|
|
I-PROGR3 WS03 - PROGRAMMIEREN3 - Vorlesung mit Übung
|
Die Grundidee des Parsens eines Textes besteht darin, den Elementen eines Textes eine Beschreibung zuzuordnen. Diese kann entweder 'einfach' sein, indem nur aufeinanderfolgende 'Token' identifiziert werden --man spricht dann von lexikalischer Analyse--, oder komplex, indem zusätzlich zu den Token auch noch bestimmte Kombinationen von Token als spezielle Konstrukte klassifiziert werden --man spricht dann von syntaktischer Analyse--. Weitere Analyseebenen sind möglich, z.B. eine semantische Analyse, wenn die Kombination von Token 'für etwas anderes' stehen, d.h. 'Bedeutung' besitzen bzw. wenn die Kombination von Token grössere Einheiten bilden, die je nach Sprecher und Situation unterschiedliche Bedeutung gewinnen; in diesem Fall spricht man von einer pragmatischen Analyse'. Im Falle natürlicher Sprachen treten alle vier genannten Analyserücksichten auf; eventuell noch weitere. Im Falle von Programmiersprachen, die zu den formalen Sprachen gehören, treten in der Regel nur lexikalische und syntaktische Analyse auf; in speziellen Fällen auch einfache semantische Sachverhalte. In der heutigen Vorlesung steht die lexikalische Analyse im Zentrum.
In der lexikalischen Analyse geht man davon aus, dass sich die Folge von Buchstaben, die einen Text konstituieren, sich einer endlichen Menge von Wörtern, auch Token genannt, zuordnen lässt. Diese Token können in beliebiger Reihenfolge auftreten. Die Aufgabe der lexikalischen Analyse besteht dann darin, das Auftreten dieser Token zu erkennen. Im einfachsten Fall besitzt man von vornherein eine endliche Liste dieser Token und vergleicht dann die Buchstaben eines Textes --von links nach rechts bzw. vom Anfang bis zum Ende-- daraufhin, welche Sequenzen von Buchstaben welches der vorausgesetzten Token entspricht. Schlägt die Zuordnung fehl, liegt ein Fehler vor. Andernfalls wird ein Token erkannt.
Angenommen, die folgende Liste von Token ist vorgegeben:
nord
ost
sued
west
und dazu der folgende Text:
westnordnordsuedostsuedwestsuednordostnordostostwest
Eine korrekte lexikalische Analyse müsste dann jedes vorgegebene Token in dieser Zeichenkette erkennen. Andernfalls müsste eine Fehlermeldung erscheinen.
Es gibt jetzt viele Wege, einen lexikalischen Parser als Teil eines grösseren Parserobjektes zu realisieren. Der eine wäre eine direkte Realisierung in C oder C++. Ein anderer besteht darin, von dem Werkzeug flex Gebrauch zu machen. flex ist ein Parsergenerator. Anstatt für jede Aufgabe einen eigenen Parser zu schreiben, übergibt man an flex nur die Beschreibung der zu erkennenden Token, und flex generiert dann daraus automatisch einen lexikalischen Parser, der diese Aufgabe erfüllt.
Für eine detaillierte Beschreibung von flex kann man den Befehl 'info flex' auf der Shell-Kommandozeile eingeben. Für weitere Informationen kann man auch das sehr ausführliche Buch [HEROLD 1992] konsultieren, da flex auf lex aufbaut und bison auf yacc (:= 'yet another compiler compiler').
Hier ist nur wichtig zu wissen, dass flex eine Beschreibungsdatei mit dem Suffix '.l' voraussetzt, in der die Art der Token beschrieben werden, die erkannt werden sollen. Mit Hilfe solch einer Beschreibungsdatei wird dann festgelegt, welche Token ein durch flex generierter lexikalischer Analysator --oft auch Scanner genannt-- erkennen soll. Aus dieser Beschreibung wird dann mit dem Scanner-Generator flex eine C-Datei erzeugt, die schliesslich in einen lexikalischen Analysator (Scanner) umgewandelt werden kann (siehe Schaubild).
