|
Fachbereich 2 Studiengang: Informatik Doz: Döben-Henisch Letzte Änderung: 28.April 2004, 23:56h Seite
|
|
Fachbereich 2 Studiengang: Informatik Doz: Döben-Henisch Letzte Änderung: 28.April 2004, 23:56h Seite
|
|
Simulation von Wissen - Modellierung von Adaptivität 2 Psycho-Informatik >> Achtung : Skript gibt den mündlichen Vortrag nur unvollständig wieder !!! <<< |
Einführung
Nachdem nun aufgezeigt worden ist, dass die Verwendung des CLIPS-Formalismus aus theoretischer Sicht keinerlei Einschränkung hinsichtlich der Turingberechenbarkeit bedeutet, soll nun speziell der Frage nachgegangen werden, wie sich im allgemeinen Rahmen der Berechenbarkeit die Frage der Lernfähigkeit darstellen lässt.
Lernen mit einer universellen Turingmaschine (Starkes Lernen)
Bei diesen Überlegungen wollen wir so vorgehen, dass wir die Frage zunächst ganz allgemein stellen und entsprechend allgemein beantworten; dann soll dieses allgemeine Schema anhand von Beispiele konkretisiert werden.
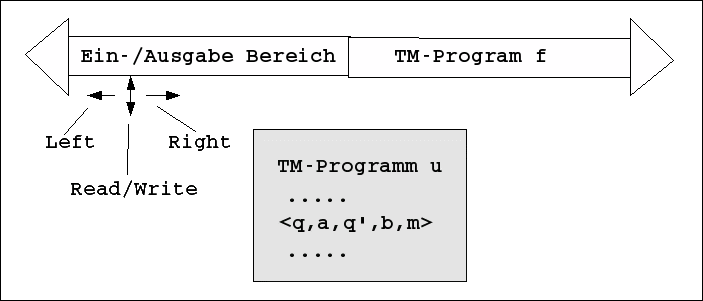
Die universelle Turingmaschine (siehe z.B.: <a href="../../../I-THINF/TH-THINF/VL3/i-thinf-th3.html#universellen">Universelle Turingmaschine</a>) besteht aus einem Turingmaschinenprogramm u und einem nach zwei Seiten hin offenen Band, das an irgendeiner Stelle geteilt ist. Die linke Hälfte ist für Ein-Ausgabedaten reserviert und die rechte Hälfte für ein beliebiges Turingmaschinenprogramm f. Ferner existiert ein Schreib-Lese-Kopf, der in beide Richtungen frei bewegt werden kann.
Der Inhalt des Turingmaschinenprogramms u besteht darin, dass es jedes beliebige Turingmaschinenprogramms f samt den zugehörigen Ein-Ausgabedaten simulieren kann.
Betrachtet man eine universelle Turingmaschine als ein Input-Output-System, dann würde das Verhalten des Systems von der Funktion f festgelegt. die Funktion f würde bestimmen, auf welche Eingabe mit welcher Ausgabe zu antworten ist. Da das Turingmaschinenprogramms u das Turingmaschinenprogramms f nicht verändert, sondern rein passiv simuliert, würde sich das Verhalten der Funktion f grundsätzlich niemals verändern, auch wenn das Verhalten von f für einen menschlichen Beobachter möglicherweise abwechslungsreich und 'undurchschaubar' erscheinen mag.
Wollte man, dass sich das Turingmaschinenprogramm f ändert, dann müsste man das Turingmaschinenprogramm u so abändern, dass es neben dem 'passiven' Simulationsteil auch noch einen 'kreativen' Generator besitzt, der bei Aktivierung die Funktion f zu einer neuen Funktion f' abändern könnte.
