|
|
RECHNERARCHITEKTUR WS 0203 - Vorlesung mit Übung
|
Für die letzten beiden Vorlesungen wurde kein Skript erstellt, da sich die VL auf die Darstellungen von TANENBAUM/GOODMAN stützte. Da das Buch aber zur Zeit schwer greifbar ist, werden hier die wichtigsten Inhalte nochmals zusammengestellt. Diese Zusammenstellung kann aber den mündlichen Vortrag nur verkürzend zusammenfassen.
Der Microkode besteht aus 36-Bit Basiseinheiten, sogenannten Microinstruktionen. Diese Microinstruktionen haben konkrete Adressen im Adressraum von 29 (= 512) Bits. Zur Realisierung eines Assemblerbefehls der IJVM-Assembler-Sprache wird in der Regel eine endliche Folge von solchen Microinstruktionen benötigt. Während die Einsprungadresse in eine solche Sequenz von Microinstruktionen festliegt, können die übrigen Microinstructionen irgendwo im Adressraum liegen. Sie werden dann über die ADR-Bits und das MPC (Microprogrm Program Counter) adressiert.
In der Basisversion ist das Microprogramm als Schleife aufgebaut: die main1-Schleife holt sich immer die aktuelle Sprungadresse aus dem MPC und aktiviert dann einen gewünschten Befehl.
Eine Optimierung besteht darin, diese Schleife schon so in jeden Einzelbefehl zu integrieren, dass jeder Befehl seinen Nachfolger über das MPC bestimmt.
Eine weitere Optimierungsmöglichkeit besteht darin, dass es in vielen Sequenzen von Microbefehlen 'Wartezeiten' gibt, da manche Ergebnisse erst nach bestimmten Verarbeitungsschritten zur Verfügung stehen. Diese Wartezeiten könnte man für Aktivitäten ausnutzen.
Anmerkung: obgleich hier sicher im Detail Optimierungen möglich sind, ist dieses Konzept nur 'halbherzig'; eine konsequentere Umsetzung ergibt sich aus den nachfolgend geschilderten Massnahmen.
Eine weitere Optimierungsmöglichkeit besteht darin, dort zusätzliche Datenpfade einzuführen, wo man dadurch Arbeitsschritte einsparen kann.
Ein hervorstechender Punkt sind jene Zyklen, bei denen der Inhalt eines Registers R1 erst in ein Register R2 transferiert werden muss, damit dann der Inhalt eines Registers R3 zugleich mit R2 durch die ALU verarbeitet werden kann. Ein Beispiel ist hier die Adressierung einer Variablen. Damit das Adressregister MAR über die endgültige Adresse verfügt, muss zunächst die Basisadresse des lokalen Variablenrahmens LV nach H kopiert werden, dann wird über das Byteregister BR der Offset der angezielten Variablen zu H hinzuaddiert, und dann wird der Inhalt von H nach MAR kopiert.
Durch Hinzugügung eines zusätzlichen Datenbusses A-BUS wäre es möglich, den Inhalt des Registers BR und den Inhalt des Registers LV direkt zu addieren und sofort nach MAR zu kopieren (siehe Bild).
