|
|
I-TI04 WS 04 - Vorlesung mit Übung
|
Nach der Behandlung der Typ3-Grammatiken (äquivalent zu den regulären Ausdrücken) mit der praktischen Anwendung des Scannergenerators flex sollen in dieser und der nächsten Vorlesung die Typ2-Grammatiken in Kombination mit dem Parsergenerator bison vorgestellt werden. Ähnlich wie im Falle der Typ3-Grammatiken mit der Menge der regukären Ausdrücke gibt es auch im Falle der Typ3-Grammatiken eine pragmatisch motivierte Schreibweise, die sogenannte Backus-Naur Form (BNF), die einer Typ3-Gramatik formal äquivalent ist. Die Backus-Naur Form (BNF) --wie auch ihre Erweiterung, die erweiterte Backus-Naur Form (EBNF)-- eignen sich sehr gut für eine kompakte Darstellung von kontextfreien Grammatiken und werden in den meisten Parsergeneratoren eingesetzt. Die zu den kontextfreien Grammatiken komplementären Automaten sind die Kellerautomaten ("push down automata" (PDAs)).
Zum Verständnis von kontextfreien Grammatiken sowie dem Zusammenspiel von Typ2- und Typ3-Grammatiken am Beispiel des Einsatzes von flex und bison ist es hilfreich, sich nochmals einige Grundbegriffe klar vor Augen zu stellen, die hier einschlägig sind (siehe die folgende Tabelle).
|
THEORIE |
BEISPIEL |
WERKZEUG |
|
|---|---|---|---|
|
Syntaktische Regel |
S-> NP,VP NP->N VP->V |
bison |
|
|
Types |
Syntaktische Kategorien |
NP, VP, S |
bison |
|
Lexikalische Kategorien |
N, V |
flex/bison |
|
|
Token |
Hans, lacht |
flex |
|
Den "harten Boden der Realität" bilden für alle Grammatiken konkrete Zeichenketten, die die theoretischen Linguisten auch Token nennen (z.B.: Hans, lacht). Mehrere Token kann man zu typischen Wortkategorien (auch lexikalisce Kategorien genannt) zusammenfassen (so nennt man die Gruppe der Eigennamen wie etwa Hans oft Nomen, abgekürzt N, und Tätigkeitswörter wie etwa lacht oft Verben, abgekürzt V.)
Lexikalische Kategorien sind also keine Token mehr, sondern abstrakte Wortklassen, von den Linguisten meist Types genannt. Innerhalb der Types unterscheidet man meist zwei wichtige Untermengen: die --schon genannten-- lexikalischen Kategorien und die syntaktischen Kategorien; syntaktische Kategorien sind also die Types ohne die lexikalischen Kategorien. Beispiele für syntaktische Kategorien sind z.B. NP (für Nominal Phrase, Nominalkomplex) und VP (für Verbal Phrase, Verbalkomplex). Letztlich ist die Wahl einer syntaktischen Kategorie eine rein technische Angelegenheit.)
Mittels lexikalischer Kategorien kann man konkrete Token in Types übersetzen. Um Beziehungen zwischen Types zu beschreiben benutzt man dann syntaktische Regeln. Syntaktische Regeln beschreiben, wie man Types in andere Types übersetzen kann und zwar so, dass man das miteinander Auftreten von Token beschreiben kann. Im Beispiel kann man die syntaktische Kategorie S übersetzen in die syntaktischen Kategorien NP VP. NP kann man übersetzen in die lexikalische Kategorie N und VP in die lexikalische Kategorie V. Für N ist festgelegt, dass es für das Token Hans steht und für V ist festgelegt, dass es für das Token lacht steht. Damit hat man festgelegt, dass die beiden Token Hans lacht nebeneinander auftreten koennen. Wuerde man die lexikalischen Kategorien N und V um weitere Elemente erweitern, wuerde damit die Menge der beschreibbaren Tokenvorkommnisse erweitert werden.
Die Regeln lassen sich entweder als Top-Down Regeln schreiben (ausgehend von einem Startsymbol kommt man zu konkreten Token) oder als Bottom-Up Regeln (ausgehend von Token kommt man im positiven Fall zu einem Startsymbol S.
Mit Blick auf die Werkzeuge flex und bison kann man sagen, dass flex geeignet ist, beim Auftreten von Token die zugehörige lexikalische Kategorie zu erkennen und mit bison kann man mit Hilfe von syntaktischen Kategorien und syntaktischen Regeln regelhafte Zusammenhaenge beschreiben.
Betrachten wir ein Beispiel.
Angenommen man will einen Taschenrechner für die Grundrechenarten simulieren. Unter Verwendung der Postfix-Notation wären dann Eingaben wie die folgenden üblich:
4 3 + (= 7)
2 4 * 3 + (= 11)
4 5 + 3 / (= 3)
Die Token dieser Beispiele sind entweder Zahlen '4', '3' usf oder Operationszeichen wie '+', '*' etc. Um diese zu identifizieren benötigt man eine lexikalische Analyse. Z.B. könnte man mit flex festlegen, dass gelten soll:
%{
#include<stdio.h>
%}
NUM [0-9]+
OP [\+\*\-/]
%%
{NUM} printf("NUM ");
{OP} printf("OP\n");
%%
int main(){
yylex();
return(1);
}
gerd@kant:> flex lex-calc.l gerd@kant:> gcc -o lexcalc1 lex.yy.c -lfl gerd@kant:> ./lexcalc1 3 4 + NUM NUM OP 2 4 + 3 * NUM NUM OP NUM OP
Im Rahmen der sogenannten Chomsky-Hierarchie hatten wir die Definition der Typ2-Grammatiken kennengelernt. Typ2-Grammatiken erlauben Ersetzungen ohne Berücksichtigung des Kontextes, allerdings immer nur bezogen auf genau eine syntaktische Variable.
