|
|
I-TI04 WS 04 - Vorlesung mit Übung
|
Im Anschluss an die grundlegenden Begriffe Abzählbarkeit, (rekursive) Aufzählbarkeit, Entscheidbarkeit (bzw. Rekursivität) sowie den Grundbegrifen zu einer formalen Sprache soll nun der Begriff der formalen Grammatik, der syntaktischen Ableitbarkeit der durch die Grammatik G definierten Sprache L(G) eingeführt werden. Mittels dieser Begriffe kann man dann die Chomsky Hierarchie definieren. Ausgehend von der Chomsky Hierarchie werden dann konkrete Untersuchungen zu den ausgewählten Sprachtypen 'reguläre Sprachen' sowie 'kontextfreie Sprachen' mitsamt den zugehörigen Automatentypen 'endlicher Automat' sowie 'Kellerautomat' angestellt. Letzteres aber erst in der Folgevorlesung.
Der Begriff der formalen Grammtik wird zunächst anhand eines Beispiels aus dem Alltag eingeführt.
Wir betrachten einige einfache Sätze der deutschen Sprache.
Hans ist gross.
Hans lacht.
Das Auto fährt schnell.
Susi und Hans treffen sich.
Hans vergisst das rote Buch.
Die Menge der Buchstaben, die in diesem Textfragment vorkommen, sind eine Teilmenge der Zeichen {a,...,z, A, .. Z,ä,ö,ü, Ä,Ö,Ü,.}. Der Einfachheit halber nehmen wir an, dass unser Alphabet V aus allen diesen Zeichen besteht: V = {a,...,z, A, .. Z,ä,ö,ü, Ä,Ö,Ü,.} (man beachte, dass wir den Punkt '.' als Zeichen zulassen!).
Nun betrachten wir die Menge aller Wörter V', die in diesem Textfragmet vorkommen. V' ist nur eine Teilmenge der möglichen Wörter V* über dem Alphabet V:
Hans
ist
gross
lacht
.
Das
Auto
fährt
schnell
Susi
und
treffen
sich
vergisst
rote
Buch
Diese Worte bilden in der Sprache konkrete Objekte, mittels denen kommuniziert wird. Regeln, die über diesen Objekten operieren (bzw. eine Grammatik als Menge von solchen Regeln (s.u.)), müssen über diese konkreten Objekte in einer abstrakteren Weise sprechen. Die Sprachwissenschaftler haben daher schon vor mehr als tausend Jahren sogenannte Wortkategorien erfunden, um Mengen konkreter Wörter unter bestimmten Sammelbezeichnungen (Kategorien, Klassen) zusammenzufassen. Bis heute haftet solchen Wortklassifizierung eine gewisse Beliebigkeit und Unschärfe an. Im Folgenden werden einige Wortkategorien rein experimentell eingeführt. Die Liste von Paaren [Wortkategorie ---> Wort] nennt man im Rahmen einer formalen Grammatik auch ein Lexikon
N ---> Hans, Susi
AUX ---> ist
ADJ ---> gross, schnell, rote
V ---> lacht, fährt, treffen, vergisst
ENDM ---> .
DET ---> Das
CN ---> Auto, Buch
CONJ ---> und
RPR ---> sich
Die Schreibweise 'A ---> b' wird auch Ersetzungsregel (oder Produktion) genannt. Sie besagt, dass die Zeichenkette A duch die zeichenkette b ersetzt werden kann.
Mit diesen Vereinbarungen könnte man das Textfragment jetzt wie folgt umschreiben:
(N,Hans) (AUX,ist) (ADJ,gross) (ENDM,.)
(N,Hans) (V, lacht) (ENDM,.)
(DET,Das) (CN,Auto) (V,fährt) (ADJ,schnell) (ENDM,.)
(N,Susi) (CONJ,und) (N,Hans) (V,treffen) (RPR,sich) (ENDM,.)
(N,Hans) (V,vergisst) (DET,das) (ADJ,rote) (CN,Buch) (ENDM,.)