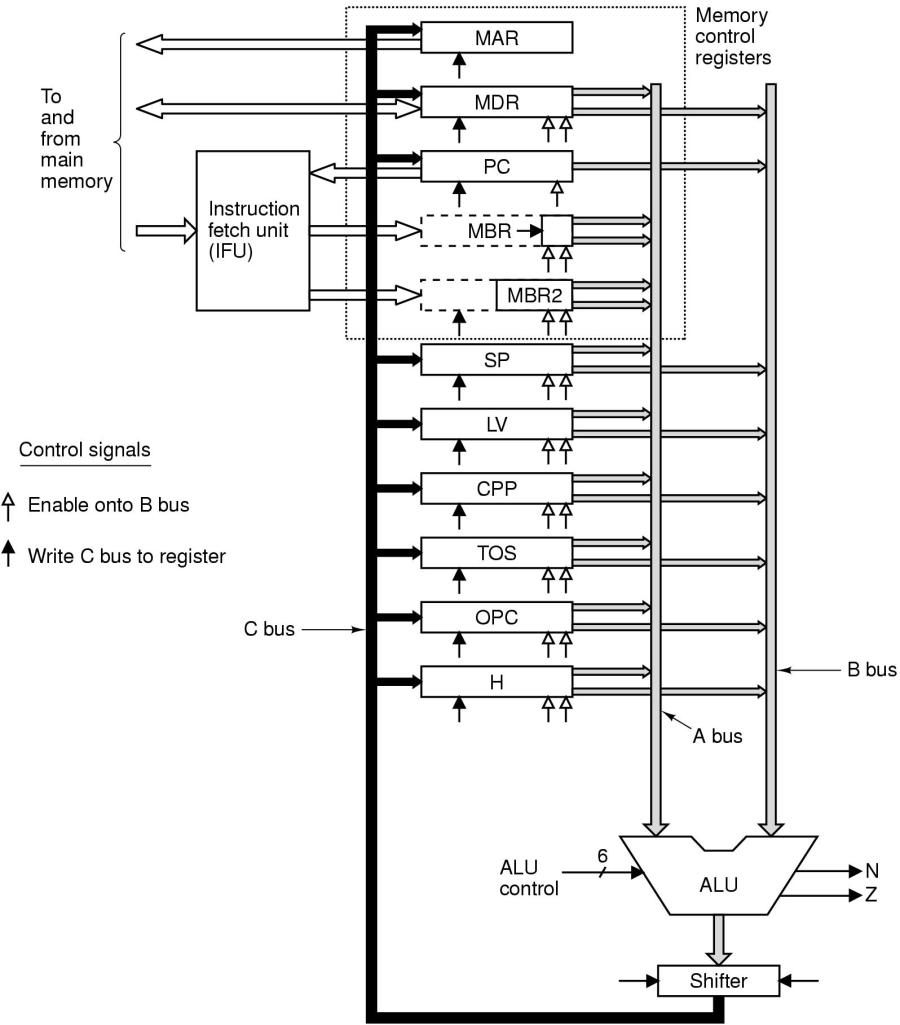
Zusätzlichr A-Bus (und IFU)
Eine weitere Optimierung ergibt sich im Bereich des Auslesens des Opkodes und der Operanten aus dem RAM. Allein das Erhöhen des Program Counters PC, das Holen von Operanten aus dem Speicher, das Schreiben in den Speicher kostet sehr viel Zeit. Eine Abtrennung des Bereitstellens des nächsten OpKodes bzw. der nächsten Operanten (8-Bit oder 16-Bit!) kann die ALU erheblich entlasten und damit die Geschwindigkeit der Abarbeitung deutlich erhöhen.
Zu diesem Zweck wird eine eigene Instruktions-Abruf-Einheit ('Instruction Fetch Unit' [IFU]) eingeführt (siehe Bild).