g ist eine formale Grammatik vom Typ 2 [FG(g,2)](Kontextfreie Grammatik, 'Contextfree Grammar' [CFG]) gdw
FG(g) & (A:u,w)( (u,w) ∈ Pg => u ∈ Vg & w ∈ (V ∪ T)* )
Eine kontextfreie Grammatik g wird als proper (eigentlich) bezeichnet, wenn sie keine Regel der Art u --> ε enthält und keine Regel der Art u --> w mit w ausschliesslich in V.
Für verschiedene theoretische Zwecke (spezielle Beweise) wie auch für bestimmte praktische Aufgaben (z.B. spezielle Parsing-Algorithmen) wurden zusätzlich zu dieser allgemeinen Definition von Typ2-Grammtiken unterschiedliche Normalformen entwickelt, in die hinein sich eine formale Grammatik vom Typ2 übersetzen lässt. Einige der wichtigsten Normalformen seien hier aufgelistet (siehe dazu ausführlicher [J-M.AUTEBERT/ J.BERSTEL/ L.BOASSON 1997]):
Schwache Chomsky Normalform [WCNF]: (u,w) ∈ P dann u ∈ V und w ∈ V* oder w ∈ T u {ε}
Chomsky Normalform [CNF]: wenn Schwache Chomsky Normalform und w ∈ V* mit |w| < 2
Satz: Sei FG(g,2), dann kann man eine äquivalente CNF(g) effektiv konstruieren (Beweis [J-M.AUTEBERT/ J.BERSTEL/ L.BOASSON 1997:p.125])
Greibach Normalform [GNF]: (u,w) ∈ P dann u ∈ V und w ∈ TV*. Insbesondere ist eine GNF-Grammatik g auch proper.
Quadratische Greibach Normalform [GNF2]: wenn Greibach Normalform [GNF] und |V*| = 2
Doppelte Greibach Normalform [DGNF]: (u,w) ∈ P dann u ∈ V und w ∈ TV*T oder T
Kubische Doppelte Greibach Normalform [DGNF2]: DGNF(g) & jedes rechte Element einer Regel enthält höchstens 3 Variablen
Satz: Sei g eine CFG(g,2) und proper, dann kann man eine äquivalente GNG(g), GNG2(g), DGNF(g) und DGNF2(g) effektiv konstruieren (Beweis [J-M.AUTEBERT/ J.BERSTEL/ L.BOASSON 1997:p.125ff])
Operator Normalform [ONF]: (u,w) ∈ P dann u ∈ V und w ∈ (V u T)* und w enthält keine zwei aufeinanderfolgenden Variablen (d.h. zwischen zwei Variablen kommt mindestens ein terminales Zeichen vor).
(Diese Sprachen sind besonders geeignet für einfache Shift-Reduce Parser).
Satz: Sei g eine CFG(g,2), dann kann man eine äquivalente ONF(g) effektiv konstruieren (Beweis [J-M.AUTEBERT/ J.BERSTEL/ L.BOASSON 1997:p.133f])
Natürlich kann man Sprachen definieren, die zwischen Typ2 und Typ3 liegen. Beispiele solcher CFG-Unterfamilien sind (vgl. dazu ausführlich [J-M.AUTEBERT/ J.BERSTEL/ L.BOASSON 1997:p.156f]
Lineare sprachen
Quasi-Rationale Sprachen
Starke Quasi-Rationale Sprachen
Finite-Turn Sprachen
One-Counter Sprachen
Iterated-Counter Sprachen
Parenthetische Sprachen
Einfache Sprachen
LL- und LR-Sprachen
Aus praktischer Sicht kommen hier den LL- und insbesondere den LR-Sprachen besondere Bedeutung zu, da diese sich im Bereich Parser und Compiler als besonders geeignet erwiesen haben (siehe dazu weiter unten).
An dieser Stelle ist auch die sogenannte Backus-Naur Form [BNF] bzw. die Extended Backus-Naur-Form [EBNF] zu erwähnen (siehe für eine ausführlichere Übersicht hier; lokale Version) ( mit Link auf eine ausführliche Darstellung von EBNF; lokal ISO-EBNF-Draft).
