Next: Random Number Tests Up: Test Environment 'Wood1' Previous: Test Environment 'Wood1' Contents
To be able to evaluate the different structures of the agents how they contribute to the observable behavior and to which degree a certain structure is better than another one it is helpful to have a complete random structure as a zero structure with which every other structure can be compared. Thus it should be able to construct some order like
![]() . Moreover it would be very handsome to have some measure of accessibility for a certain test environment to evaluate how good a system is doing in such an environment. If we could state the general probability to reach a certain position in the environment without any additional information then one could use such a measure as some benchmark for the used agent systems.
. Moreover it would be very handsome to have some measure of accessibility for a certain test environment to evaluate how good a system is doing in such an environment. If we could state the general probability to reach a certain position in the environment without any additional information then one could use such a measure as some benchmark for the used agent systems.
Let us assume as the most simple environments those with only one food cell in the center and the the whole environment as a
![]() -square with
-square with
![]() with
with ![]() as the distance of the border cells to the center. See below three examples for
as the distance of the border cells to the center. See below three examples for
![]() .
.
GRID01:
![]()
!. . . ! ! ! !. F . ! ! ! !. . . !
GRID02:
![]()
!. . . . . ! ! ! !. . . . . ! ! ! !. . F . . ! ! ! !. . . . . ! ! ! !. . . . . !
GRID03:
![]()
!. . . . . . . ! ! ! !. . . . . . . ! ! ! !. . . . . . . ! ! ! !. . . F . . . ! ! ! !. . . . . . . ! ! ! !. . . . . . . ! ! ! !. . . . . . . !
From a very general point of view one could roughly say to find one of the cells in such a ![]() -grid is
-grid is
![]() and one use this as a rough measure of accessibility. Thus one could guess that to find a certain food cell during 25 move actions is approximnately
and one use this as a rough measure of accessibility. Thus one could guess that to find a certain food cell during 25 move actions is approximnately
![]() . With
. With ![]() this would give us a guess of
this would give us a guess of
![]() meaning that during 25 move actions one will approximately hit a certain move cell 2.7 times often.
meaning that during 25 move actions one will approximately hit a certain move cell 2.7 times often.
To refine the probability estimate one can use some more advanced probibility models. One rather simple but powerful model would be to assume the environment as a field where every cell has it's own probability depending from the possible path of an agent beginning with a certain start position.
Let us assume for a while that the agent -marked as '*' in the grid below- will always start in the left-upper corner of the field represented by the coordinates ![]() . This would look like as follows:
. This would look like as follows:
!* . . ! ! ! !. F . ! ! ! !. . . !
Assuming sequences of move actions we can distinguish different states of the environments: the state before a move happens and the state after that move. A move causes a change. We can encode the probability of an agent being in the beginning at a certain position as a matrix:
-->init=[1 0 0; 0 0 0; 0 0 0]
init =
1. 0. 0.
0. 0. 0.
0. 0. 0.
This matrix has to interpreted as 'in the beginning is the probability that the agent is at position (1,1) '1', all other cells have probability '0'. Because we assume in the wood1-scenarios only eight different movements plus one non-move we have to keep in mind 9 different move actions. From the cell (1,1) only three cells can directly be reached. Every such move has the probability
![]() . To stay has the probability
. To stay has the probability
![]() . Thus it is more likely that the agent would keep this position than to move away.
. Thus it is more likely that the agent would keep this position than to move away.
Extending this idea one can contruct a matrix of all transition probabilities from every cell to every other cell. One can write a little algorithm to do this work (see the scilab-program of the attachement for all the functions used in this lecture notes)4.1.
-2->[W01]=transprob(GRID01)
W01 =
0.6666667 0.1111111 0. 0.1111111 0.1111111 0. 0. 0. 0.
0.1111111 0.4444444 0.1111111 0.1111111 0.1111111 0.1111111 0. 0. 0.
0. 0.1111111 0.6666667 0. 0.1111111 0.1111111 0. 0. 0.
0.1111111 0.1111111 0. 0.4444444 0.1111111 0. 0.1111111 0.1111111 0.
0.1111111 0.1111111 0.1111111 0.1111111 0.1111111 0.1111111 0.1111111 0.1111111 0.1111111
0. 0.1111111 0.1111111 0. 0.1111111 0.4444444 0. 0.1111111 0.1111111
0. 0. 0. 0.1111111 0.1111111 0. 0.6666667 0.1111111 0.
