar administrative Zeit, die zusätzlich ('overhead') zur normalen Task-Ausführungszeit entsteht. Im Englischen spricht man daher hier auch vom 'administrative overhead' (AO). Selbst wenn man heute schon in der Hardware diese Verwaltungsprozesse dadurch beschleunigt, dass man keine speziellen Register mehr benutzt, sondern nur noch Speicherbereiche, zwischen denen man hin- und herschaltet, benötigt man auch in diesem Fall minimale Verwaltungsprozesse, die das Wiederauffinden der verschiedenen Speicherbereiche sicherstellen.
Seien
dact,a(x,z,s) und dact,b(x',z',s')die Ausführungszeiten, die die Tasks a und b 'für sich genommen' benötigen. Sei
dw(a,b)die Umschaltzeit (switch-time) von a nach b und
dw(b,a)die Umschaltzeit (switch-time) von b nach a. Dann ist einerseits klar, dass jede präemptive Unterbrechung zwei zusätzliche Verwaltungszeiten einführt. Selbst bei effektiver Hardwareorganisation muss man mindestens 2 Operationen annehmen, um diese zu realisieren (Zeiger setzen, Umschalten). Im Falle vieler 'blinder' Interrupts könnte dies den administrativen Overhead extrem erhöhen. Man kann ausrechnen, in welcher Konstellation der worst-case administrative overhead (WCAO) das Gesamtverhalten des Systems soweit stören würde, dass es die Realzeitanforderungen sprengen würde. Das Problem ist nur, dass die Ursachen für solche Umschaltvorgänge letztlich in Ereignissen gründen, deren Auftreten nicht vom System kontrolliert werden (man denke an die grossflächigen Zusammenbrüche der Energieversorgung in USA, Schweden und Italien in 2003).
Eingangs der heutigen Vorlesung wurde festgestellt, dass bei Realzeitsystemen die Zeit Priorität geniesst, und zwar in dem Sinne, dass jede logische Funktionseinheit bzgl. ihres möglichen Zeitbedarfs im Rahmen fest vorgegebener Eckwerte eindeutig und verlässlich bestimmt werden muss.
Die nachfolgenden Überlegungen haben dann gezeigt, dass eine Bestimmung des Zeitbedarfs nicht auf einer Ebene alleine, sondern nur unter Berückichtigung aller Ebenen vorgenommen werden kann.
Das nachfolgende Diagramm bringt dies nochmals zusammenfassend zum Ausdruck:
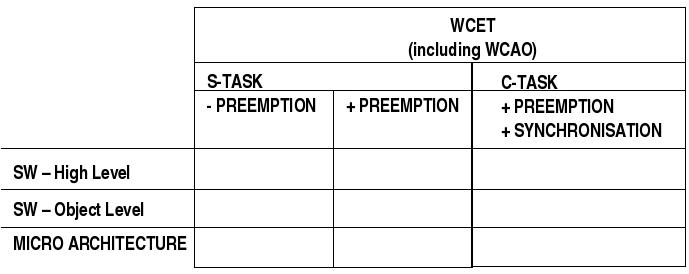
Dimensionen der Berechnung von WCET
Ausgangspunkt ist die Grösse WCET := worst case execution time. Wenn es eine Grösse gibt, die präzise und verlässlich bestimmt werden muss, dann diese. Die Einlösung dieser Forderung enthüllt aber die immense Schwierigkeit, die dem entgegensteht.
Ausgangspunkt bildet die Software auf der höchsten Ebene der Kodierung; möglicherweise sogar die Ebene der formalen Modellbildung. Nennen wir dies den A-Level für abstrakten Level. Dies ist die Ebene, auf der die logische Funktion der Software definiert ist. Dies ist ebenfalls die Ebene, auf der der Auftraggeber mit dem/der IngenieurIn kommuniziert. Die Aufgabe besteht hier darin, diese formale Darstellung der Software in eine solche formale Präsentation zu übersetzen, die es zweifelsfrei erlaubt, jedem Abschnitt des Softwarequelltextes eindeutig einen Zeitbedarf zuzuweisen. Eine von mehreren Möglichkeiten, dies zu tun, ist die Konvertierung des Quelltextes in Struktogramme. Da sich alle Algorithmen grundsätzlich vollständig in Struktogramme konvertieren lassen, ist garantiert, dass bei dieser Konvertierung nichts verlorengeht.