Da alle diese Wortfolgen Sätze sein sollen (Kategorie 'S'), kann man die Gleichungen einführen:
S ---> N AUX ADJ ENDM
S ---> N V ENDM
S ---> DET CN V ADJ ENDM
S ---> N CONJ N V RPR ENDM
S ---> N V DET ADJ CN ENDM
Die Ersetzungsregeln für S wirken noch sehr umständlich. Man kann versuchen, Optimierungen dadurch einzuführen, dass man 'Zwischenkategorien' einführt, etwa wie folgt:
S ---> NP VP
NP ---> N | DET CN | DET ADJ CN | N CONJ N
VP ---> AUX ADJ | V | V RPR
Damit würde sich dann die folgende Regelmenge ergeben:
S ---> NP VP
NP ---> N | DET CN | DET ADJ CN | N CONJ N
VP ---> AUX ADJ | V | V RPR
N ---> Hans, Susi
AUX ---> ist
ADJ ---> gross, schnell, rote
V ---> lacht, fährt, treffen, vergisst
ENDM ---> .
DET ---> Das
CN ---> Auto, Buch
CONJ ---> und
RPR ---> sich
Mit diesen Regeln könnte man dann einen sogenannten Syntaxbaum erzeugen:
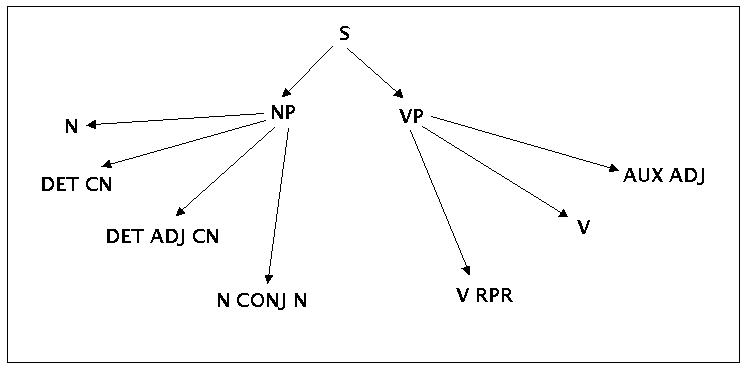
Ein Syntaxbaum zu den Beispielregeln
In Verbindung mit dem Lexikon kann man jetzt alle Sätze generieren, die diese Regeln festlegen. Man stellt leicht fest, dass man jetzt mehr Sätze erzeugen kann, als im ursprünglichen Textfragment vorkommen (=> die Grammtik verallgemeinert, generalisiert!). Ausserdem stellt man fest, dass man Sätze bilden kann, die ein deutscher Sprecher nicht unbedingt als 'volständig korrekt' akzeptieren würde. Beispiele:
Hans vergisst sich (Kann man akzeptieren)
Hans lacht sich (würde man noch ergänzen)
Hans treffen sich (statt treffen erwartet man trifft und noch eine Ergänzung)
Hans fährt sich (mit Ergänzung vielleicht akzeptabel)
Hans und Susi ist gross (mit sind statt ist akzeptabel)
Hans und Susi ist schnell (mit sind akzeptabel)
Hans und Susi ist rote (mit sind rot akzeptabel)
Man sieht, dass man bei natürlichen Sprachen neben der reinen Form zusätzlich sogenannte implizite Faktoren wie Anzahl der Personen, Geschlecht, Aktionszeit usf. mit berücksichtigen muss. Und diese zusätzlichen impliziten Faktoren interagieren über Wortgrenzen hinweg zwischen verschiedenen Kategorien. Diese und weitere Faktoren stellen hohe Anforderungen an eine formale Grammatik der natürlichen Sprachen. Die Tatsache, dass es bis heute keine wirklich umfassende und allgemein akzeptierte formale Grammatik natürlicher Sprachen gibt, lässt erahnen, dass diese Aufgabe nicht leicht zu lösen ist. Im Rahmen der Informatik beschränkt man sich daher in der Regel auf solche Sprachen, die sich im Rahmen von formalen Grammatiken vollständig beschreiben und damit technisch nutzen lassen (Anmerkung: wie schon in vorausgehenden Vorlesungen bemerkt, ist diese Haltung der Informatik in der Zukunft kaum haltbar; es besteht schon heute die klare Herausforderung an die Informatik, leistungsfähigere sprachliche Schnittstellen bereit zu stellen. Diese können aber nur mit leistungsfähigeren theoretischen Modellen realisiert werden. Dazu gehören notwendigerweise semantische, pragmatische und adaptive Elemente!).