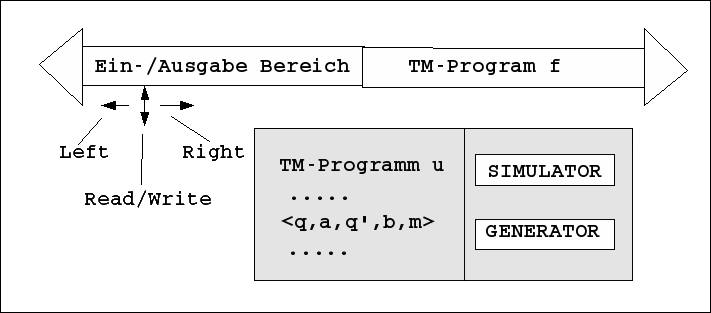
Ein u-Generator könnte also beliebige Turingmaschinenprogramme f erzeugen, die dann der u-Simulator ablaufen lassen würde. Hier stellt sich jedoch die Frage nach der Verfügbarkeit von Bewertungskriterien, die es erlauben würden, das Verhalten eines Programms f in den Dimensionen von besser und schlechter einstufen zu können. Denn ohne solche Bewertungskriterien würde das Generieren von alternativen Funktionen wenig Sinn machen; ob Funktion f, f', f'' oder welche auch immer, es wäre formal gesehen 'egal'. Nur bei Vorhandensein einer wie immer gearteten Bewertungsfunktion B wäre es möglich, eine Menge von Funktionen F = {f, f', f'',...} mittels 'besser' und 'schlechter' zu ordnen und damit ein Ranking einzuführen. Dies bedeutet, dass ein Generator noch ergänzt werden muss um einen Evaluation, der anhand von Feedbackwerten ein Ranking über dem Output eines Generators ermöglicht.
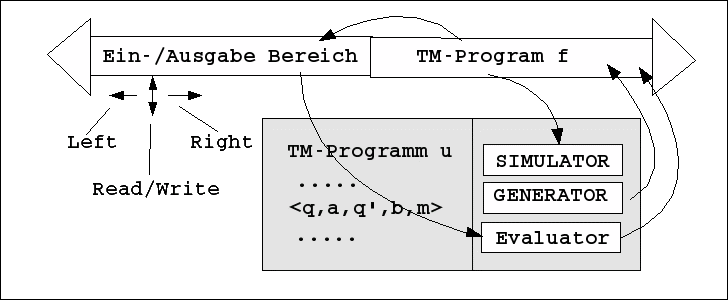
Beispiele für Lernen mit Generator und Evaluator:
- ein Generator erzeugt Bildbeschreibungen, diese werden von Zuschauern bewertet;
- ein Generator erzeugt Baupläne, diese werden von Kunden und Architekten bewertet;
- ein Generator erzeugt Schaltungen, diese werden von Konstrukteuren bewertet;
- ein Generator erzeugt Programme, diese werden von Anwendern bewertet.
- Bei der Teilung von Zellen wird genetische Information kopiert, dieser Kopiervorgang ist nicht 1-zu-1 sondern erzeugt generiert Veränderungen, die zu unterschiedlichen Verhaltensleistungen führen, die wiederum mittel- bis langfristig über den biologischen und sozialen Erfolg der darauf aufbauenden Systeme entscheidet;
- ein Generator erzeugt Pläne für Projekte oder Prozesse, die durch Kostenfunktionen verbunden mit zeit- und Ressourcenfunktionen bewertet werden.
- ein Generator erzeugt Gedichte; diese werden von Zuhörer/ Lesern bewertet.
- ein Generator erzeugt Musikstücke, diese werden von Zuhörern/Tänzern bewertet.
Beispiele für Generatoren sind bestimmte Typen von künstlichen neuronalen Netzen, genetische Algorithmen oder spezielle Ersetzungssysteme.
Lernen mit einer universellen Turingmaschine (Schwaches Lernen)
Die bisherigen Überlegungen gehen von einer sehr starken Form des Lernens aus, nämlich der Veränderung des gesamten Verhaltens unter Berücksichtigung eines Erfolgskriteriums.
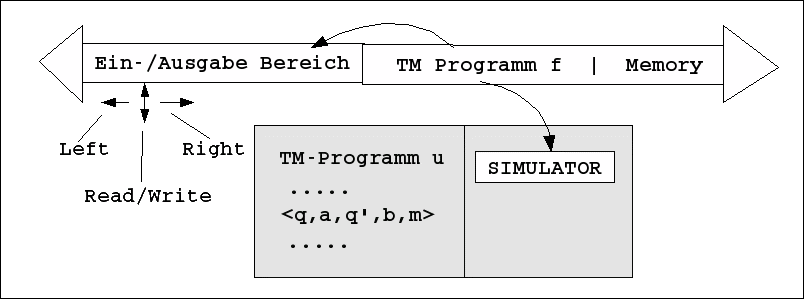
Generell kann man sich auch eine andere schwache Form des Lernens vorstellen, bei der die Funktion f sich nicht ändert; allerdings benötigt diese Form des Lernens explizit neben der Funktion f ein Teilband M, das nicht die ein- bzw. Ausgabe bedient, sondern als Gedächtnis (Memory) fungiert.