0. 0. 0. 0.1111111 0.1111111 0.1111111 0.1111111 0.4444444 0.1111111
0. 0. 0. 0. 0.1111111 0.1111111 0. 0.1111111 0.6666667
This transition probability matrix has to be read as follows: In the first row are all the transition probabilities of the cell (1,1) to each other cell of the grid, starting with row 1, than row 2, then row3. For example the '0.6666667' says that the transition probability from (1,1) to (1,1) itself is
![]() , from (1,1) to it's neighbour cell (1,2) it is '0.1111111' (=
, from (1,1) to it's neighbour cell (1,2) it is '0.1111111' (=
![]() ), from (1,1) to (1,3) is '0', etc.
), from (1,1) to (1,3) is '0', etc.
With such a transition probability matrix we can predict that the initial state
-->init=[1 0 0; 0 0 0; 0 0 0]
init =
1. 0. 0.
0. 0. 0.
0. 0. 0.
will be changed from one possible action to the next.
-2->W011=W01'
-->INPUT=init
-->SHOW=1,RUNS=1,[OUTPUT]=fieldprob(W011,INPUT,RUNS, SHOW)
OUTPUT =
0.6666667 0.1111111 0.
0.1111111 0.1111111 0.
0. 0. 0.
The line 'W011=W01' tells that the transition matrix has been 'transposed' in the then transposed matrix W011 turning rows to columns.
Then one can observe that the probability of being at (1,1) first rated with '1' has now been diminished to '0.6666667' and the neighbouring cells have received some probability to have the agent as their 'guest' rated as '0.1111111'. All the otherr cells are still 'untouched' labeled as '0'.
Continuing the application of the transition matrix to the field will change the probabilities of all fields by small amounts until the probability of the agent of being at one cell will more or less being evenly spreaded across the whole field! This can be observed following 25 applications of the transition probability matrix below:
-->SHOW=1,RUNS=25,[OUTPUT, STD]=fieldprob(W011,INPUT,RUNS, SHOW)
RUN= 1 : 0.666667 0.111111 0.000000 0.111111 0.111111 0.000000 0.000000 0.000000 0.000000
RUN= 2 : 0.481481 0.148148 0.024691 0.148148 0.111111 0.024691 0.024691 0.024691 0.012346
RUN= 3 : 0.366255 0.153635 0.048011 0.153635 0.111111 0.046639 0.048011 0.046639 0.026063
RUN= 4 : 0.290657 0.148910 0.066606 0.148910 0.111111 0.063557 0.066606 0.063557 0.040085
RUN= 5 : 0.239208 0.141831 0.080357 0.141831 0.111111 0.076055 0.080357 0.076055 0.053193
RUN= 6 : 0.203336 0.135099 0.090127 0.135099 0.111111 0.085197 0.090127 0.085197 0.064709
RUN= 7 : 0.177925 0.129474 0.096907 0.129474 0.111111 0.091892 0.096907 0.091892 0.074418
RUN= 8 : 0.159734 0.125023 0.101547 0.125023 0.111111 0.096819 0.101547 0.096819 0.082378
RUN= 9 : 0.146618 0.121592 0.104693 0.121592 0.111111 0.100461 0.104693 0.100461 0.088780
RUN= 10 : 0.137111 0.118982 0.106813 0.118982 0.111111 0.103165 0.106813 0.103165 0.093857
RUN= 11 : 0.130194 0.117012 0.108238 0.117012 0.111111 0.105176 0.108238 0.105176 0.097842
RUN= 12 : 0.125144 0.115531 0.109192 0.115531 0.111111 0.106676 0.109192 0.106676 0.100946
RUN= 13 : 0.121449 0.114420 0.109830 0.114420 0.111111 0.107796 0.109830 0.107796 0.103349
RUN= 14 : 0.118738 0.113587 0.110256 0.113587 0.111111 0.108632 0.110256 0.108632 0.105200
RUN= 15 : 0.116746 0.112964 0.110541 0.112964 0.111111 0.109257 0.110541 0.109257 0.106619
RUN= 16 : 0.115279 0.112497 0.110731 0.112497 0.111111 0.109725 0.110731 0.109725 0.107705
RUN= 17 : 0.114198 0.112148 0.110858 0.112148 0.111111 0.110074 0.110858 0.110074 0.108532
RUN= 18 : 0.113399 0.111887 0.110942 0.111887 0.111111 0.110335 0.110942 0.110335 0.109161
RUN= 19 : 0.112809 0.111691 0.110998 0.111691 0.111111 0.110531 0.110998 0.110531 0.109639
RUN= 20 : 0.112372 0.111545 0.111036 0.111545 0.111111 0.110677 0.111036 0.110677 0.110001
RUN= 21 : 0.112048 0.111436 0.111061 0.111436 0.111111 0.110786 0.111061 0.110786 0.110274
RUN= 22 : 0.111808 0.111354 0.111078 0.111354 0.111111 0.110868 0.111078 0.110868 0.110481
RUN= 23 : 0.111630 0.111293 0.111089 0.111293 0.111111 0.110929 0.111089 0.110929 0.110637
RUN= 24 : 0.111497 0.111247 0.111096 0.111247 0.111111 0.110975 0.111096 0.110975 0.110755
RUN= 25 : 0.111399 0.111213 0.111101 0.111213 0.111111 0.111009 0.111101 0.111009 0.110843
STD =
0.0001565
OUTPUT =
0.1113987 0.1112127 0.1111012 0.1112127 0.1111111 0.1110095 0.1111012 0.1110095 0.1108434
After 25 applications is the standard deviation STD (also labled as 's') nearly zero.