Für formale Grammatiken hat sich eine allgemeine Schreibweise eingebürgert, die wir hier als Struktur im Sinne der Algebra und der Wissenschaftstheorie wiedergeben.
x ist eine formale Grammatik [FG(x)] gdw x = < <V,T,{S} > P> mit
V := Menge der Variablen (oder nicht-terminalen Elemente)
T := Menge der terminalen Elemente
S := Das Startsymbol (steht für Satz ('sentence')); es gilt {S} C V
P := Die Menge der Ersetzungs- bzw. Produktionsregeln. Es gilt allgemein P C (V ∪ T)+ x (V ∪ T)*. Dies bedeutet, auf der linken Seite einer Erzeugungsregel muss mindestens ein Zeichen stehen, die rechte Seite kann leer sein.
Man muss jetzt festlegen, was es heisst, dass man mit den Produktions-Regeln einer formalen Grammatik ein zulässiges Wort der Grammatik erzeugt bzw. ableitet.
y ist mit der formalen Grammatik g direkt ableitbar aus x [geschrieben: DABL(y,x,g) oder x =>g y oder x |-g y] gdw
(E:a,b,k,k')( (a,b) ∈ Pg & x = kak' & y = kbk' & a ∈ (Vg ∪ Tg)+ & k,k',b ∈ (Vg ∪ Tg)* )
y ist in g ableitbar aus x [ geschrieben: ABL(y,x,g) oder x *=>g y oder x |--*g y]
gdw
(E:f)( SEQ(f) & (f:Nat ---> (Vg ∪ Tg)* & A:i,j)( i,j ∈ dm(f) & j =i+1 =>
DABL(fj,fi,g) & x = f0 & y =flen(f)-1 ))
'SEQ(f)' heisst, dass f eine Folge ist (siehe mengentheoretische
Grundbegriffe) und x ist das erste Element der Folge und y ist das letzte Element der Folge. Da der Index einer Folge mit Nat
ab 0 läuft, hat das letzte Element einer Folge f den Index len(f)-1 = |dom(f)|-1.
L ist die durch g erzeugbare Sprache [L(g)] = { w | FG(g) & ABL(w,Sg,g) }
Die durch die Grammatik g bestimmte Sprache besteht also aus allen Worten w, die sich aus dem Startelement Sg der
Grammatik g ableiten lassen.
Grammatik g ist äquivalent zu Grammtik g' AEQUIVALENT(g,g')] gdw FG(g) & FG(g') & L(g) = L(g')
Wenden wir das Schema auf das vorausgehende Beispiel an, dann würden wir folgende konkrete Grammatik bekommen:
x ist die formale Grammatik FG1 gdw x = < <V1,T1,{S} > P1> mit
V1 = {A, .., Z}
T1 = {a,...,z, A, .. Z,ä,ö,ü, Ä,Ö,Ü,.} und es gilt: V1 ∩ T1 = 0
S = bleibt
P :=
S ---> NP VP
NP ---> N | DET CN | DET ADJ CN | N CONJ N
VP ---> AUX ADJ | V | V RPR
N ---> Hans | Susi
AUX ---> ist
ADJ ---> gross | schnell | rote
V ---> lacht | fährt | treffen | vergisst
ENDM ---> .
DET ---> Das
CN ---> Auto | Buch
CONJ ---> und
RPR ---> sich
Ein Ausdruck wie
CN ---> Auto | Buch
ist eine verkürzende Schreibweise für
CN ---> Auto
or
CN ---> Buch
Hier ein anderes Beispiel einer einfachen formalen Grammatik g1.
FG(g1) und g1 = <
<Vg1,Tg1,{Sg1} >, Pg1>
mit den Werten:
Vg1 = {E,T,F},
Tg1 = {(,),a,+,*}
Sg1 = E
Pg1 = {(E,T), (E,E + T), (T,F),(T,T * F),(F,a),(F,(E))}
Wir schreiben statt Vg1, Tg1, Sg1, Pg1 einfach V1, T1, S1 und P1.