Diese schwache Form des Lernens ist datengetrieben; sie sammelt Daten nach bestimmten Kriterien und ordnet diese Daten im Gedächtnis in einer Weise an, durch die Zusammenhänge sichtbar werden, die die einzelnen Daten 'für sich alleine' nicht erkennen lassen.
Beispiele für datengetriebenes Lernen:
- man lernt Daten nach bestimmten Kriterien zu klassifizieren, x gehört zum Eigenschaftsbündel K und nicht R (Kindern lernen, welche Gegenstände Stühle sind, Tische, Autos, Hunden, Pflanzen usw.)
- Eine Variante von diesen Klassifikation ist die Einführung eines Ähnlichkeitsmasses S, so dass man sagen kann, dass x einem y ähnlich ist (Kinder sind in der Lage, ähnliche Dinge zu identifizieren).
- Eine andere Variante ist das Induzieren einer Regel, d.h. das Auffinden einer Beziehung zwischen mindestens zwei verschiedenen Arten von Ereignissen. Beziehungen können dabei sehr unterschiedlich sein:
-> Assoziative Beziehungen besagen z.B., dass x sehr häufig mit y zusammen auftritt, oder das x mit einer bestimmten Wahrscheinlichkeit mit y auftritt, wenn der Kontext k gegeben ist (so lernen Kinder Beziehungen zwischen Worten einer Sprache und Gegenständen/ Situationen/ Gefühlen...).
-> Kausale Beziehungen besagen, dass, wenn das Ereignis x auftritt, mit einer bestimmten Wahrscheinlichkeit dann das Ereignis y folgt (so lernen Kinder kausale Ursache-Wirkungszusammenhänge erkennen).
-> Logische Beziehungen besagen, dass aus dem Gegebensein bestimmter Sachverhalte unter Wahrung der 'Wahrheit' bestimmte andere Sachverhalte folgen.
-> Normative Beziehungen besagen, dass bestimmte Beziehungen gelten, weil bestimmte Personen vereinbart haben, dass diese Beziehungen gelten sollen (so muss man Regeln des Straßenverkehrs lernen, weil sie so vereinbart worden sind; desgleichen in Spielen, bei der Kleidung, bei bestimmten gesellschaftlichen Anlässen usw.).
Natürlich kann man sich auch Kombinationen von schwachem und starken Lernen vorstellen. Angenommen man hat eine Funktion f*, mit der sich schwaches Lernen im Bereich des induktiven Findens von Beziehungen realisieren lässt. Man könnte sich jetzt einen u-Generator mit einem u-Evaluator denken, der die Funktion f* so lange abändert, bis die Feedbackwerte deutlich besser sind als bei der Funktion f.
Schwaches Lernen; Paradigma der Psycho-Informatik
Das Beispiel des schwachen Lernens führt in Themen, die traditionellerweise im Bereich der Psychologie angesiedelt werden.
Die Psychologie ist eine komplexe Wissenschaft (siehe für einen exzellenten historischen und systematischen Überblick [MARX/CRONAN-HILLIX 1987]). Für die Überlegungen hier im Seminar sei nur auf die folgenden Aspekte hingewiesen.
Seit ungefähr Mitte des 20.Jahrhunderts gibt es im Bereich der Psychologie einen fassbaren Teilbereich der Kognitiven Psychologie, dessen Untersuchungsgegenstand die geistigen Leistungen des Menschen sind. Diese moderne Version der kognitiven Psychologie basiert auf empirischer Beobachtung, betrachtet die geistigen Fähigkeiten als Eigenschaften der zugrundeliegenden Physiologie und sieht den Menschen mit seinem Körper als Teil eines biologischen evolutiven Zusammenhanges. Zur Deutung der empirischen Daten werden formale Modelle entwickelt, die einerseits das Format formaler wissenschaftlicher Theorien besitzen wie auch Computermodelle dieser wissenschaftlicher Theorien. In diesem Zusammenhang spricht man auch von Kognitionswissenschaft (Cognitive Science). Wir werden im folgenden aber den Begriff Kognitionspsychologie beibehalten.
Aus Sicht der Informatik ist die Kognitionspsychologie mindestens zweifach interessant. Ganz pragmatisch gibt es eine Wechselwirkung zwischen Informatik und Psychologie dadurch, dass die Kognitionspsychologie intensiv formale Modelle für ihre Theoriebildung benutzt. Und da es sich meistens um dynamische Modelle nicht geringer Komplexität handelt, sind diese in großem Umfang computerbasierte Modelle.