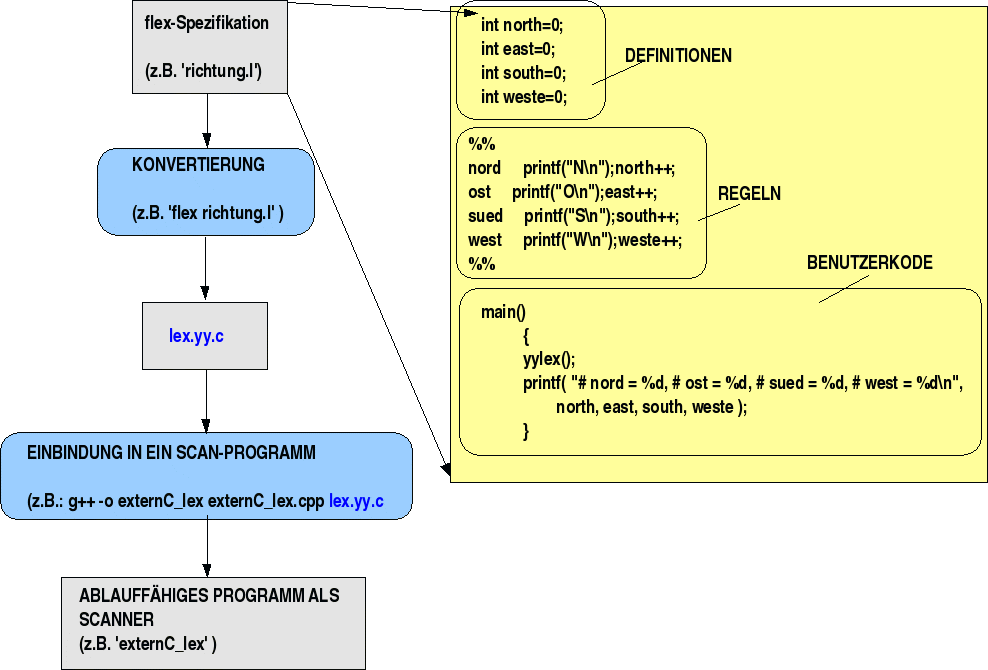
Erzeugung eines Scanners aus einer flex-Datei
Eine flex-Datei kann aus drei Abschnitten bestehen (s.u.): Definitionen, Regeln und Benutzer Code. In den Definitionen können Variablen deklariert werden, die dann im aufrufenden C-Programm benutzt werden können. Jede Regel besteht aus einem Paar PATTERN ACTION, wobei PATTERN ein regulärer Ausdruck ist und ACTION einen C-Befehl darstellt, d.h. im PATTERN wird ein mögliches Token-Ereignis beschrieben und in dem ACTION-Teil wird die gewünschte Reaktion auf dieses Ereignis festgelegt. Eine Regel hat dann also die Struktur 'if PATTERN then ACTION' oder 'Wenn PATTERN, dann ACTION'. Im Benutzerkode kann man beliebige C-Funktionen definieren, auch natürlich eine main-Routine. Liegt eine flex-Spezifikationsdatei --auch flex-Programm genannt-- mit dem suffix '.l' vor, dann generiert flex eine C-Datei `lex.yy.c', die intern eine Routine `yylex()' definiert. Die Datei lex.yy.c kann dann in einen ausführbaren Objektkode umgewnadelt werden.
Ein einfaches Beispiel. Eine lex-Spezifikation für das Programm 'richtung.l'. Im Definitionsteil werden vier Variablen eingeführt, die zum Zählen von Ereignissen benutzt werden sollen (Achtung: diese Deklarationen dürfen nicht in der ersten Spalte beginnen!). Im Regelteil wird jedem Richtungswort eine Aktion zugeordnet (Ausgabe auf den Bildschirm und zählen)(Achtung: diese PATTERN müssen in der ersten Spalte beginnen!). Im benutzerspezifischen Teil wird eine main-Routine beschrieben, die nach Beendigung von yylex() die Anzahl der gezählten Ereignisse ausgibt.
int north=0;
int east=0;
int south=0;
int weste=0;
%%
nord printf("N\n");north++;
ost printf("O\n");east++;
sued printf("S\n");south++;
west printf("W\n");weste++;
%%
main()
{
yylex();
printf( "# nord = %d, # ost = %d, # sued = %d, # west = %d\n",
north, east, south, weste );
}
Ein Übungstext mit Namen 'commands1.txt' sieht wie folgt aus:
gerd@kant:~/public_html/fh/I-PROGR3/I-PROGR3-TH/VL3> cat commands1.txt nordnordsuednordwestnordnordostsuednord
Die Kompilierung des flex-Programmes 'richtung.l' geschieht wie folgt:
gerd@kant:~/public_html/fh/I-PROGR3/I-PROGR3-TH/VL3> flex richtung.l
Damit wird die Datei 'lex.yy.c' erzeugt. Diese Funktion kann nun als Funktion in einem anderen Programm aufgerufen werden, z.B. in einer eigenen main-Routine. In diesem Fall ist die Kompilierung recht einfach:
gerd@kant:~/public_html/fh/I-PROGR3/I-PROGR3-TH/VL3> gcc -o richtung lex.yy.c -lfl
(die Bibliothek '-lfl' wird nur benötigt, wenn keine eigene main-Routine ausserhalb der Datei 'lex.yy.c' existiert.)