Die BNF und die EBNF-Notation ist ebenfalls äquivalent zu einer kontextfreien Grammatik. Sie eignet sich insbesondere zur Darstellung von kontextfreien Grammatiken in computerlesbarer Form.
|
BNF |
Position |
Meaning |
|---|---|---|
|
< unquoted words > |
|
non-terminal symbols |
|
unquoted characters |
|
terminal symbols |
|
::= |
infix |
defining |
|
| |
infix |
alternative |
Beispiel mit BNF: Floatkonstante in ALGO60
|
Extended BNF |
Position |
Meaning |
|---|---|---|
|
unquoted words |
|
non-terminal symbols |
|
"..." or '...' |
|
terminal symbols |
|
( ... ) |
|
bracket |
|
[ ... ] |
|
options |
|
{ ... } |
|
repeated zero or more |
|
{ ... }- |
|
repeated one or more |
|
= |
infix |
defining |
|
; |
postfix |
rule terminator |
|
| |
infix |
alternative |
|
, |
infix |
concatenation |
|
- |
infix |
except |
|
n * ... |
infix |
n occurences of ... |
|
(* ... *) |
|
comment |
|
? ... ? |
|
soecial sequence |
Beispiel mit EBNF: Floatkonstante in ALGO60
Beispiel mit EBNF: Floatkonstante in C
Wir führen jetzt aus der Benutzerperspektive den Parsergenerator bison (früher yacc) ein und werden dann im Anschluss die Theorie hinter bison erläutern.
Um syntaktischen Regeln innerhalb von Bison beschreiben zu können, muss man --ähnlich wie bei Flex-- eine spezielle bison-Beschreibungsdatei erstellen. Diese hat als Sufix '.y' statt '.l' wie im Falle von flex.
Der Aufbau einer bison-Beschreibungsdatei ist analog wie die einer flex-Beschreibungsdatei:
%{
PROLOGUE
The PROLOGUE section contains macro definitions and declarations of
functions and variables that are used in the actions in the grammar
rules. These are copied to the beginning of the parser file so that
they precede the definition of `yyparse'. You can use `#include' to
get the declarations from a header file. If you don't need any C
declarations, you may omit the `%{' and `%}' delimiters that bracket
this section.
You may have more than one PROLOGUE section, intermixed with the
BISON DECLARATIONS. This allows you to have C and Bison declarations
that refer to each other.
%}
BISON DECLARATIONS
The BISON DECLARATIONS section contains declarations that define
terminal and nonterminal symbols, specify precedence, and so on. In
some simple grammars you may not need any declarations.
%%
GRAMMAR RULES
The "grammar rules" section contains one or more Bison grammar
rules, and nothing else. *Note Syntax of Grammar Rules: Rules.
There must always be at least one grammar rule, and the first `%%'
(which precedes the grammar rules) may never be omitted even if it is
the first thing in the file).
%%
EPILOGUE
The EPILOGUE is copied verbatim to the end of the parser file, just
as the PROLOGUE is copied to the beginning. This is the most convenient
place to put anything that you want to have in the parser file but
which need not come before the definition of `yyparse'. For example,
the definitions of `yylex' and `yyerror' often go here.
If the last section is empty, you may omit the `%%' that separates it
from the grammar rules.
The Bison parser itself contains many static variables whose names
start with `yy' and many macros whose names start with `YY'. It is a
good idea to avoid using any such names (except those documented in this
manual) in the epilogue of the grammar file.
Comments enclosed in `/* ... */' may appear in any of the sections.
Die Grammatikregeln für einen Taschenrechner mit polnischer Notation ohne die semantische Interpretation:
%% /* Grammar rules and actions follow. */
input: /* empty */
| input line
;
line: '\n'
| exp '\n'
;
exp: NUM
| exp exp '+'
| exp exp '-'
| exp exp '*'
| exp exp '/'
/* Exponentiation */
| exp exp '^'
/* Unary minus */
| exp 'n'
;
%%
Die grammatischen Regeln im Kontext eines vollständigen bison-Programms:
/*-----------------------------------------
* Reverse polish notation calculator.
*
* Example taken from the info-file for 'bison'
*
****************************************/
/*************************************
* bison part
*
**************************************/
%{ /* PROLOGUE */
#define YYSTYPE double
#include <math.h>
#include <stdio.h> /*Neede by following functions */
%}
/* BISON DECLARATIONS */
%token NUM
%% /* Grammar rules and actions follow. */
input: /* empty */
| input line
;
line: '\n'
| exp '\n' { printf ("\t%.10g\n", $1); }
;
exp: NUM { $$ = $1; }
| exp exp '+' { $$ = $1 + $2; }
| exp exp '-' { $$ = $1 - $2; }
| exp exp '*' { $$ = $1 * $2; }
| exp exp '/' { $$ = $1 / $2; }
/* Exponentiation */
| exp exp '^' { $$ = pow ($1, $2); }
/* Unary minus */
| exp 'n' { $$ = -$1; }
;
%%
/* EPILOGUE */
/* The lexical analyzer returns a double floating point
number on the stack and the token NUM, or the numeric code
of the character read if not a number. It skips all blanks
and tabs, and returns 0 for end-of-input. */
#include <ctype.h>
int
yylex (void)
{
int c;
/* Skip white space. */
while ((c = getchar ()) == ' ' || c == '\t')
;
/* Process numbers. */
if (c == '.' || isdigit (c))
{
ungetc (c, stdin);
scanf ("%lf", &yylval);
return NUM;
}
/* Return end-of-input. */
if (c == EOF)
return 0;
/* Return a single char. */
return c;
}
/* A simple main-function -----------------------------------------------*/
int
main (void)
{ /* yydebug nur setzen, wenn benoetigt ! Zugleich '-t' benutzen */
yydebug=1;
return yyparse ();
}
/* A simple error-function -----------------------------------------------*/
void
yyerror (const char *s) /* called by yyparse on error */
{
printf ("%s\n", s);
}
gerd@kant:> bison rpcalc.y
Dies erzeugt die Datei rpcalc.tab.c, die u.a. die Funktion yyparse() definiert.