Neben diesem pragmatischen Aspekt gibt es aber auch noch einen inhaltlichen Aspekt: die moderne Kognitionspsychologie geht --nicht zuletzt auch bedingt durch die zunehmenden Einsichten der Hirnforschung-- davon aus, dass geistigen Leistungen des Menschen --wie generell biologischer Systeme-- auf Prozessen beruhen, in denen Informationen ausgetauscht/ geformt/ gewandelt etc. werden. Die Modelle der Kognitionspsychologen sind von daher auch abstrakte Modelle der Informationsverarbeitung, die bis hinunter zu neuronalen Prozessen reichen können. Aufgrund dieser inhaltlichen Bestimmung gibt es eine sehr genuine Nähe zur Informatik.
Informatik definiert sich historisch und systematisch zwar primär nicht (!) über Information, sondern über Berechenbarkeit, der Aspekt der Informationsverarbeitung ist aber über den Aspekt der Verarbeitung mit dem Konzept der Berechenbarkeit verknüpft. Sofern man also irgendwelche Informationen irgendwie verarbeiten will, muss man sich mit der Problematik der Verarbeitung beschäftigen. Und hier stellen jene Verarbeitungsprozesse, die als berechenbare Prozesse gelten, eine Prozessklasse von eminenter praktischer Bedeutung dar.
In diesem tieferliegenden inhaltlichen Sinne kann man sagen, dass Kognitionspsychologie und Informatik eine sehr starke und intensive Überschneidung aufweisen. Entsprechend der Begriffsbildung Bio-Informatik erscheint es von daher gerechtfertigt, hier auch von Psycho-Informatik als jener hybriden Disziplin zu sprechen, in der kognitionspsychologische Sachverhalte mit den Methoden der Informatik modelliert und implementiert werden.
Im weiteren Verlauf dieses Seminars werden wir daher das Paradigma der Psycho-Informatik als methodischen Rahmen voraussetzen und innerhalb dieses Paradigmas einige wichtige Themen weiter beleuchten.
Die generelle Aufgabenstellung der Informatik besteht im allgemeinen Fall darin, ein Kundenproblem in ein berechenbares Modell zu übersetzen und dieses für den praktischen Einsatz zu implementieren. Je komplexer die Aufgabenstellung und je spezifischer das Problem ist, umso mehr geht spezielles Anwendungswissen bzw. spezielles Fachwissen in die Modellierungsaufgabe ein. Es genügt dann nicht, ein generelles Informatik-Wissen bzgl. möglicher Hardware, Software und Algorithmen zu besitzen, sondern man benötigt Spezialwissen über spezifische Prozesse, für die man dann spezifische Hardware bzw. Algorithmen entwickeln muss.
Dieser allgemeine Grundsatz gilt dann auch für den Anwendungsbereich der Modellierung geistiger Prozesse. Das Thema Wissensrepräsentation, Lernen, Schließen, Kommunikation usw. kann man zwar prinzipiell auch ohne Bezugnahme auf spezielle Anwendungsszenarien entwickeln, aber, wie die Geschichte der Informatik zeigt, sind die Ansätze einer reinen künstlichen Intelligenz (Pure Artificial Intelligence) wenig fruchtbar und in der Regel wenig geeignet, um konkrete Anwendungsprobeme zu lösen. Der übergeordnete Begriff für reine angewandte computerbasierte Wissenschaft ist heute Computational Science.
Die Erfahrung zeigt, dass der 'Wirkungsgrad' der informatikbasierten Modellierungen erheblich zunimmt, wenn er sich mit speziellem Fachwissen verknüpft, hier also mit dem speziellen Fachwissen der Kognitionspsychologie.
Während die fachspezifische Lösung des Problems von der Kognitionspsychologie betrieben wird, geschieht die Umsetzung in berechenbare Prozesse mit Hilfe des Fachwissens der Informatik.
In der Vergangenheit konnte man öfters das Argument hören, dass es bei der Erarbeitung von künstlicher Intelligenz nicht darum gehen könnte, die Eigenart der menschlichen Intelligenz nachzubauen, sondern man sollte stattdessen versuchen, allgemeine Strukturen zu entwickeln, die Intelligenz in einem allgemeineren Sinne realisiert.