Damit steht einer Anwendung dann nichts mehr im Wege:
gerd@kant:~/public_html/fh/I-PROGR3/I-PROGR3-TH/VL3> ./richtung < commands1.txt N N S N W N N O S N # nord = 6, # ost = 1, # sued = 2, # west = 1
Wie das nachfolgende Beispiel zeigt, kann man den C-Kode des Flex-Scanners auch unter C++ einbinden.
/************************ * * richtung4.l * **************************/ #include%% nord { printf("N\n"); } ost { printf("O\n"); } sued { printf("S\n"); } west { printf("W\n"); } %% /************************* * Dummy ******************************/ int yywrap(void){ ; }
//-----------------------
//
// externC_lex.cpp
//
//-------------------------
//
// COMPILATION:
//
// fh/I-PROGR3/I-PROGR3-TH/VL3> flex richtung4.l
// ==> lex.yy.c
// fh/I-PROGR3/I-PROGR3-TH/VL3> g++ -o externC_lex externC_lex.cpp lex.yy.c
// ==> externC_lex
//---------------------------
//
// USAGE: ./externC_lex
//
//-----------------------------------
#include <stdio.h>
int main(void){
extern int yylex(void);
printf("Funktion yylex() wird gerufen !!!\n");
yylex();
return(1);
}
gerd@kant:~/public_html/fh/I-PROGR3/I-PROGR3-TH/VL3> flex richtung4.l gerd@kant:~/public_html/fh/I-PROGR3/I-PROGR3-TH/VL3> g++ -o externC_lex externC_lex.cpp lex.yy.c gerd@kant:~/public_html/fh/I-PROGR3/I-PROGR3-TH/VL3> ./externC_lex Funktion yylex() wird gerufen !!! nordwest rrr westsuedsued nor N W rrr W S S nor
Die obigen Beispiele benutzen für die PATTERN individuelle Wort-Token als ganze Einheiten. Dies ist zwar möglich, bleibt aber hinter den Möglichkeiten von flex weit zurück, denn flex kann als PATTERN auch sogenannte reguläe Ausdrücke verarbeiten. Für die Details zu regulären Ausdrücken sei einerseits verwiesen auf die parallele Vorlesung Theoretische Informatik sowie auf das ausgezeichnete Online-Skript von [Richter 2002]. Hier wird nur der Grundgedanke von regulären Ausdrücken vorgestellt werden und wie man diese im Rahmen von flex nutzen kann.
Die Grundidee von regulären Sprachen besteht darin, dass es sich bei den regulären Sprachen um solche Ausdrucksmengen handelt, deren Aufbau sich durch besonders einfache Regeln beschreiben lassen. Im Rahmen der Theorie der formalen Sprachen nehmen die regulären Sprachen in der Chomsky-Hierarchie die unterste Stufe ein, d.h. sie umfassen solche Ausdrücke, die im Sinne dieser Hierarchie am einfachsten zu erkennen sind. Nachfolgend einige der Regeln, durch die jene reguläre Ausdrücke beschrieben werden, die als PATTERN im Rahmen von flex benutzt werden dürfen:
|
REGULÄRER AUSDRUCK |
BEDEUTUNG |
|---|---|
|
x |
bezeichnet den Buchstaben 'x' |
|
. (Punkt) |
steht für jedes beliebiges Zeichen, ausgenommen '\n' |
|
[xyz] |
Die eckigen Klammern deuten eine Zeichenklasse an; im Beispiel steht dieses Pattern entweder für ein 'x', ein 'y', oder ein 'z' |
|
[abj-oZ] |
Dies ist eine Zeichenklasse mit einem Bereich, angezeigt durch das Minus-Zeichen '-'; im Beispiel steht dieses Pattern entweder für ein 'a', ein 'b', für jeden Buchstaben aus dem Bereich 'j-o', oder ein 'Z' |
|
[^A-Z] |
Dies ist eine negierte Zeichenklasse, d.h. es werden alle zeichen (aus dem ASCII-Alphabet) dargestellt ausser denen, die im Pattern genannt werden, also alle Zeichen von A bis Z werden NICHT erkannt. |
|
r* |
Kein oder mehrere r's, wobei r ein regulärer Ausdruck ist. |
|
r+ |