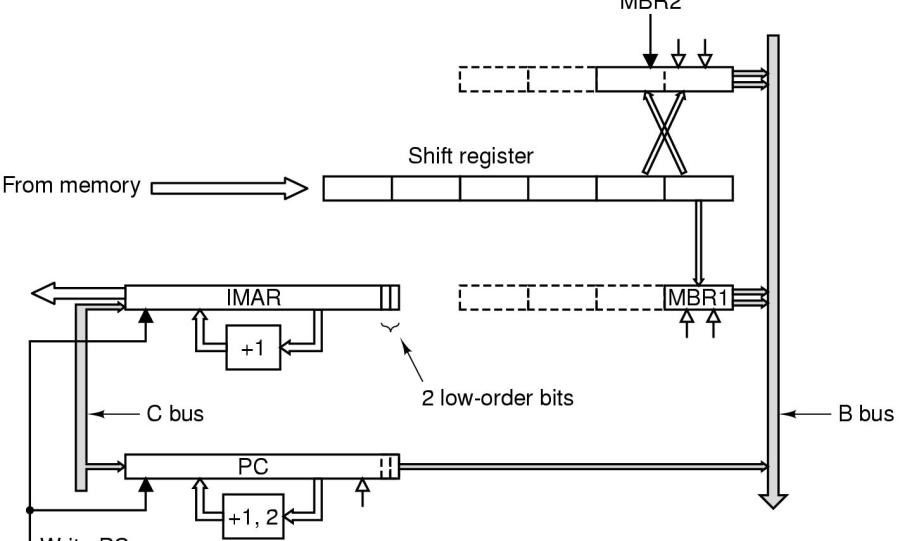
IFU := Instruction Fetch Unit
Die IFU leistet folgende Aufgaben:
Statt nur ein 8-Bit Byteregister MBR1 besitzt die IFU ein zusätzliches 16-Bit-Bytegregistr MBR2. Während MBR1 wie bisher arbeitet, enthält MBR2 die letzten zwei Bytes, um auf diese Weise 16-Bit-Wörter bereithalten zu können.
Sowohl MBR1 wie auch MBR2 beziehen ihren Inhalt aus einem 6-Byte Schieberegister. Dies ist gekoppelt an ein eigenes Adressregister IMAR, das 4-Byte-Wörter einliest, sobald das Schiebereguster nur noch 2 Bytes enthält. Aufgrund der sequentiellen Anordnung des binären Programms ist dies kein Problem. Das IMAR hat seinen eigenen einfachen aufwärtszähler und fällt damit der ALU nich zur Last.
Auch der Program Counter PC kann jetzt dadurch 'automatisiert' werden, dass er sich selbst jeweils dann inkrementiert, wenn MBR1 (+1) bzw. MBR2 (+2) gelesen wurden.
Die gesamte IFU wird meistens als Endlicher Automat ('Finite State Machine' [FSM]) konzipiert.
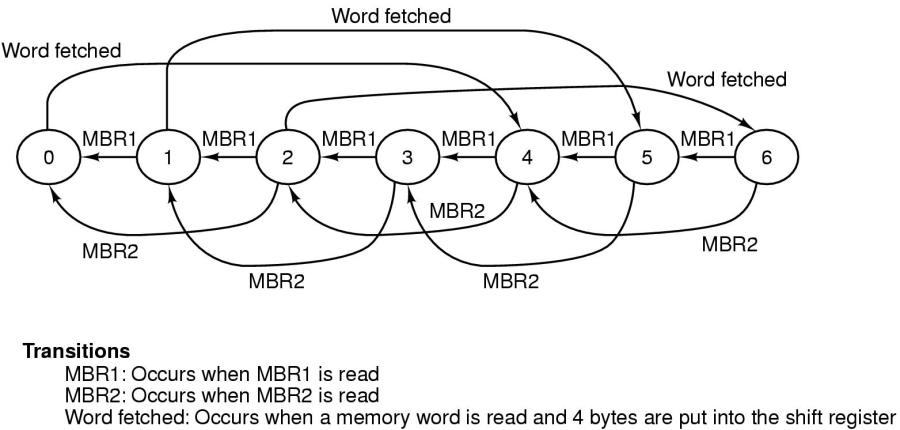
IFU als FSM
Der nächste Optimierungsvorschlag wirkt zunächst wie ein Rückschritt: in jeden Datenbus wird ein Register eingebaut, das je nach Bus A-, B- bzw. C-Register heisst. Dies bedeutet, Daten, die zur ALU wandern, werden erst im A- bzw. im B-Register gespeichert. Daten, die von der ALU in eines der Register am C-Bus gespeichert werden sollen, werden zunächst im C-Register zwischengespeichert (siehe Bild).