gerd@kant:> gcc -o rpcalc2 rpcalc.tab.c -lm rpcalc.y:95: warning: type mismatch with previous implicit declaration rpcalc.tab.c:1163: warning: previous implicit declaration of `yyerror' rpcalc.y:95: warning: `yyerror' was previously implicitly declared to return `int'
gerd@kant:> ./rpcalc2 3 4 + bison exp: 7 4 5 + 2 * bison exp: 18 4 5 + 2 * 9 / bison exp: 2
Die beiden folgenden Schaubilder beschreiben die Grundstruktur der Kommunikation zwischen einem Hostprogramm (Wirtsprogramm), das yyparse() aufruft, das wiederum die funktion yylex() ruft. Die funktion yyparse() wird durch bison generiert und yylex() wird entweder direkt kodiert oder durch flex generiert.
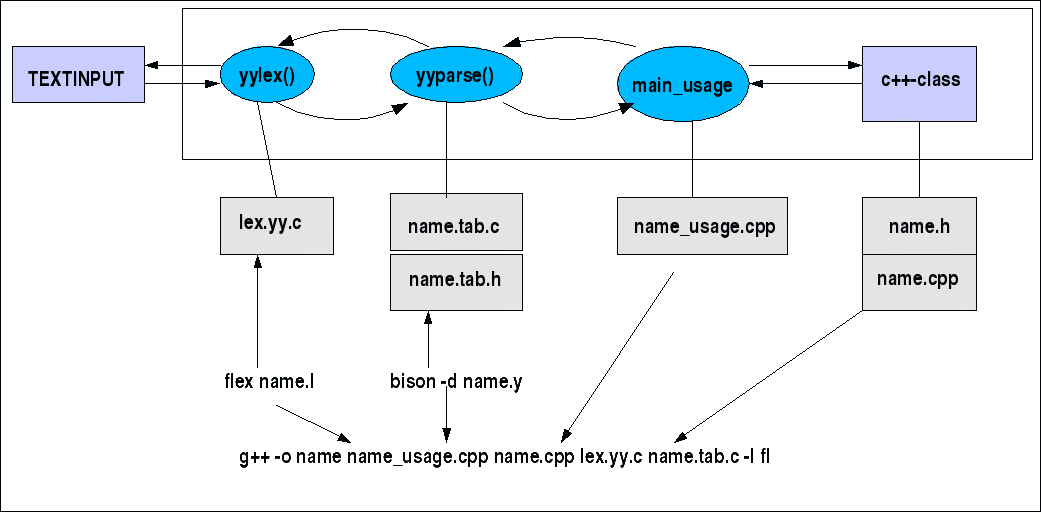
Gesamtbild Dateien
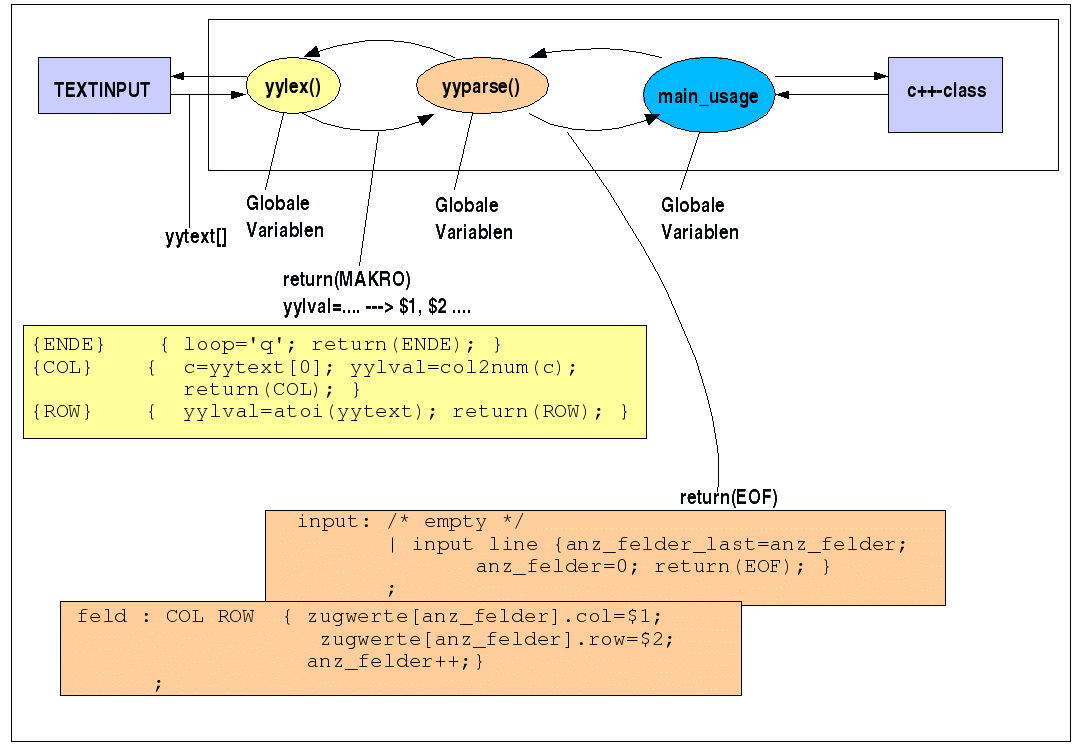
Gesamtbild Kommunikation flex-bison
Ein ausführliches kommentiertes Beispiel zum Zusammenspiel von flex und bison im Rahmen eines C++-Programms mit Einbeziehung eines semantischen Modells findet sich in der Vorlesund 7 der Vorlesung Programmieren 3.