Zum Verständnis, wie die einzelnen Regeln aus P1 zustandekommen, hier eine ausführliche Darstellung der Elementschaft von P1:
P1 C (V1 ∪ T1)+ x (V1 ∪ T1)*
(a,b) ∈ P1
gdw
(a,b) ∈(V1 ∪ T1)+ x (V1 ∪ T1)*
gdw
a ∈ (V1∪T1)+ & b ∈ (V1∪T1)*
gdw
|
[ a ∈ ({E,T,F} ∪ {(,),a,+,*})+] & [ b ∈ ({E,T,F} ∪ {(,),a,+,*})*] |
|
a ∈ ({E,T,F} ∪ {(,),a,+,*})+ |
b ∈ ({E,T,F} ∪ {(,),a,+,*})* |
{(E,T), (E,E + T), (T,F),(T,T * F),(F,a),(F,(E))}
auch geschrieben als:
{(E --> T), (E --> E + T), (T --> F),(T -->T * F),(F -->a),(F --> (E))}
Ableiten
Satz: E *=>g1 a * a + a ( E |--*g1 a * a + a )
a * a + a ist in g1 ableitbar aus E
gdw
(E:f)(
SEQ(f) & (f:Nat ---> ({E,T,F} ∪
{(,),a,+,*})* & A:i,j)( i,j ∈ dm(f) & j =i+1 =>
DABL(fj,fi,g1) & E = f0 &
a * a + a =flen(f)-1 ))
|
Index von f |
Werte von f |
Regeln f. direkte Ableitung |
|---|---|---|
|
0 |
E |
E --> E + T |
|
1 |
E + T |
E --> T |
|
2 |
T+ T |
T -->T * F |
|
3 |
T * F+ T |
T --> F |
|
4 |
F * F+ T |
T --> F |
|
5 |
F * F+ F |
F -->a |
|
6 |
a * F+ F |
F -->a |
|
7 |
a * a+ F |
F -->a |
|
8 |
a * a+ a |
|
Anhand der Definition von Bäumen kann man eine direkte Zuordnung herstellen zwischen formalen Grammatiken einerseits und Bäumen andererseits. Dies kann man in einem Algorithmus fassen:
Gegeben ist eine formale Grammatik g mit < <Vg,Tg,{Sg} >, Pg>
Gesucht ist ein gerichteter Graph g' mit < <Eg', {rg'} >, Kg'> mit den Werten Eg' = Vg ∪ Tg und rg' = Sg . Dies bedeutet, die Variablen Vg und terminalen Symbole Tg von g werden in die Menge der Ecken Eg' von g' abgebildet; dabei wird das Startsymbol Sg mit dem Wurzelknoten rg' von g' identifiziert. Schliesslich werden die Produktionsregeln Pg in die Menge der Kanten Kg' abgebildet.
Man kann dann auf der Basis der Kanten Kg' dadurch einen Baum konstruieren, dass man, beginnend mit dem Wurzelknoten rg', alle Nachfolger der Wurzel über Pfeile mit der Wurzel verbindet, dann alle Nachfolger der Nachfolger usw.
Wie sich gezeigt hat, ist die oben eingeführte Definition einer formalen Grammatik in ihrer Allgemeinheit so stark, dass sie für solche Anwendungen, in denen in endlichen Zeitintervallen Entscheidungen getroffen werden müssen, solche Entscheidungen entweder garnicht möglich sind oder aber nur mit einem unakzeptablen Zeitaufwand. Dies hat dazu geführt, dass man auch schwächere Formen von formalen Grammatiken untersucht hat, also solche Grammatiken, deren Sprachen sich mittels Automaten in vertretbaren Zeiten 'erkennen' lassen.
Die Formulierung vertretbarer Zeitaufwand ist in diesem Zusammenhang mehrfach ambivalent:
Anwendungskontext: bei klassischer Briefpost erwartet man Antworten in Zeiträumen von einigen Tagen; bei email möglicherweise in Stunden oder Minuten; beim Bremsen im Auto erwartet man 'sofort' eine Reaktion usw.
Hardware: je nach verfügbarer Hardware kann der gleiche Berechnungsprozess Stunden, Minuten oder Sekunden dauern oder gar noch weniger Zeit beanspruchen.