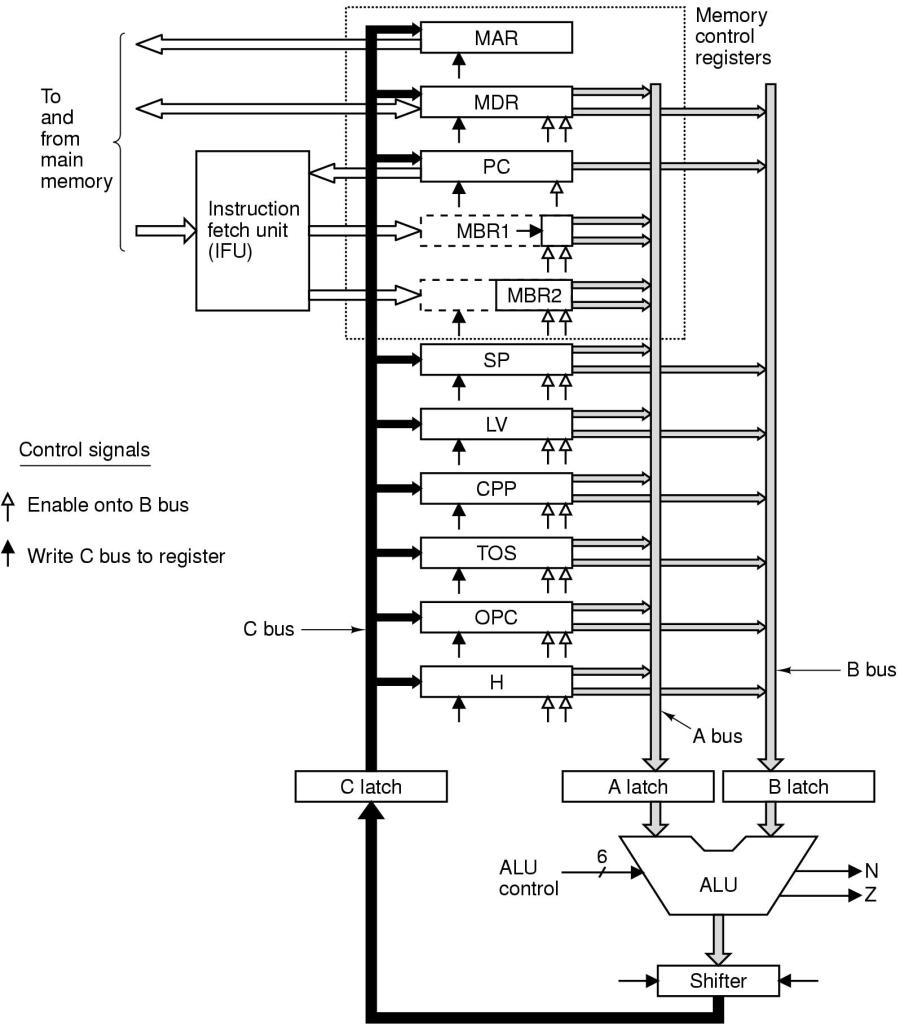
Datenregister in den Daten-Bussen
Was auf den ersten Blick wie eine 'Verlangsamng' der Prozesse aussieht, erweist sich im Zusammenhang tatsächlich als Optimierung. Das Schlüsselwort hier heisst 'Parallelisierung' (siehe nächsten Abschnitt).
Durch die Zwischenschaltung der A-, B- und C-Register tritt für viele Prozesse eine Art Entkoppelung ein.So ist der Transfer von Daten von einem Register zum A- oder B-Bus unabhängignvon der Aktivität der ALU; ebenso ist die Aktivität der ALU unabhänig von der Aktivität des Kopierens vom C-Register in die angeschlossenen Register. Durch diese partielle Entkoppelung wird eine bedingte Parallelisierung möglich.