Bezüglich der Strategien, mittels deren man sprachliche Ausdrücke analysieren kann, gibt es die grobe Unterscheidung in Top down oder Bottom up sowie Generell und speziell (siehe Tabelle):
|
|
TOP DOWN |
BOTTOM UP |
|
GENERELL |
Early (Top Down, CFG) |
Polynomial Time Algorithms |
|
SPEZIELL |
LL |
LR |
Mit 'generell' ist gemeint, dass dieser Algorithmus alle kontextfreien Sprachen erkennen kann, mit 'speziell', dass es nur eine Untermenge ist.
Ein Top down Parser analysiert eine Eingabe dadurch, dass er mit dem Startsymbol beginnt und solange Ableitungen erzeugt, bis er eine terminale Kette erzeugt hat, die mit der Eingabe übereinstimmt.
Ein Bottom up Parser analysiert seine Eingabe, indem er ausgehend von den terminalen Zeichen der Eingabe Erzeugungsregeln sucht, mittels deren Teile der Eingabe reduziert werden konnten. Darauf aufbauend werden weitere Erzeugungsregeln gesucht, solange, bis nur noch das Startsymbol übrig bleibt.
Es werden zunächst zwei einfache Beispiele gegeben. Beide Beispiele benutzen die folgende einfache Grammatik:
S ---> AB
A ---> ab | aAb
B ---> c | cB
Bei der Eingabe soll es sich in beiden Fällen um folgenden String handeln: 'aabbccc'
Beispiel eines top-down Parsvorganges:
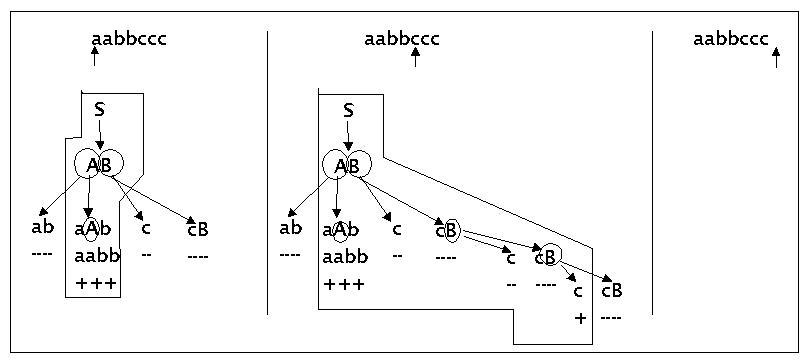
Einfaches paralleles Top-Down Parsing
Dieses einfache Parsingschema kann unterschiedlich optimiert werden, z.B. durch eine effizientere Suchstrategie wie depth-First kombiniert mit Bottom-Up-Filtering (vgl. z.B. das sehr informative Buch von [JURAFSKY/MARTIN 2000:357ff]). Mit Bottom-Up Filtering ist gemeint, dass diejenigen terminalen Worte, die durch die Depth-first-Strategie erkannt wurden, selektiv wirken bzgl. der Auswahl der anzuwenden syntaktischen Regeln; nur solche Regeln sind für die nächste Anwendung zugelassen, deren linker Teil mit den schon erkannten terminalen Worten übereinstimmen. Dennoch gibt es einige grundsätzliche Probleme bei einem einfachen Top-Down Parserer:
Linksrekursivität: Linksrekursive Regeln der Art A = A"b" führen einen Depth-First Links-nach-Rechts Parser in eine endlose Schleife.
Mehrdeutigkeit (Ambiguität): Strukturale Mehrdeutigkeit liegt vor, wenn mehr als eine Fortsetzung möglich ist. Solche kann auf unterschiedliche Weise vorkommen und kann von top-down Parser nur sehr ineffizient behandelt werden.
Backtracking: Das oft erzwungene wiederholte Parsen von Teilbäumen bedingt ein Backtracking im Suchraum, das ebenfalls sehr ineffizient sein kann.
Eine Lösung der zuvor genannten Probleme bietet dynamisches Programmieren. Dabei werden Teillösungen nicht wieder vergessen sondern systematisch in Tabellen so gespeichert, dass die Teilergebnisse für weitere Teilberechnungen zur Verfügung stehen. Ein Algorithmus, der sich dynamisches Progammieren zunutze macht, ist der EARLY-Algorithmus (EARLY 1970). Er hat ein worst-case Laufzeitverhalten von O(N3), wobei N die anzahl der Worte im Input ist.
Für eine Darstellung des EARLY-Algorithmus mit einem Beispiel siehe [JURAFSKY/MARTIN 2000:379ff].
Obwohl der EARLY-Algorithmus vom Zeitverhalten her schon polynom ist, ist er für die Praxis im allgemeinen zu langsam. Es gibt effizientere Algorithmen mit einem linearen Zeitbedarf.
Sogenannte prädiktive Parser kommen ohne Rekursion aus; sie benötigen nur noch lineare Zeit, können dafür allerdings nur eine Untermenge der kontextfreien Sprachen erkennen, nämliche jene, die durch sogenannte LL(1)-Grammatiken definiert werden (prominentes Beispiel einer LL-definierbaren Sprache ist die Sprache Pascal). (LL := Left-to-Right Scan, Leftmost derivation)(nach [GOUGH 1988:167]).