Rekursiv/ Entscheidbar: das Problem ist grundsätzlich entscheidbar, auch wenn es, wie im Fall der Typ-2-Sprachen (s.u.) möglicherweise in der Praxis nicht nutzbar ist.
Im vorliegenden Kontext ist der Fall der entscheidbaren Sprachen von grösstem Interesse. Die folgende auf Noam CHOMSKY zurückgehende Klassifizierung hat sich eingebürgert:
g ist eine formale Grammatik vom Typ 0 [FG(g,0)] (Phrasenstrukturgrammatik, 'Phrase Structure
Grammar' [PSG]) gdw
FG(g) & ∀(v,w) ( (v,w) ∈ P ==> v ∈ (V ∪ T)+ & w ∈ (V ∪ T)* )
g ist eine formale Grammatik vom Typ 1 [FG(g,1)](Kontextsensitive Grammatik, 'Contextsensitive Grammar' [CSG]) gdw
FG(g) & (A:u,w)( (u,w) ∈ Pg => (E:a,b,X,p)([u = aXb & w = apb & X ∈ Vg &
(Fall 1:)[[a,b ∈ (Vg ∪ Tg)* & p ∈ ( Vg ∪ Tg)+ ]
or
(Fall 2:) [u = Sg & p = ε & ¬∃ (u',w')((u',w') ∈ P & Sg ∈ rn(w))]
)
Der entscheidende Punkt ist, dass die Ersetzung von X durch p nur bei Vorliegen des
Kontextes 'a_b' erlaubt ist. Ferner darf p nicht leer sein; Falls man p=ε zulässt, dann darf das Startsymbol S nicht
mehr auf der rechten Seite einer Produktion auftreten.
g ist eine formale Grammatik vom Typ 2 [FG(g,2)](Kontextfreie Grammatik, 'Contextfree Grammar' [CFG]) gdw
FG(g) & (A:u,w)( (u,w) ∈ Pg => u ∈ Vg & w ∈ (V ∪ T)* )
g ist eine formale Grammatik vom Typ 3 [FG(g,3)](Reguläre Grammatik, 'Regular Grammar')gdw
FG(g,2) & RECHTSLINEAR(g) + LINKSLINEAR(g))
g ist eine rechtslineare formale Grammatik vom Typ 3 [RLFG(g,3)] gdw
FG(g,3) & (A:u,w)( (u,w) ∈ Pg =>
(E:a,B)(B in Vg & a in Tg & [w=a or w=aB] ))
g ist eine linkslineare formale Grammatik vom Typ 3 [LLFG(g,3)] gdw
FG(g,3) & (A:u,w)( (u,w) ∈ Pg =>
(E:a,B)(B in Vg & a in Tg & [w=a or w=Ba] ))
L ist die durch eine formale Grammatik vom Typ i erzeugte Sprache [L(g,i)] gdw
L(g,i) = { w | ABL(w,Sg,g) & FG(g,i)}
Satz: L(g,3) C L(g,2) C L(g,1) C L(g,0)
Ein Beispiel für eine kontextsensitive Grammatik ist die Grammatik g2:
FG(g2,1) und g2 = < <Vg2,Tg2,{Sg2} >, Pg2> mit den Werten:
Vg2 = {S,B,C},
Tg2 = {a,b,c},
Sg2 = S
Pg2 = {(S,aSBC), (S,aBC), (CB,BC),(aB,ab),(bB,bb),(bC,bc), (cC,cc)}
Ein Beispiel für eine kontextfreie Grammatik war die vorausgehende Grammatik g1.