TANENBAUM/GOODMAN führen für diese neuen Operationen (REGISTER ---> A-/B-Register, A-/B-Register ---> ALU, ALU ---> C-Register, C-Register ---> Register) den Begriff Microschritt ('Microstep') ein.
Wie sich diese neue Parallelisierung auswirken kann, zeigt am Besten das Beispiel des Befehls SWAP in der folgenden Tabelle.
|
|
Swap1 |
Swap2 |
Swap3 |
Swap4 |
Swap5 |
Swap6 |
|
1 |
MAR=SP-1; rd |
MAR=SP |
H=MDR; wr |
MDR=TOS |
MAR=SP-1; wr |
TOS=H; goto(MBR1) |
Inhaltlich vertauscht der Befehl SWAP die beiden obersten Bytes im Stapel ('Stack'). Angenommen SP = A und SP-1 = B. Im Zyklus Swap1 übernimmt MAR die Aresse des SP-1 (=B) und liest das vorletzte Byte im Stapel (MDR = B). Dann wird MAR wieder auf SP gesetzt. H übernimmt MDR (=B) und schreibt den Inhalt von MDR nach MAR = SP. Dann wird der Inhalt von TOS (der noch den Inhalt des obersten Stapelelementes (=A) enthält), nach MDR kopiert, MAR wird auf SP-1 gesetzt und der Inhalt von MDR wird nach SP-1 geschrieben (=A). Dann übernimtm TOS den Wert von H (=B), da dies dem neuen obersten Element des Stapels entspricht. Dann wird zur nächsten Instruktion gesprungen.
Dies war die Beschreibung ohne Parallelisierung. MIT Parallelisierung ergeben sich neue Möglichkeiten. In der nachfolgenden Tabelle wird (i) der alte Microkode in die neuen Microsteps zerlegt (vertikal). Dann (ii) wird geschaut, inwieweit sich die Microsteps des nächsten alten Microkodes mit den Microsteps des vorherigen Microkodes parallelisieren lassen.
|
|
Swap1 |
Swap2 |
Swap3 |
Swap4 |
Swap5 |
Swap6 |
|
1 |
MAR=SP-1; rd |
MAR=SP |
H=MDR; wr |
MDR=TOS |
MAR=SP-1; wr |
TOS=H; goto(MBR1) |
|
1 |
B=SP |
|
|
|
|
|
Zunächst muss der Inhalt von SP zum B-Register gebracht werden.
|
|
Swap1 |
Swap2 |
Swap3 |
Swap4 |
Swap5 |
Swap6 |
|
1 |
MAR=SP-1; rd |
MAR=SP |
H=MDR; wr |
MDR=TOS |
MAR=SP-1; wr |
TOS=H; goto(MBR1) |
|
1 |
B=SP |
|
|
|
|
|
|
2 |
C=B-1 |
B=SP |
|
|
|
|
Hier wird eine erste Parallelisierung sichtbar: nachdem das B-Register seinen Wert an die ALU abgegeben hat, kann es einen neuen Wert speichern, während das C-Register einen Wert von der ALU übernimmt.
|
|
Swap1 |
Swap2 |
Swap3 |
Swap4 |
Swap5 |
Swap6 |
|
1 |
MAR=SP-1; rd |
MAR=SP |
H=MDR; wr |
MDR=TOS |
MAR=SP-1; wr |
TOS=H; goto(MBR1) |
|
1 |
B=SP |
|
|
|
|
|
|
2 |
C=B-1 |
B=SP |
|
|
|
|
|
3 |
MAR=C; rd |
C=B |
|
|
|
|
Wiederum sind zwei Vorgäge parallel möglich: während das Adressregister den Wert von C übernimmt, kann C neue werte von der ALU übernehmen.
