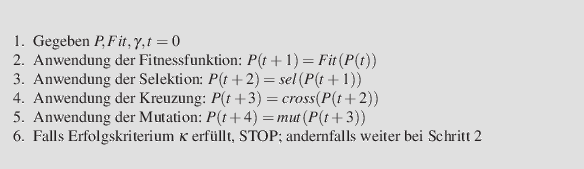Next: Erstes Beispiel: Population P Up: Genetischer Algorithmus ohne Phänotyp Previous: Genetischer Algorithmus ohne Phänotyp Contents
Die Besonderheit bei einem 'Genetischen Algorithmus ohne Phänotyp (GA1)' liegt darin, dass die Interaktion mit der jeweiligen Welt ![]() (oder auch
(oder auch ![]() für 'environment') ohne Phänotyp nicht mehr explizit dargestellt werden kann. Man benötigt dazu dann eine Fitnessfunktion
für 'environment') ohne Phänotyp nicht mehr explizit dargestellt werden kann. Man benötigt dazu dann eine Fitnessfunktion ![]() , die die möglichen Auswirkung der Population der molekularen Informationsspeicher
, die die möglichen Auswirkung der Population der molekularen Informationsspeicher ![]() auf die Welt und dann wieder zurück auf die Population
auf die Welt und dann wieder zurück auf die Population ![]() mittels einer Abbildung auf eine Menge von möglichen Fitnesswerten
mittels einer Abbildung auf eine Menge von möglichen Fitnesswerten ![]() 'simuliert'.
'simuliert'.
Im Falle realer Phänotypen ![]() würden die Phänotypen während ihrer Lebenszeit 'Nachkommen' in Form neuer molekularer Speicher
würden die Phänotypen während ihrer Lebenszeit 'Nachkommen' in Form neuer molekularer Speicher ![]() erzeugen. Die Fähigkeit, unter den Bedingungen er 'realen Welt' hinreichend Energie einzusammeln, strukturell umzusetzen und zusätzlich 'Baupläne' in Form von molekularen Speichern weiter geben zu können.
erzeugen. Die Fähigkeit, unter den Bedingungen er 'realen Welt' hinreichend Energie einzusammeln, strukturell umzusetzen und zusätzlich 'Baupläne' in Form von molekularen Speichern weiter geben zu können.
Den Verzicht auf Phänotypen kann man einerseits als eine 'Verarmung' an Information ansehen, andererseits stellt aber diese Vereinfachung auch eine Art von 'Verallgemeinerung' dar: unter Absehung von vielen Details kann man über eine Problemstellung sehr 'abstrakt' sprechen. Bevor dies im Folgenden anhand einiger Beispiele näher betrachtet wird, muss aber der Informationsbearbeitungsgenerator ![]() etwas mehr erläutert werden (vgl. 3.11).
etwas mehr erläutert werden (vgl. 3.11).
Würden die molekularen Speicher unverändert 1-zu-1 weiter gegeben, dann gäbe es im allgemeinen Fall immer die gleichen Phänotypen bzw. bei GA1 würde sich die Wirkung der aktuellen Population ![]() nicht ändern. Damit hätten wir nur ein 'statisches' Wissen.
nicht ändern. Damit hätten wir nur ein 'statisches' Wissen.
In der biologischen Evolution lassen sich schon sehr früh Mechanismen beobachten, die dem Zweck dienen, die bestehenden molekularen Speicher bei der Weitergabe (biologisch: 'Vererbung') abzuändern, zu variieren. Dabei gibt es zwei Grundprinzipien: (i) bestehende Informationen von zwei molekularen Speichern
![]() zu 'mischen' (und dabei die benutzten Informationen zu konservieren) oder (ii) Teile von bestehenden Informationen zu 'zerstören', indem man diese durch andere Werte 'ersetzt' (nicht konservierend). Die konservierende Methode bezeichnet man meistens als 'Kreuzung' (Engl.: 'crossover') und die revolutionäre Methode als 'Mutation'. Die Mutation wird dabei in zufälliger Weise vorgenommen.
zu 'mischen' (und dabei die benutzten Informationen zu konservieren) oder (ii) Teile von bestehenden Informationen zu 'zerstören', indem man diese durch andere Werte 'ersetzt' (nicht konservierend). Die konservierende Methode bezeichnet man meistens als 'Kreuzung' (Engl.: 'crossover') und die revolutionäre Methode als 'Mutation'. Die Mutation wird dabei in zufälliger Weise vorgenommen.