Zwei Beispiele für reguläre Grammatiken sind die Grammatiken g3 und g4
FG(g3,3) und g3 = < <Vg3,Tg3,{Sg3} >, Pg3> mit den Werten:
Vg3 = {S},
Tg2 = {0},
Sg2 = S
Pg2 = {(S,0S), (S,0) }
FG(g4,3) und g4 = < <Vg4,Tg4,{Sg4} >, Pg4> mit den Werten:
Vg4 = {S},
Tg4 = {0,1},
Sg4 = S
Pg4 = {(S,0), (S,1), (S,0S), (S,1S) }
Es wird jetzt das Beispiel einer Typ-3-Grammatik g4 im Format einer rechtslinearen Grammatik gegeben, die die folgende Sprache definiert: L(g4,3) = {anne, anke, abzug, ablage}
FG(g4,3) mit g4 = < <Vg4,Tg4,Sg4 > Pg4>
mit
Vg4 = {S, X, Y, Z, G, H, M, V}
Tg4 = {a, b, e, g, k, l, n, u, z}
Pg4 = {(S,aX), (X,bY),(X,nZ),(Y,zV),(Y,lW),(V,uM),(W,aG),(G,gH),(Z,nG),(Z,kG),(M,g),(H,e)}
Vereinbarungsgemäss kann man statt (S,aX) auch schreiben S ---> aX und statt '(X,bY),(X,nZ)' kann man auch schreiben X --> bY | nZ.
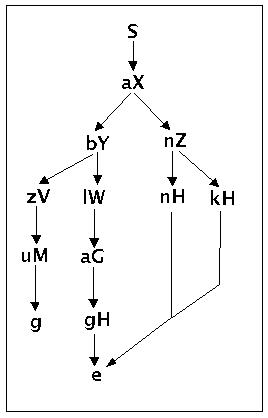
Syntaxbaum zur Grammatik g4
Laut Definition ist ein Wort w dann in der Sprache L(g4,3) wenn w in g4 ableitbar ist, also Sg4 *=>g4 w, und g4 ist eine formale Grammatik vom Typ3, also FG(g4,3). Man müsste also zeigen, dass die Worte {anne, anke, abzug, ablage} alle ableitbar sind und auch nur genau diese.
Eine Möglichkeit, dies zu tun besteht darin, dass man bezogen auf den Syntaxbaum ein allgemeines Verfahren (Algorithmus) definiert, das diesen Baum systematisch absucht. Ein Verfahren wäre das folgende (informelle Beschreibung):
Beginne bei dem Wurzelknoten S
Markiere letzten Knoten und gehe zum nächsten. Wenn es Alternativen gibt, wähle den am weitesten links liegenden Knoten.
Ist der Pfad zu Ende ohne ein terminales Element, dann Fehlermeldung
Andernfalls gebe den Pfad aus.
Backtracking: suche rückwärts den nächsten noch nicht markierten Pfad
Falls es keinen mehr gibt: Ende
Andernfalls setze fort bei 2
Wenn dieses Verfahren keine Fehlermeldung produziert, dann generiert es die Menge aller möglichen Pfade. Hier ein Beispiel für Ableitungen nach diesem Verfahren:
S (S ---> aX)
aX (X ---> bY)
abY (Y ---> zV)
abzV (V ---> uM)
abzuM (M ---> g)
abzug
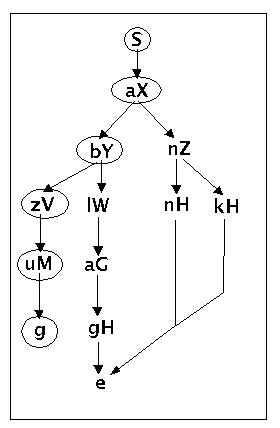
Syntaxbaum zur Grammatik g4 nach erster Ableitung
Ein Pfad im Syntaxbaum ist jetzt markiert. Mittels Backtracking wird jetzt rückwärts nach einer möglichen Fortsetzung gesucht. Diese ist hinter dem Knoten 'bY' gegeben. Es wird also hier eine zweite Ableitung versucht:
S (S ---> aX)
aX (X ---> bY)
abY (Y ---> lW)
ablW (W ---> aG)
ablaG (G ---> gH)
ablagH (H ---> e)
ablage
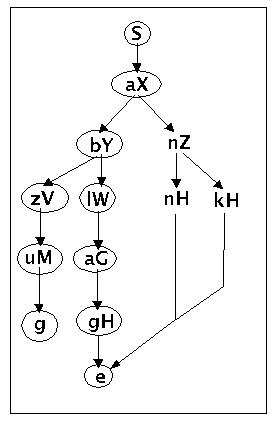
Syntaxbaum zur Grammatik g4 nach zweiter Ableitung
Entsprechend leitet man die beiden restlichen Worte 'anne' und 'anke' ab. Das Verfahren stoppt an dieser Stelle, da alle Knoten markiert sind. Auserdem wurde keine Fehlermeldung ausgegeben. Also wurden genau die Worte erzeugt, die die Sprache definieren. Damit wäre nun ein Beispiel für eine reguläre Grammatik und der durch sie definierten Sprache gegeben. Im nächsten Beispiel wird gezeigt, wie ein endlicher deterministischer Automat eine solche reguläre Sprache erkennen kann.