|
|
Swap1 |
Swap2 |
Swap3 |
Swap4 |
Swap5 |
Swap6 |
|
1 |
MAR=SP-1; rd |
MAR=SP |
H=MDR; wr |
MDR=TOS |
MAR=SP-1; wr |
TOS=H; goto(MBR1) |
|
1 |
B=SP |
|
|
|
|
|
|
2 |
C=B-1 |
B=SP |
|
|
|
|
|
3 |
MAR=C; rd |
C=B |
|
|
|
|
|
4 |
MDR=mem |
MAR=C |
|
|
|
|
Während das Datenregister MDR einen Speicherwert übernimmt kann parallel MAR den Wert von C übernehmen.
|
|
Swap1 |
Swap2 |
Swap3 |
Swap4 |
Swap5 |
Swap6 |
|
1 |
MAR=SP-1; rd |
MAR=SP |
H=MDR; wr |
MDR=TOS |
MAR=SP-1; wr |
TOS=H; goto(MBR1) |
|
1 |
B=SP |
|
|
|
|
|
|
2 |
C=B-1 |
B=SP |
|
|
|
|
|
3 |
MAR=C; rd |
C=B |
|
|
|
|
|
4 |
MDR=mem |
MAR=C |
|
|
|
|
|
5 |
|
|
B=MDR |
|
|
|
Nachdem der Wert in MDR zur Verfügung steht, kann B den Wert übernehmen.
|
|
Swap1 |
Swap2 |
Swap3 |
Swap4 |
Swap5 |
Swap6 |
|
1 |
MAR=SP-1; rd |
MAR=SP |
H=MDR; wr |
MDR=TOS |
MAR=SP-1; wr |
TOS=H; goto(MBR1) |
|
1 |
B=SP |
|
|
|
|
|
|
2 |
C=B-1 |
B=SP |
|
|
|
|
|
3 |
MAR=C; rd |
C=B |
|
|
|
|
|
4 |
MDR=mem |
MAR=C |
|
|
|
|
|
5 |
|
|
B=MDR |
|
|
|
|
6 |
|
|
C=B (über ALU) |
B=TOS |
|
|
Während C den Wert von B über die ALU übernimmt, kann B den Wert von TOS einlesen..
|
|
Swap1 |
Swap2 |
Swap3 |
Swap4 |
Swap5 |
Swap6 |
|
1 |
MAR=SP-1; rd |
MAR=SP |
H=MDR; wr |
MDR=TOS |
MAR=SP-1; wr |
TOS=H; goto(MBR1) |
|
1 |
B=SP |
|
|
|
|
|
|
2 |
C=B-1 |
B=SP |
|
|
|
|
|
3 |
MAR=C; rd |
C=B |
|
|
|
|
|
4 |
MDR=mem |
MAR=C |
|
|
|
|
|
5 |
|
|
B=MDR |
|
|
|
|
6 |
|
|
C=B (über ALU) |
B=TOS |
|
|
|
7 |
|
|
H=C; wr |
C=B |
B=SP |
|
Während H den Wert von C übernimmt und der Inhalt von MDR in den Speicher geschrieben wird übernimmt C den Wert von B über die ALU und B übernimmt den Wert von SP.
|
|
Swap1 |
Swap2 |
Swap3 |
Swap4 |
Swap5 |
Swap6 |
|
1 |
MAR=SP-1; rd |
MAR=SP |
H=MDR; wr |
MDR=TOS |
MAR=SP-1; wr |
TOS=H; goto(MBR1) |
|
1 |
B=SP |
|
|
|
|
|
|
2 |
C=B-1 |
B=SP |
|
|
|
|
|
3 |
MAR=C; rd |
C=B |
|
|
|
|
|
4 |
MDR=mem |
MAR=C |
|
|
|
|
|
5 |
|
|
B=MDR |
|
|
|
|
6 |
|
|
C=B (über ALU) |
B=TOS |
|
|
|
7 |
|
|
H=C; wr |
C=B |
B=SP |
|
|
8 |
|
|
mem=MDR |
MDR=C |
C=B-1 |
B=H |
Der Speicher empfängt Werte von MDR, parallel bekommt MDR den Wert von C, C über die ALU den Wert von B-1 und B den Wert von H.