Es zeigten sich dann aber mindestens zwei fundamentale Probleme. (i) Auf der einen Seite ist völlig unklar, was eine 'allgemeine' Intelligenz sein soll, sofern man sie nicht über die vom Menschen her bekannten Intelligenzformen definieren kann; zum anderen (ii) ergibt sich das praktisch sehr wichtige Problem, dass künstliche intelligente Strukturen nur dann mit einem Menschen auf menschliche Weise kommunizieren können, wenn diese künstlichen intelligenten Strukturen die Besonderheit des menschlichen Verstehens und Kommunizierens mindestens soweit beherrschen, wie die Menschen selbst. Mögliche Erweiterungen der menschlichen Formen von Intelligenz mögen für die Zukunft dann zwar auch von Interesse sein, aber zunächst einmal benötigen wir künstliche intelligente Strukturen, die mindestens mit dem Menschen auf menschliche Weise kommunizieren können.
Aus diesem Sachverhalt leitet sich dann die Aufgabenstellung ab, im Rahmen einer Psycho-Informatik die Erkenntnisse der Kognitionspsychologie so zu nutzen, dass es möglich wird, smarte künstliche Assistenten im Bereich Kommunikation und Wissen zu entwickeln.
Die nachfolgende Tabelle zeigt ein vereinfachtes Schema der Wechselwirkung zwischen Kognitionspsychologie und Informatik im Rahmen des Psycho-Informatik Paradigmas:
Ausgangspunkt sind kognitionspsychologische Annahmen in Form von ersten Modellvorstellungen über geistige Leistungen des Menschen. Diese Annahmen werden transformiert in geeignete empirische Experimente mit menschlichen Versuchspersonen (VPNs). Aufgrund der experimentellen Ergebnisse wird das Modell entweder bestätigt oder partiell korrigiert. Das auf diese Weise validierte Modell wird dann in ein berechenbares (computerbasiertes) Modell transformiert. Die kognitionspsychologischen Experimente werden dann mit dem Informatik Modell als künstlicher Versuchsperson wiederholt. Dies kann zu einer Modifikation des Modells führen. Anschließend wird das Informatik Modell wieder mit dem ursprünglichen kognitionspsychologischen Modell abgeglichen. Damit werde ein typischer Abschnitt in einem langen (evolutionären) Prozess der kognitionspsychologischen Modellbildung unter Einbeziehung der Informatik beschrieben.
|
Phase |
Experiment |
Theorie |
|---|---|---|
|
1 |
|
Kognitionspsychologisches Modell vorher |
|
2 |
Kognitionspsychologisches Experiment mit menschlichen VPNs |
|
|
3 |
|
Kognitionspsychologisches Modell nachher |
|
4 |
|
Informatik Modell vorher |
|
5 |
Kognitionspsychologisches Experiment mit künstlichen VPNs |
|
|
6 |
|
Informatik Modell nachher |
|
7 |
|
Kognitionspsychologisches Modell nachher |
Tab: Typischer Zyklus im Rahmen des Prozesses der kognitionspsychologischen Modellbildung unter Einbeziehung der Informatik
Im weiteren Verlauf werden wir jetzt ein erstes Beispiel einer kognitionspsychologischen Modellbildung zu Aspekten der menschlichen Wahrnehmung vorstellen. Bezogen darauf werden wir die Anwendungsbeispiele aus der ersten Vorlesung diskutieren, inwieweit diese kognitionspsychologische Modellbildung für diese Beispiele anwendbar ist. Schließlich wird gefragt werden, ob und wie sich die kognitionspsychologischen Modelle in computerbasierte Modelle transformieren lassen.
Es soll hier ein erstes kognitionspsychologisches Modell aus dem Bereich schwaches Lernen vorgestellt werden. Aus diesem sehr umfangreichen Gebiet beginnen wir mit Modellvorstellungen im Kontext der menschlichen Wahrnehmung (Wir folgen hier zunächst [ANDERSON 1998:Kap2-3]).
