Next: Example Movement Recognition Up: Simple Evolving Connectionis Systems Previous: Example Phonem Recognition Contents
A similar case could be the recognition of letters realized by an
![]() matrix. Every letter would be represented as a 4-Bit vector who serves as input vector. Therefore a SECoS network could have one output representing 'YES' for the recognition of a certain letter or 'NO'. With a combination of several such networks one could recognize more letters. Another variant could be to give one single SECoS network more than one output for different letters and let the network learn more than one letter. A possible experiment could be the following one:
matrix. Every letter would be represented as a 4-Bit vector who serves as input vector. Therefore a SECoS network could have one output representing 'YES' for the recognition of a certain letter or 'NO'. With a combination of several such networks one could recognize more letters. Another variant could be to give one single SECoS network more than one output for different letters and let the network learn more than one letter. A possible experiment could be the following one:
Before one constructs a SECoS with its different constants for Sensivity Threshold ![]() , Output Error
, Output Error ![]() , learning rates
, learning rates
![]() one should investigate the properties of the input space. One point of interest is the question how good the different distance measures distinguish between these elements. The two mentioned distance measures in the papers of Watts and Kasabov are the normalized euclidean distance as well as the normalized manhattan (or One-) distance:
one should investigate the properties of the input space. One point of interest is the question how good the different distance measures distinguish between these elements. The two mentioned distance measures in the papers of Watts and Kasabov are the normalized euclidean distance as well as the normalized manhattan (or One-) distance:
| (8.16) | |||
| (8.17) | |||
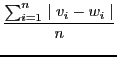 |
(8.18) | ||
^{2})}{\sqrt[2](n)}$](img1061.png) |
(8.19) |
If one applies the normalized euclidean distance to the elements of this set then one can see (cf. column 6), that the euclidean measure does not distinguish between all elements, nor does the normalized manhattan distance (cf. column 7):
base = 0. 0. 0. 0.
for i=1:16, v=[LM(i,1) LM(i,2) LM(i,3) LM(i,4)], LM(i,5)=i, LM(i,6)=normEuclidean(v,base),end,LM
for i=1:16, v=[LM(i,1) LM(i,2) LM(i,3) LM(i,4)], LM(i,5)=i, LM(i,7)=normManhattan(v,base),end,LM
LM =
0. 0. 0. 0. 1. 0. 0.
1. 0. 0. 0. 2. 0.5 0.25
1. 1. 0. 0. 3. 0.7071068 0.5
1. 0. 1. 0. 4. 0.7071068 0.5
1. 0. 0. 1. 5. 0.7071068 0.5
0. 1. 0. 0. 6. 0.5 0.25
0. 1. 0. 1. 7. 0.7071068 0.5
0. 1. 1. 0. 8. 0.7071068 0.5
0. 0. 1. 0. 9. 0.5 0.25
0. 0. 1. 1. 10. 0.7071068 0.5
0. 0. 0. 1. 11. 0.5 0.25
1. 1. 1. 0. 12. 0.8660254 0.75
1. 1. 0. 1. 13. 0.8660254 0.75
1. 0. 1. 1. 14. 0.8660254 0.75
0. 1. 1. 1. 15. 0.8660254 0.75
1. 1. 1. 1. 16. 1. 1.
Different elements have the same distance. All the 1-point elements {2,6,9,11}, all the 2-point elements {3,4,5,7,8,10} as well all the 3-point elements {12 - 15} can not be distinguished by the two measures. This means that an input vector with
![]() can not be distinguished from the input vector
can not be distinguished from the input vector
![]() . Therefore no new creation of an evolving neuron would happen.
. Therefore no new creation of an evolving neuron would happen.
Then one has to clarify whether the differences between the desired output vector ![]() and the calculated output vector
and the calculated output vector ![]() are finegrained enough to distinguish between the cases. As the examples below show a normalized euclidean distance can be applied to the different combinations of
are finegrained enough to distinguish between the cases. As the examples below show a normalized euclidean distance can be applied to the different combinations of ![]() and
and ![]() and it can distinguish whether all elements are the same or one or two elements are different. From this it would follow that an error threshold
and it can distinguish whether all elements are the same or one or two elements are different. From this it would follow that an error threshold
![]() would be sufficient to detect the differences (this presupposes, that the activation values of the output neurons are binary values with
would be sufficient to detect the differences (this presupposes, that the activation values of the output neurons are binary values with
![]() .
.
-->Oc
Oc =
0. 0.
0. 1.
1. 0.
1. 1.
-->Od
Od =
0. 0.
0. 1.
1. 0.
-->distinctionOcOd(Oc,Od)
Oc 1 Od 1 = Dist 0.000000
Oc 1 Od 2 = Dist 0.707107
Oc 1 Od 3 = Dist 0.707107
Oc 2 Od 1 = Dist 0.707107
Oc 2 Od 2 = Dist 0.000000
Oc 2 Od 3 = Dist 1.000000
Oc 3 Od 1 = Dist 0.707107
Oc 3 Od 2 = Dist 1.000000
Oc 3 Od 3 = Dist 0.000000
Oc 4 Od 1 = Dist 1.000000
Oc 4 Od 2 = Dist 0.707107
Oc 4 Od 3 = Dist 0.707107
A possible training set is shown below: the columns 1-4 represent the input vector ![]() and the colum 5-6 represent the desired output vector
and the colum 5-6 represent the desired output vector ![]() .
.
TR =
1. 1. 0. 0. 1. 0.
1. 0. 0. 0. 0. 0.
1. 0. 1. 0. 0. 0.
1. 1. 0. 0. 1. 0.
0. 1. 0. 0. 0. 0.
0. 1. 1. 0. 0. 0.
1. 1. 0. 0. 1. 0.
0. 0. 0. 1. 0. 0.
1. 1. 0. 1. 0. 0.
1. 1. 0. 0. 1. 0.
0. 1. 1. 1. 0. 0.
1. 0. 0. 0. 0. 0.
0. 0. 1. 1. 0. 1.
1. 0. 1. 0. 0. 0.
0. 1. 0. 0. 0. 0.
0. 0. 1. 1. 1. 0.
0. 1. 1. 0. 0. 0.
0. 0. 0. 1. 0. 0.
0. 0. 1. 1. 0. 1.
1. 1. 0. 1. 0. 0.
0. 1. 1. 1. 0. 0.
A more detailed analysis of the SECoS theory as well as implementation (see technical Appendix) will be done during August 09.
Gerd Doeben-Henisch 2012-03-31
![\includegraphics[width=4.0in]{secos_appl_2times2_letters.eps}](img1051.png)
![\includegraphics[width=3.5in]{secos_for_appl_2times2_letters.eps}](img1064.png)