|
|
Swap1 |
Swap2 |
Swap3 |
Swap4 |
Swap5 |
Swap6 |
|
1 |
MAR=SP-1; rd |
MAR=SP |
H=MDR; wr |
MDR=TOS |
MAR=SP-1; wr |
TOS=H; goto(MBR1) |
|
1 |
B=SP |
|
|
|
|
|
|
2 |
C=B-1 |
B=SP |
|
|
|
|
|
3 |
MAR=C; rd |
C=B |
|
|
|
|
|
4 |
MDR=mem |
MAR=C |
|
|
|
|
|
5 |
|
|
B=MDR |
|
|
|
|
6 |
|
|
C=B (über ALU) |
B=TOS |
|
|
|
7 |
|
|
H=C; wr |
C=B |
B=SP |
|
|
8 |
|
|
mem=MDR |
MDR=C |
C=B-1 |
B=H |
|
9 |
|
|
|
|
MAR=C; wr |
C=B |
Das Adressregister MAR übernimmt C und das MDR wird ins Memory geschrieben; Göeichzeitig übernimmt C über die ALU den Wert von B.
|
|
Swap1 |
Swap2 |
Swap3 |
Swap4 |
Swap5 |
Swap6 |
|
1 |
MAR=SP-1; rd |
MAR=SP |
H=MDR; wr |
MDR=TOS |
MAR=SP-1; wr |
TOS=H; goto(MBR1) |
|
1 |
B=SP |
|
|
|
|
|
|
2 |
C=B-1 |
B=SP |
|
|
|
|
|
3 |
MAR=C; rd |
C=B |
|
|
|
|
|
4 |
MDR=mem |
MAR=C |
|
|
|
|
|
5 |
|
|
B=MDR |
|
|
|
|
6 |
|
|
C=B (über ALU) |
B=TOS |
|
|
|
7 |
|
|
H=C; wr |
C=B |
B=SP |
|
|
8 |
|
|
mem=MDR |
MDR=C |
C=B-1 |
B=H |
|
9 |
|
|
|
|
MAR=C; wr |
C=B |
|
10 |
|
|
|
|
mem=MDR |
TOS=C |
Der Speicher bekommt den Wert von MDR und TOS übernimmt den Wert von C.
|
|
Swap1 |
Swap2 |
Swap3 |
Swap4 |
Swap5 |
Swap6 |
|
1 |
MAR=SP-1; rd |
MAR=SP |
H=MDR; wr |
MDR=TOS |
MAR=SP-1; wr |
TOS=H; goto(MBR1) |
|
1 |
B=SP |
|
|
|
|
|
|
2 |
C=B-1 |
B=SP |
|
|
|
|
|
3 |
MAR=C; rd |
C=B |
|
|
|
|
|
4 |
MDR=mem |
MAR=C |
|
|
|
|
|
5 |
|
|
B=MDR |
|
|
|
|
6 |
|
|
C=B (über ALU) |
B=TOS |
|
|
|
7 |
|
|
H=C; wr |
C=B |
B=SP |
|
|
8 |
|
|
mem=MDR |
MDR=C |
C=B-1 |
B=H |
|
9 |
|
|
|
|
MAR=C; wr |
C=B |
|
10 |
|
|
|
|
mem=MDR |
TOS=C |
|
11 |
|
|
|
|
|
goto(MBR1) |
Mit dem Sprung in die Adresse von MBR1 endet der Befehl. Nimmt man mit TANENBAUM an, dass ein Microbefehl Swap1-Swap6 jeweils 3 Zeit-Units benötigen, ein Microstep aber nur jeweils 1 Zeit-Unit, dann würde Swap1-Swap6 3 x 6 = 18 Zeit-Units benötigen und die Microstep-Version nur 11 x 1 Unit = 11 Units. Dies wäre eine Optimierung um 39% bzgl. des Zeitverbrauches.
In den Übungen