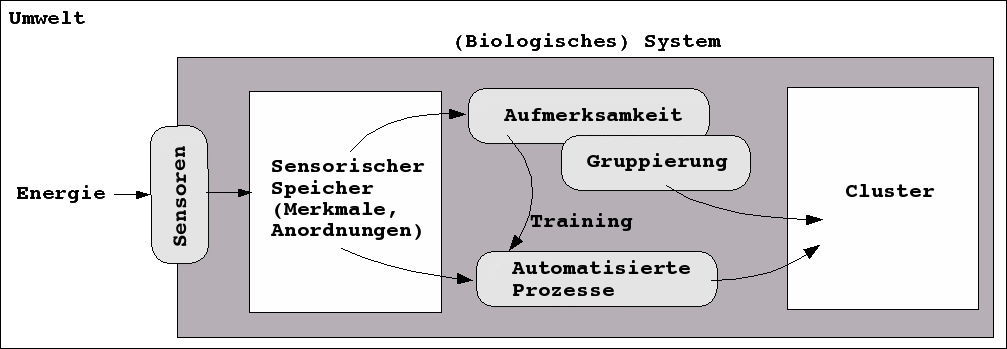
Anderson geht --im Einklang mit vielen anderen Kognitionspsychologen-- davon aus, dass Reize aus der Umgebung des biologischen Systems-- in Form von Energie auf Sensoren trifft, die diese Energie --je nach Typ des Sensors-- in unterschiedliche Weise umkodieren und in sogenannten sensorischen Speichern für kurze Zeit verfügbar halten. Im sensorischen Speicher sind die Umweltreize in Form typischer Merkmale repräsentiert, die zudem mit bestimmten Ordnungsstrukturen (z.B. räumliche Anordnung) verknüpft sind.
Aus den sensorischen Speichern --jeder Sensortyp hat seine eigenen sensorischen Speicher-- gelangen die Inhalte nur dann zur weiteren Verarbeitung, wenn entweder bestimmte Merkmale durch die Aufmerksamkeit aktiv ausgewählt werden der wenn durch zuvor trainierte Wahrnehmungsabläufe bestimmte Merkmale dann automatisch erfasst und weitergereicht werden.
Bei der 'Entnahme' aus dem sensorischen Speicher werden die Merkmale samt ihren impliziten Ordnungselementen automatisch nach bestimmten Regeln (Gestaltregeln, Plausibilitätsregeln) gruppiert und in Clustern verfügbar gemacht. Bei der Identifizierung von einzelnen Merkmalen wirken schon vorhandene Cluster dahingehend mit, dass sie als mögliche Kontexte Alternativen de-selektieren und bestimmte Deutungen favorisieren.
(Anmerkung: Zum genaueren Verständnis müssen die wichtigen Experimente zur Datengewinnung studiert werden).
In der ersten Sitzung hatten wir einige Beispielzenarien vorgestellt, die realistischen Situationen entsprechen. Wir werden jetzt exemplarisch schauen, inwieweit die soeben eingeführte erste kognitionspsychologische Modellbildung sich auf diese Szenarien anwenden lässt.
Szenarium 1: Ein Finanzdienstleister berät Kunden bzgl. möglicher Maßnahmen, um Geld zu 'nutzen'
Der Finanzdienstleister kann Daten aus einem persönlichen Gespräch gewinnen, die auf Selbstaussagen des Kunden beruhen. Diese Aussagen können sein Erleben betreffen oder objektive Umstände seines Geschäftes. Über diese objektiven Zustände kann man zusätzliche Messwerte einholen. Diese Daten sind sehr unterschiedliche und z.T. sehr komplex. Sie unterscheiden sich nach der Art, nach dem Miteinander und nach dem Nacheinander.
Szenarium 2: Ein Systemhaus soll für einen Kunden ein Problem lösen. Dazu wird ein Projekt gestartet, das verschiedene Phasen durchläuft und in dem jeweils unterschiedlich Wissen benutzt wird.
Es treten unterschiedliche Typen von Mitarbeitern während der verschiedenen Projektphasen auf, die mit unterschiedlichem Hintergrundwissen und unterschiedlichen Fragen wiederum unterschiedliche Mitarbeiter des Kunden befragen, um wichtige Daten für die Projektmodellierung und Projektumsetzung zu gewinnen. Zusätzlich können objektive Sachverhalte und objektivierte Daten inspiziert werden. Auch hier unterscheiden sich die Daten sehr; sie lassen sich organisieren nach der Art, nach dem Miteinander und nach dem Nacheinander.
Szenarium 3: Ein Arzt trifft auf Patienten, deren Zustand er diagnostizieren muss. Auf der Basis seiner Diagnose muss er dann eine Therapie einleiten.
Der Arzt kann Daten aus dem persönlichen Gespräch gewinnen, die Aussagen über das Erleben des Patienten enthalten. Er kann per Augenschein visuelle Eindrücke gewinnen und er kann aus Messvorgängen spezielle Messdaten bekommen. Diese Daten sind sehr unterschiedliche und z.T. sehr komplex. Sie unterscheiden sich nach der Art, nach dem Miteinander und nach dem Nacheinander. Selten bis nie muss ein Patient längere Testaufgaben absolvieren.