Man kann sich jetzt fragen, wozu man das Ganze macht; warum überhaupt ändern?
Im allgemeinen Fall GA2 ist klar, man möchte die Struktur eines biologischen Systems mit Blick auf bestimmte 'Leistungsparameter' 'optimieren'. Sei ![]() ein solcher zu optimierender Parameter, der von mindestens einer veränderlichen Bedingung
ein solcher zu optimierender Parameter, der von mindestens einer veränderlichen Bedingung ![]() abhängt, dann sucht man diejenigen Werte
abhängt, dann sucht man diejenigen Werte
![]() die ein bestimmtes 'Erfolgskriterium'
die ein bestimmtes 'Erfolgskriterium' ![]() erfüllen, etwa dass es eine Teilmenge
erfüllen, etwa dass es eine Teilmenge
![]() gibt, die das Erfolgskriterium
gibt, die das Erfolgskriterium ![]() erfüllt und
erfüllt und ![]() soll darin vorkommen. Dies impliziert, dass es irgendeine 'Ordnung'
soll darin vorkommen. Dies impliziert, dass es irgendeine 'Ordnung' ![]() gibt, sodass für je zwei Werte
gibt, sodass für je zwei Werte ![]() gilt
gilt ![]() oder
oder ![]() . In diesem Fall ist es normalerweise dann entscheidbar, ob ein bestimmter Wert
. In diesem Fall ist es normalerweise dann entscheidbar, ob ein bestimmter Wert ![]() sich dem Ziel 'nähert' oder nicht. Schwieriger wird es nur, wenn die Werte von
sich dem Ziel 'nähert' oder nicht. Schwieriger wird es nur, wenn die Werte von ![]() keine monotone Kurve bilden sondern mehrere (relative) Maxima und Minima besitzen.
keine monotone Kurve bilden sondern mehrere (relative) Maxima und Minima besitzen.
Nimmt man an, dass eine Fitnessfunktion nun genau dies leistet, nämlich für eine gegebene Veränderliche ![]() den jeweiligen Wert
den jeweiligen Wert
![]() zu ermitteln, und nimmt man ferner an, dass die Veränderliche
zu ermitteln, und nimmt man ferner an, dass die Veränderliche ![]() jeweils der Informationsstring
jeweils der Informationsstring ![]() eines molekularen Speichers ist, dann berechnet die Fitnessfunktion
eines molekularen Speichers ist, dann berechnet die Fitnessfunktion ![]() für jeden solchen Informationsstring einen zugehörigen Fitnesswert, den man als 'Abstand' zum 'Ziel' interpretieren kann.
für jeden solchen Informationsstring einen zugehörigen Fitnesswert, den man als 'Abstand' zum 'Ziel' interpretieren kann.
Mit dieser Interpretation kann man dann sagen,dass die Anwendung der Fitnessfunktion ![]() eine 'Bewertung' für jeden einzelnen molekularen Speicher
eine 'Bewertung' für jeden einzelnen molekularen Speicher ![]() in dem Sinne liefert, dass damit zwischen 'besseren' und 'schlechteren' molekularen Speichern unterschieden werden kann. Damit erhält man einen Anknüpfungspunkt welche der molekularen Speicher man weiter verwenden und welche man eher eliminieren sollte. Dies führt dann zu der dritten Teilfunktion des Informationsbearbeitungsgenerators
in dem Sinne liefert, dass damit zwischen 'besseren' und 'schlechteren' molekularen Speichern unterschieden werden kann. Damit erhält man einen Anknüpfungspunkt welche der molekularen Speicher man weiter verwenden und welche man eher eliminieren sollte. Dies führt dann zu der dritten Teilfunktion des Informationsbearbeitungsgenerators ![]() : er 'selektiert' mit der Teiloperation 'Selektion'
: er 'selektiert' mit der Teiloperation 'Selektion' ![]() die 'Besseren' und vergisst die 'Schlechteren'.
die 'Besseren' und vergisst die 'Schlechteren'.
Der gesamte Prozess verläuft dann also wie folgt:
GA1-Basis-Algorithmus
Software: Falls nicht abweichend festgestellt werden alle folgenden Theoriebeispiele mit Programmbeispielen in der Programmierumgebung scilab (siehe http://www.scilab.org) illustriert. Den Quellcode findet man im Anhang im Abschnitt 'Programmbeispiele'8.1.
Gerd Doeben-Henisch 2014-01-14
![\includegraphics[scale=.85]{GA1-2-Structure.eps}](img157.png)