Vorausgesetzt, die Sprache gehorcht einer LL-Grammatik, dann kann ein top-down Parser mit depth-first und bottom-up filtering ohne Backtracking einen Input in einem Durchlauf von Links-nach-Rechts erkennen (siehe z.B. [GOUGH 1988:161ff]).
Beispiel eines bottom-up Parsvorganges:
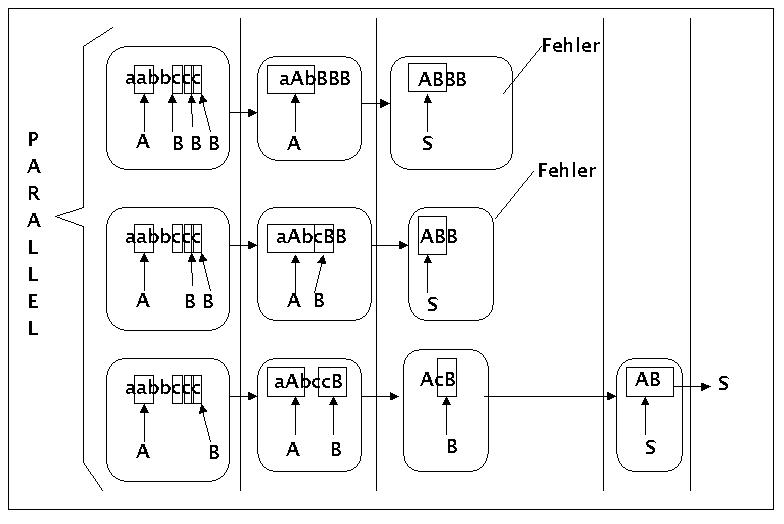
Einfaches paralleles Bottom-up Parsing
Ein allgemeiner Bottom-up Parser ist der Cocke-Younger-Kasami (CYK) Algorithmus. Ähnlich wie der Earley-Algorithmus benutzt er auch dynamische Programmierung. Verwendet man eine binäre Dependenz-Grammatik (DG) für den CYK-Parser in Chomsky Normal Form dann hat ein CYK-Parser ein Laufzeitverhalten von O(N3).
Ähnlich wie im Falle der top-down Parser ist ein Laufzeitverhalten mit O(N3) in der Praxis zu langsam. Es wurden daher auch andere Parsestrategien gesucht. Mit der Erfindung der LR-Parser und LR-Grammatiken durch Knuth 1965 wurde solch eine Lösung gefunden (LR := Left-to-right scan, Rightmost derivation)(nach [GOUGH 1988:167]). LR-Grammatiken sind zwar schwächer als allgemeine CFGs, aber dennoch deutlich stärker als LL-Parser. Im Bereich Parsergeneratoren haben sich die LR-Parser mittlerweile als Standard durchgesetzt. Sie haben nur linearen Zeitbedarf. Konkrete Beispiele für LR(1)-Parser kann man mit dem Parsergenerator yacc ('yet another compiler-compiler') oder durch den verbesserten GNU-Parsergenerator bison erzeugen (siehe auch lex/yacc für Windows)
Obgleich die LR(1)-Grammatiken eine Untermenge der Kontextfreien Grammatiken sind, kann man die meisten in der Praxis auftretenden Fälle von kontextfreien Sprachen mit LR(1)-Parsern bewältigen.
(Vergleiche für das Folgende [Alfred V.AHO/ Ravi SETHI/ Jeffrey D.ULLMAN 1988:pp.237ff]).
Im Kern handelt es sich bei den LR-Parsern auch um Shift-Reduce-Parser, allerdings mit einer Reihe von optimierenden Techniken. Im Folgenden wird die Grundidee von Shift-Reduce-Parsern vorgestellt. Für eine ausführlichere Behandlung der LR-Parser muss auf die weiterführende Literatur verwiesen werden.
Links-Herleitung := das am weitesten links stehende Nichtterminal wird ersetzt
Rechts-Herleitung := das am weitesten rechts stehende Nichtterminal wird ersetzt
Beispiel
Grammatik
E = E "+" E
E = E "*" E
E = "(" E ")"
E = Z
Z = "0" | "1" | ... | "9"
Eine Rechtsableitung
E ==> E "+" E
==> E "+" E "*" E
==> E "+" E "*" Z
==> E "+" E "*" "3"
==> E "+" Z "*" "3"
==> E "+" "2" "*" "3"
==> Z "+" "2" "*" "3"
==> "4" "+" "2" "*" "3"
Wegen Mehrdeutigkeit gibt es auch noch eine andere Rechtsableitung:
E ==> E "*" E
==> E "*" Z
==> E "*" "3"
==> E "+" E "*" "3"
==> E "+" Z "*" "3"
==> E "+" "2" "*" "3"
==> Z "+" "2" "*" "3"
==> "4" "+" "2" "*" "3"
Handle := Substring, der mit der rechten Seite einer Produktion übereinstimmt
handle-Pruning := erwirkt eine Rechtsableitung in umgekehrter Reihenfolge, d.h. ausgehend von einem terminalen Eingabestring werden Handles gesucht, auf die dann eine regel angewendet wird. Die mehrmalige Anwendung einer Regel mit der dazu gehörigen Reduktion kann dann zu einer reversen Rechtsableitung führen.