Szenarium 5: Notfallsysteme für Fast-Gesunde: es gibt Menschen, die eigentlich gesund sind, bis auf einige wenige --manchmal nur einen-- 'Parameter', der sporadisch solche abnorme Werte annehmen kann, dass er damit das Leben des Betreffenden gefährdet. In diesem Fall müsste eine smarte Technologie diesen Zustand automatisch diagnostizieren und sofort fachliche Hilfe aktivieren bzw. u.U. direkte Hilfsmaßnahmen einleiten.
In diesem Beispiel gibt es Sensoren, die ganz bestimmte empirische Parameter messen und an eine Datensammelstelle weiterleiten. Auch hier gibt es wieder Art, Miteinander und Sequenz.
Szenarium 6: Smart Objects: stark körperlich behinderte Menschen benötigen Stühle und Betten, die sich von sich aus entsprechend bestimmten Umgebungswerten so verändern, dass sie bestimmten therapeutisch geforderten Umgebungsbedingungen entsprechen.
Ähnlich zu Szenarium 5.
Szenarium 9: Eine Personalagentur will im Rahmen ihrer Assessments ein dialogbasiertes Testwerkzeug einführen, das im Rahmen von Dialogen eine Person bezüglich bestimmter Eigenschaften testet.
Hier wäre das dialogbasierte Testwerkzeug das System, das eine Versuchsperson als Teil einer Umgebung wahrnimmt. Es ist eine zu klärende Frage, welche Daten solch ein Testwerkzeug von einer VPN über die sprachlichen Äußerungen im Rahmen eines Dialoges hinaus bekommen kann/soll. Je nach Test wird es sich sicher um ganz unterschiedliche Reaktionsdaten handeln. Auch diese werden sich nach Art, Miteinander und Nacheinander organisieren lassen.
Szenarium 10: Große Gebäude verlangen nach ausgefeilten Systemen der Steuerung und Überwachung.
In diesem Szenarium kann es eine Vielzahl von Sensoren geben (Rauchmelder, Temperatur, Zustandsanzeiger für Türen und Fenster, Videokameras, Geräuschsensoren, Lichtschranken, ...), die unterschiedlichste Daten sammeln. Auch diese werden sich nach Art, Miteinander und Nacheinander organisieren lassen.
Generell kann man diese Beispiele gruppieren in solche, in denen Menschen als entscheidende Akteure auftreten und solche, in denen schon künstliche Systeme vorausgesetzt werden.
Betrachten wir zunächst nur solche, in denen Menschen die Akteure sind. Dies betrifft nur die Szenarien 1-3.
Szenarium 1: Ein Finanzdienstleister berät Kunden bzgl. möglicher Maßnahmen, um Geld zu 'nutzen'
Der Finanzdienstleister kann Daten aus einem persönlichen Gespräch gewinnen, die auf Selbstaussagen des Kunden beruhen. Diese Aussagen können sein Erleben betreffen oder objektive Umstände seines Geschäftes. Über diese objektiven Zustände kann man zusätzliche Messwerte einholen. Diese Daten sind sehr unterschiedliche und z.T. sehr komplex. Sie unterscheiden sich nach der Art, nach dem Miteinander und nach dem Nacheinander.
Szenarium 2: Ein Systemhaus soll für einen Kunden ein Problem lösen. Dazu wird ein Projekt gestartet, das verschiedene Phasen durchläuft und in dem jeweils unterschiedlich Wissen benutzt wird.
Es treten unterschiedliche Typen von Mitarbeitern während der verschiedenen Projektphasen auf, die mit unterschiedlichem Hintergrundwissen und unterschiedlichen Fragen wiederum unterschiedliche Mitarbeiter des Kunden befragen, um wichtige Daten für die Projektmodellierung und Projektumsetzung zu gewinnen. Zusätzlich können objektive Sachverhalte und objektivierte Daten inspiziert werden. Auch hier unterscheiden sich die Daten sehr; sie lassen sich organisieren nach der Art, nach dem Miteinander und nach dem Nacheinander.
Szenarium 3: Ein Arzt trifft auf Patienten, deren Zustand er diagnostizieren muss. Auf der Basis seiner Diagnose muss er dann eine Therapie einleiten.