Im nächsten Schritt muss nun eine Zuordnung hergestellt werden zwischen Abschnitten des Quelltextes auf dem A-Level und dem Objekkode, der vom Compiler erzeugt wird. Nennen wir diese Ebene den O-Level. Ohne diese Zuordnung ist nicht klar, welcher Ressourcenbedarf dem Quelltext auf der hohen Ebene entspricht, also
MAP1: A-LEVEL ---> O-LEVELIst diese Abbildung gelungen, dann muss man nun eine Zuordnung herstellen wzischen den Elementen des Objektkodes und den Operationen der Mikroarchitektur; nennen wir diese den M-LEVEL, also:
MAP2: O-LEVEL ---> M-LEVELIst auch diese Zuordnung gelungen, dann lässt sich der Zeitbedarf eines Programms klar aussagen. Wichtig dabei ist, dass nicht alle Verarbeitungs-Pfade betrachtet werden müssen, sondern nur die kritischen Pfade ('critical paths'); dies sind jene, die die WCET gefährden könnten.
An dieser Stelle angekommen muss man feststellen, dass die Quantifizierung des M-LEVELS wahrscheinlich das grösste Problem darstellt; denn die modernen Prozessoren und Mikrokontroller sind fast ausnahmslos RISC-Prozessoren, die ausgefeilte Caching- und Pipelining-Verfahren beinhalten. Ein solches Verhalten ist indeterministisch! Es bleibt eine offene Frage, wieweit man in extrem zuverlässigen Kontexten solche CPUs überhaupt einsetzen kann; der Trend geht momentan allerdings dahin, fast ausschliesslich solche hochleistungsfähigen, aber inhärent indeterministisch, Prozessoren zu bauen.
Kann man schon alleine durch diese Analyse der Anforderungen der unterschiedlichen Realisierungsebenen erahnen, welche Herausforderungen Realzeitsysteme für den/die IngenieurIn bereithalten, so wird dies noch zusätzlich erschwert durch die Tatsache, dass die Annahme von S-Tasks ohne Präemption praktisch kaum vorkommt; selbst bei der vereinfachenden Annahme, dass nur S-Tasks auftreten, muss man doch meistens Präemption annehmen. Damit kommt aber nicht nur die Grösse WCAO ins Spiel, sondern auch der Faktor externer Ursachen, die vom System selbst nicht kontrolliert werden kömnen. Nimmt man weiterhin an --was 'normal' ist--, dass C-Tasks vorkommen, dann tritt zusätzlich das Synchronisationsproblem auf, das in der Berechnung berücksichtigt werden muss.
Angesichts dieser Komlexität überrascht es nicht, wenn [KOPETZ 1997:90] zur Frage der WCET-Bestimmung abschliessend schreibt:
"The state of current practice is not satisfactory, because it is difficult to ascertain that the assumed WCET is a guaranteed upper bound of the actual WCET. Further work is needed in all areas of timing analysis to come to tigh analytical bounds of the WCET."Wie schon diese Überlegungen zeigen, geht mit den Phänomenen Interrupt, Präemption und Synhronisation das Scheduling-Problem einher. Dies soll in der nächsten Vorlesung etwas nähr betrachtet werden.
Worin unterscheidet sich bei Realzeitsystemen die logische Dimension von der zeitlichen?
Welchen Einfluss hat bei Realzeitsystemen die zeitliche auf die logische Dimension?
Welche funktionalen Einheiten können Sie auf Chipebene bei der Erzeugung und der Zählung von Zeiteinheiten unterscheiden?
Nennen sie 7 zeitlichen Eigenschaften von Signalen, die sich mittels Timer messen lassen?
Was ist der Unterschied zwischen einem zeit- und ereignisgetriebenen System?
Was ist ein Interrupt auf Hardwareebene?
Welche Informationen werden benötigt, damit ein Interruptkontroller Interrupts verwalten kann?
Welche Eigenschaften eines Interruptkontrollers sind aus Sicht eines/r Entwicklers/In wünschenswert?
In welchen Situationen ist ein zeitgetriebenes System günstiger als ein ereignisgetriebenes?
In welchen Situationen ist ein ereignisgetriebenes System günstiger als ein zeitgetriebenes?
Wie verhalten sich die Begriffe 'cluster', 'ftu', 'node' und 'task' zueinander?
Was unterscheidet einen S-Task von einem C-Task?
Was bedeutet es, wenn ein System 'präemptiv' ist?
Worin liegt der Unterschied, wenn ein C-Task auf einen anderen Task 'warten' muss und wenn ein C-Task präemptiv unterbrochen wird?
Wenn Taskunterbrechung eintritt, welche Auswirkungen hat dies auf die Ressource Zeit?
Was verstehen Sie unter WCAO?
Was verstehen Sie unter WCET?
Warum spielen Abbildungsprozesse im Rahmen der Berechnung von WCET eine wichtige Rolle? Worin bestehen diese Abbildungsprozesse?
Nennen Sie Faktoren, die die Ermittlung von WCET erschweren bzw. beim heutigen Wissensstand letztlich unmöglich machen?