Beispiel
|
Rechtsabgeleitete Satzform |
Handle |
Regel |
|---|---|---|
|
"4" "+" "2" "*" "3" |
"4" |
Z = "4" |
|
Z "+" "2" "*" "3" |
Z |
E = Z |
|
E "+" "2" "*" "3" |
"2" |
Z = "2" |
|
E "+" Z "*" "3" |
Z |
E = Z |
|
E "+" E "*" "3" |
E "+" E |
E = E "+" E |
|
E "*" "3" |
"3" |
Z = "3" |
|
E "*" Z |
Z |
E = Z |
|
E "*" E |
E "*" E |
E = E "*" E |
|
E |
|
|
Um solch ein Handle-Pruning mittels eines Algorithmus zu bewältigen, müssen im wesentlichen zwei Aufgaben gelöst werden: (i) Suchen eines Teilstrings, auf den sich ein Handle anwenden lässt und (ii) Auswahl der Ersetzungsregel, falls mehr als eine anwendbar ist.
Zur Untersuchung der Frage, wie man diese beiden Aufgaben lösen kann, sei hier ein Beispiel betrachtet, bei dem folgende zwei Datenstrukturen benutzt werden: ein Stack für zu vearbeitende Teilstrings und ein Eingabepuffer. Das Zeichen "§" wird benutzt, um sowohl den Boden des Stacks wie auch das rechte Ende des Eingabepuffers zu markieren.
Der Parser ist so gebaut, dass er so lange Eingabesymbole aus der eingabe in den stack schiebt, bis sich auf diesen eine Ersetzungsregel anwenden lässt. Dies tut er solange, bis das Startsymbol erscheint und die Eingabe leer ist
|
Stack |
Eingabe |
Aktion |
|---|---|---|
|
§ |
"4" "+" "2" "*" "3"§ |
|
|
§"4" |
"+" "2" "*" "3" § |
shift |
|
§Z |
"+" "2" "*" "3"§ |
reduce: Z = "4" |
|
§E |
"+" "2" "*" "3"§ |
reduce: E = Z |
|
§E "+" |
"2" "*" "3"§ |
shift |
|
§E "+" "2" |
"*" "3"§ |
shift |
|
§E "+" Z |
"*" "3"§ |
reduce: Z = "2" |
|
§E "+" E |
"*" "3"§ |
reduce: E = Z |
|
§E |
"*" "3"§ |
reduce: E = E "+" E |
|
§E "*" |
§ |
shift |
|
§E "*" "3" |
§ |
shift |
|
§E "*" "3" |
§ |
reduce: Z = "3" |
|
§E "*" Z |
§ |
reduce: E = Z |
|
§E "*" E |
§ |
reduce: E = Z |
|
§E |
§ |
reduce: E = E "*" E |
|
§E |
§ |
akzeptiere |
An diesem Beispiel kann man erkennen, dass ein Shift-Reduce-Parser letztlich nur vier verschiedene Typen von Aktionen ausführen kann: (1) shift (schieben), (2) reduce (reduzieren), (3) akzeptieren und (4) Fehler erkennen. Dabei ist wichtig, dass der Handle, der eine nächste Ersetzung erlaubt, letztlich immer nur an der Spitze des stacks erscheinen kann.
Es gibt allerdings kontextfreie Grammatiken, die bei einem Shift-Reduce-Parser zu Konflikten führen können:
shift-reduce-Konflikt: Soll geschoben werden oder soll reduziert werden?
reduce-reduce-Konflikt: Es gibt mehr als eine Regel zum Reduzieren?
Versteht man unter LR(n) einen LR-Parser mit n-Symbolen, die vorausgeschaut werden (looahead), dann gilt grundsätzlich, dass mehrdeutige Grammatiken grundsätzlich nicht für LR(n)-Parser geeignet sind. Bis zu einem gewissen Grad kann man aber Mehrdeutigkeiten durch Festlegung von Präferenzen bearbeiten. Aber eben nicht vollständig.
Für eine ausführlichere Behandlung von LR(n)-Parsern siehe [Alfred V.AHO/ Ravi SETHI/ Jeffrey D.ULLMAN 1988:pp.262].
Die bisher aufgeführten Beispiele von Grammatiken stammen vorwiegend aus dem Bereich der klassischen Parsertheorie mit einem Fokus auf Kunstsprachen, wie sie Programmiersprachen darstellen. Begibt man sich --wie es in der Disziplin Computerlinguistik geschieht-- in den Bereich natürlicher Sprachen, hat man eine ganz andere Situation vor sich. Es gibt riesige Corpora von Texten deren Grammatik a priori nicht bekannt ist. Dies bedeutet, dass man aus den empirischen Vorkommnissen von Token die impliziten Zusammenhänge "dependencies") induktiv erschliessen muss. Grammatiken und Parser müssen dem Rechnung tragen. Es verwundert daher nicht, dass die Grammatik- und Parsingtheorie in diesem Anwendungsbereich ganz andere Wege geht. Da in dieser Vorlesung leider keine Zeit verfügbar ist, um diese hochinteressanten Ansätze zu behandeln, sei hier zumindest auf die Seite von Gerold Schneider vom Institut für Computerlinguistik der Universität Zürich verwiesen, der im WS 03 eine Spezialvorlesung in Computerlinguistik gegeben hat, die genau dies zum Gegenstand hatte: Effiziente Analyse unbeschränkter Texte. Dem interessierten Studenten sei eine Lektüre der dort angegebenen Literatur empfohlen.