| (4.10) | |||
| (4.11) | |||
| (4.12) | |||
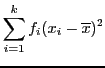 |
(4.13) | ||
| (4.14) | |||
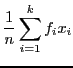 |
(4.15) |
Taking these values as working hypothesis of our theoretical model of accessibility we could then predict that an agent starting in the left-upper corner at (1,1) searching for food which is placed at the position (3,2) will during 25 move operations hit the food cell about
![]() often.
often.
We can test this prediction by using the random agent model.
-->ANIMAT(1)=1, ANIMAT(2)=1,CLASSIFIERS=[],MODE=0,YYMAX=0,XXMAX=0,S=-1,DISTANCE=1,RUNS=25,HISTORY=[],SHOW=0, N=25,[FOODHITS,MEAN, STD]=experiment(ANIMAT,CLASSIFIERS,MODE,YYMAX, XXMAX, S,G1,DISTANCE, RUNS,HISTORY,SHOW,N)
STD =
1.5545632
MEAN =
3.2
FOODHITS =
3.
6.
6.
3.
1.
3.
6.
4.
1.
3.
2.
2.
3.
3.
3.
5.
4.
2.
1.
2.
4.
3.
1.
4.
5.
...
STD =
1.8929694
MEAN =
2.6
STD =
1.8912077
MEAN =
3.08
STD =
1.5275252
MEAN =
3.
STD =
1.5885003
MEAN =
2.24
As one can see there is some variance in the scope of the MEAN values. Thus the empirical values observed so far oscillate around a mean hit value of about '2.84' which is 'close' to the theoretically predicted value of '2.775'. The question is, 'how close'? To evaluate this question we can try to establish some sequence ![]() of theoretically predicted values and a sequence of
of theoretically predicted values and a sequence of ![]() empirically observed values.
empirically observed values.
For the full examples of these computations see again the technical appendix. Here we will only summarize the results.
-->tt=[2.775 2.2 1.836], to=[2.84 2.26 1.74]
-->fto=[1 0 0; 0 1 0; 0 0 1]
fto =
1. 0. 0.
0. 1. 0.
0. 0. 1.
-->rho=correl(tt,to,fto)
rho = 0.9952475
Collecting the data of some experiments we can establish the theoretical values kept in the variable ![]() and the empirical values kept in the variable
and the empirical values kept in the variable ![]() . The cooccurence matrix
. The cooccurence matrix ![]() signifies how often the one value occurs with the others. Because we compare the theoretical and empirical values from a series of different tasks we can say that the first value of
signifies how often the one value occurs with the others. Because we compare the theoretical and empirical values from a series of different tasks we can say that the first value of ![]() cooccurs only with the first value of
cooccurs only with the first value of ![]() etc. Then we apply the correlation operator
etc. Then we apply the correlation operator ![]() to these two different sequences and we get the value '0.9952475' telling us that the correlation is very high. Thus we can indeed say that the empirical values are very 'close' to the predictions.
to these two different sequences and we get the value '0.9952475' telling us that the correlation is very high. Thus we can indeed say that the empirical values are very 'close' to the predictions.
Gerd Doeben-Henisch 2012-03-31