Der Arzt kann Daten aus dem persönlichen Gespräch gewinnen, die Aussagen über das Erleben des Patienten enthalten. Er kann per Augenschein visuelle Eindrücke gewinnen und er kann aus Messvorgängen spezielle Messdaten bekommen. Diese Daten sind sehr unterschiedliche und z.T. sehr komplex. Sie unterscheiden sich nach der Art, nach dem Miteinander und nach dem Nacheinander. Selten bis nie muss ein Patient längere Testaufgaben absolvieren.
Betrachten wir in dieser Untermenge das Szenarium 3 mit dem Arzt. Zur Situation der Befunderhebung gehört einerseits die Exploration des Patienten, zugleich aber auch die Umsetzung der Beobachtungen in einen sprachlichen Bericht, der in die Patientenakte eingeht. Dabei ist zu beachten, dass der Bericht nicht beliebige sprachliche Ausdrücke verwenden darf, sondern möglichst nur solche medizinischen Fachtermini, die in ihrer Bedeutung durch Bezugnahmen auf klar vereinbarte Phänomene möglichst normiert sind (der IDC-10-GM-Diagnosethesaurus in der Version von 2004 enthält über 100.000 medizinische Fachtermini!).
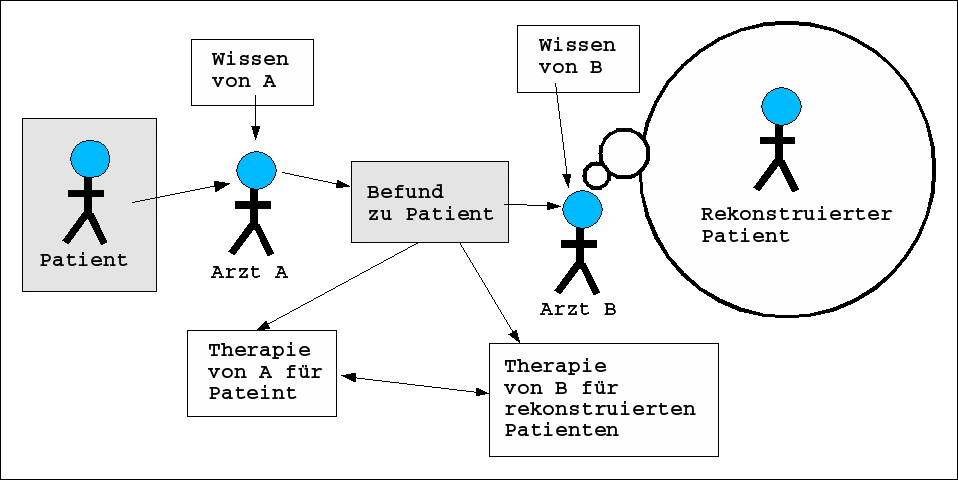
Abstrakt gesprochen hat der Arzt A eine doppelte Aufgabe zu lösen: (i) er hat eine Wahrnehmung nicht-sprachlicher Sachverhalte SA, die er (ii) mittels vereinbarter Begriffe so kodieren soll L( SA ) , dass ein anderer medizinisch geschulter Experte B aus dieser Beschreibung L( SA ) den gleichen Sachverhalt ( := SA ) erschließen kann, wie der, der dem Bericht von Arzt A zugrunde lag. Ferner soll der Arzt A aus dem Befundbericht und seinem medizinischen Fachwissen WA einen Therapievorschlag ableiten CONSA(L( SA ), WA ) = TherapieA. Idealerweise kommt Kollege B mit mit seinem Fachwissen WB zum gleichen Therapievorschlag CONSB(L( SA ), WB ) = TherapieA.
Diese Situation hat strukturell Ähnlichkeiten mit der Situation eines Kindes K, das lernen muss, seine Wahrnehmung der Umgebung SK sprachlich so zu kodieren L(SK ), dass die Eltern aufgrund der sprachlichen Äußerungen L(SK ) erschließen können, was ( := SK )das Kind wohl gemeint haben könnte. Zusätzlich kann es sein, dass das Kind aufgrund seiner kodierten Wahrnehmung im Lichte seines bisherigen Wissens WK zu Schlussfolgerungen CONSK(L(SK ),WK) = HandlkungK darüber kommt, was es jetzt tun sollte. Diese Folgerungen sollten von den Eltern nachvollziehbar sein.
Für die weiteren Überlegungen wollen wir diese letzte Lernsituation mit dem Kind weiter untersuchen.