Neben dem interessanten Gebiet natürlichsprachlicher Texte gibt es ein weiteres spannendes Einsatzgebiet für Parser: Diagrammeditoren mit zugehörigen Diagramm-Parsern! Der starke --und anscheinend unaufhaltsame-- Trend, komplexe Sachverhalte mittels bildhafter Elemente zu repräsentieren und durch Kombination von einfachen Bildelementen zu komplexen Bildern komplexe Sachverhalte zu konstruieren stellt auch die Informatik vor neue Herausforderungen. Zwar ist mittlerweile jedem (Programmierer) das Paradigma des visuellen Programmierens durch das Beispiel von Visual Basic und Visual C++ bekannt, nicht in gleicher Weise gibt es aber auch das Wissen über die dem visuellen Programmieren zugrunde liegende Technik. Letztlich handelt es sich hier auch um Parsertechnologie, wenngleich mit ganz anderer spezifischer Fragestellung als z.B. im Falle von natürlichsprachlichen Texten. Leider können wir auf dieses hochinteressante Gebiet auch nicht weiter eingehen. Der interessierte Student sei aber auf ein exzelentes Beispiel eines Diagramm-Parser Projektes verwiesen, nämlich auf das DiaGen-Projekt von Prof. Mark Minas. Es handelt sich um ein opensource Projekt mit guter Dokumentation.
Einige Fragen:
In welchem Zusammenhang stehen die Begriffe Token, Type, lexikalische Kategorie, syntaktische Kategorie, syntaktische Regel?
Wie unterscheidet sich die Chomsky Normalform und die schwache Chomsky-Normalform von einer normalen kontextfreien Grammatik?
In welchem Verhältnis stehen LL- und LR-Sprachen zu allgemeinen kontextfreien Sprachen?
Worin unterscheidet sich das erweiterte Backus-Naur Format (EBFN) von dem einfachen Backus-Naur Format (BNF)?
Welchem Format müssen die Regeln in einer bison-Spezifikationsdatei genügen?
In der Kombination von flex und bison: welche Aufgabe übernimmt typischerweise das von flex generierte Programm und welche Aufgabe das von bison generierte Programm?
Was versteht man unter Top-Down Parsing am Beispiel von kontextfreien Sprachen?
Welches sind bekannte Probleme, die bei einem nicht optimierten Top-Down Parsing am Beispiel von kontextfreien Sprachen auftreten können?
Was versteht man unter Bottom-Up Parsing am Beispiel von kontextfreien Sprachen?
Wenn Sie unter Voraussetzung einer kontextfreien Grammatik eine Ableitung machen: was würde man (i) unter einer Linksableitung bzw. (ii) unter einer Rechtsableitung verstehen?
Was versteht man unter einem Handle?
Was versteht man unter einem Handle-Pruning?
Aus welchen Komponenten setzt sich ein Shift-Reduce Parser zusammen?
Welche Probleme können beim Shift-Reduce Parsing auftreten?
Was unterscheidet das Parsen von natürlichsprachlichen Texten vom Parsen von formal definierten kontextfreien Sprachen?
Einige Aufgaben:
Gegeben sind die folgenden drei Sätze: (1) "Hans lacht.", (2) "Anna singt.", (3) "Peter erkennt Hans.". (a) Geben Sie die Definition einer kleinen formalen kontextfreie Grammatik, die es erlaubt, diese Sätze abzuleiten. (b) Leiten Sie die drei Sätze aus ihrer Grammatik her. (c) Schreiben Sie die Grammatik so um, dass Sie die schwache Chomsky-Normalform erfüllt. (d) Schreiben Sie die Grammatik so um, dass sie die Chomsky-Normalform erfüllt. (e) Geben Sie Ableitungen der drei Sätze im Rahmen der Chomsky-Normalform an.
Schreiben Sie die kontextfreie Grammatik aus der vorausgehenden Aufgabe sowohl im BNF-Format wie auch im EBNF-Format.
Definieren sie eine kontextfreie Grammatik im EBNF-Format, die die Sprache der Aussagenlogik mit Aussagenvariablen (A, B, ...) , den Operatoren und ("&"), oder ("+"), nicht ("¬") sowie wenn-dann ("==>") definiert. Die Operatoren sollen in Infixschreibeweise geschrieben werden. Einfache runde Klammern "(", ")" sollen zugelassen sein.
Geben Sie anhand der kontextfreien Grammatik für aussagenlogische Ausdrücke ein Beispiel für ein Top-Down Parsing des Ausdrucks (¬AB & (B + C)) ==> D (Unterstrichene Zeichen sollen terminale Zeichen sein).
Geben Sie anhand der kontextfreien Grammatik für aussagenlogische Ausdrücke ein Beispiel für ein Bottom-Up Parsing des Ausdrucks (¬AB & (B + C)) ==> D (Unterstrichene Zeichen sollen terminale Zeichen sein).
Konstruieren Sie einen Shift-Reduce Parser und führen sie die Bottom-Up Analyse des Ausdrucks (¬AB & (B + C)) ==> D (Unterstrichene Zeichen sollen terminale Zeichen sein) mittels dieses Shift-Reduce Parsers durch.