Es wird jetzt das Beispiel einer regulären Grammatik g5 im Format einer rechtslinearen Grammatik gegeben, die die gleiche Sprache wie die Grammatik g4 definiert: L(g5,3) = {anne, anke, abzug, ablage}. Trotzdem unterscheidet sich die Grammatik g5 von der Grammatik g4 durch die benutzten Regeln:
FG(g5,3) mit g5 = < <Vg5,Tg5,Sg5 > Pg5>
mit
Vg5 = {S, X1, X2, Y1, Y2, Z1, Z2, G, H, M, V}
Tg5 = {a, b, e, g, k, l, n, u, z}
Pg5 = {(S,aX1),(S,aX2),(X1,bY1),(X1,bY2),(X2,nZ1 ),(X2,nZ2), (Ysub>1,zV),(Y2,lW),(V,uM), (W,aG),(G,gH),(Z1,nG),(Z2,kG),(M,g),(H,e)}
Man sieht, dass durch die Änderung der Produktionsregeln von g5 zusätzliche Alternativen entstehen.
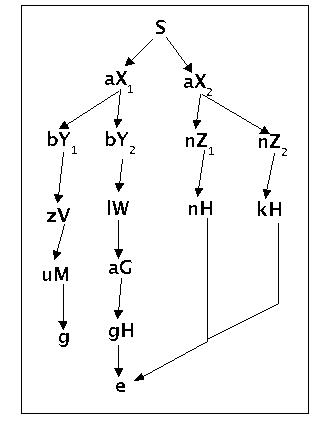
Syntaxbaum zur Grammatik g5
Für die Ableitung (bzw. Erzeugung) von Worten mit der Grammatik g5 gelten die gleichen Regeln wie oben im Fall der Grammatik g4.
Einige Fragen:
Geben Sie die Definition für eine formale Grammatik im allgemeinen Fall an und erklären Sie die verschiedenen Komponenten.
Was bedeutet es, dass ein Ausdruck E' mit einer formalen grammatik G direkt ableitbar ist aus einem Ausdruck E?
Was bedeutet es, dass ein Ausdruck E' mit einer formalen grammatik G ableitbar ist aus einem Ausdruck E?
Wie definiert man die durch eine formale Grammatik G erzeugbare Sprache L(G)?
Unter welchen Bedingungen sind zwei formale Grammatiken G und G' formal äquivalent?
Welche Funktion hat ein Syntaxbaum relativ zu einer formalen Grammatik G?
Was wird durch die Chomsky-Heirarchie definiert?
Wodurch unterscheiden sich die Sprachen, die durch die Chomsky Hierarchie unterschieden werden?
Wie ist das Verhältnis der Sprachen untereinander, die durch die Chomsky Hierarchie unterschieden werden?
Einige Aufgaben:
Gegeben sei das folgendes einfaches Textfragment: "Die Ampel ist rot. Das schwarze Auto stoppt. Peter geht über die Strasse. Es regnet. Die Ampel wird grün. Das Auto startet und verschwindet." Analysieren Sie diesen Text und konstruieren Sie eine formale Grammatik, mit der sich alle Sätze des Textfragmentes ableiten lassen.
Geben Sie Ableitungen für die folgenden drei Sätze an: "Die Ampel ist rot", "Peter geht über die Strasse", "Die Ampel wird grün".
Folgende Sätze sollen mit ihrer Grammatik nicht ableitbar sein: "Das Ampel ist rot", "schwarze Auto stoppt.","Die Auto startet."
Konstruieren Sie einen Syntaxbaum zu ihrer Grammatik.
Geben Sie das Beispiel einer Sprache an, die sich durch eine Typ2-Grammatik beschreiben lässt, nicht aber durch eine Typ3-Grammatik.