ein oder mehrere r's, wobei r ein regulärer Ausdruck ist. |
|
r? |
kein oder ein r, wobei r ein regulärer Ausdruck ist. |
|
r{2,5} |
2 bis 5 r's, wobei r ein regulärer Ausdruck ist. |
|
r{2, } |
2 oder mehr r's, wobei r ein regulärer Ausdruck ist. |
|
r{4} |
genau 4 r's, wobei r ein regulärer Ausdruck ist. |
|
\0 |
ASCII Kode 0 |
|
\123 |
Das Zeichen mit dem oktalen Wert 123 |
|
\x2a |
Das Zeichen mit dem hexadezimalen Wert 2a |
|
rs |
Der reguläre Ausdruck r gefolgt von dem regulären Ausdruck s |
|
r|s |
Der reguläre Ausdruck r oder der reguläre Ausdruck s |
|
r/s |
Der reguläre Ausdruck r, aber nur, wenn er von s |
Ein Beispiel für reguläre Sprachen wären die Zugangaben bei dem Damespiel, das in der letzten Vorlesung eingeführt worden ist. Dort war vereinbart worden, dass der Zug eines Steines von einem Startfeld zu einem Zielfeld --eventuell über mehrere Zwischenstationen beim Überspringen gegenerischer Steine-- wie folgt geschrieben werden soll:
STARTFELD:ZIELFELD[,ZIELFELD]*Diese Schreibweise kommt einem regulären Ausdruck schon sehr nahe. Eine ausführliche Darstellung eines Spielzuges in einem Damespiel könnte wie folgt aussehen:
[a-h][1-8]:[a-h][1-8](,[a-h][1-8])*Dies bedeutet: Erst ein Zeichen aus [a-h], dann ein Zeichen aus [1-8], dann das Zeichen ':' selbst, dann wieder ein Zeichen aus [a-h] gefolgt von einem Zeichen aus [1-8]. Optional können dann keinmal, einmal oder mehrmals folgen ein Komma ',', ein Zeichen aus [a-h] gefolgt von einem Zeichen aus [1-8]. Damit wären alle Zugeingaben des Damespiels erfasst. Schauen wir uns dies im Beispiel an.
Als erstes wird eine flex-Datei angegeben, die solche PATTERN benutzt, die reguläre Ausdrücke für Züge im Damespiel darstellen.
/****************
*
* dame1.l
*
* author: gdh
* first: oct-31, 2003
* last:-
* idea: flex-demo-datei fuer zug im damespiel
*
****************/
%{
#include "dame1.h"
%}
%%
[ \t]+ ; /* Blanks und Tabs werden ueberlesen */
\n {return(ZEILENENDE);}
[a-h][1-8]:[a-h][1-8](,[a-h][1-8])* {return(ZUG);}
%%
Aus dieser Datei dame1.l lässt sich dann schon die Datei lex.yy.c erzeugen:
gerd@kant:~/public_html/fh/I-PROGR3/I-PROGR3-TH/VL5> flex dame1.l
Dann wird eine Headerdatei dame1.h angelegt, da sowohl flex als auch das aufrufende Hauptprogramm bestimmte Konstanten gemeinsam nutzen sollen.
/**************** * * dame1.h * * author: gdh * first: oct-31, 2003 * last:- * idea: flex-demo-datei fuer zug im damespiel * ****************/ #include <stdio.h> #define ZUG 256 #define ZEILENENDE 257
Dazu benötigen wir noch die Usage Datei, die die Funktion yylex() aus der Datei lex.yy.c benutzt:
/****************
*
* usage_dame.cpp
*
* author: gdh
* first: oct-31, 2003
* last:-
* idea: Benutzung einer lex-datei
*
* compilation: gcc -o usage_dame usage_dame.cpp lex.yy.c -lfl
* usage: usage_dame
*
****************/
#include <iostream>
#include "dame1.h"
using namespace std;
int main(void){
extern int yylex(void);
int token;
while(token=yylex() ){
switch(token){
case ZUG: {cout << "ZUG" << endl; break; }
case ZEILENENDE: {cout << "ZEILENENDE" << endl; break; }
default: {cout << "FEHLER" << endl; break;}
}/* End of token */
}/* End of while */
return (1);
}
Jetzt lässt sich der Scanner kompilieren, der die flex-Funktion zum erkennen der regulären ausdrücke für Züge im Damespiel enthält:
gerd@kant:~/public_html/fh/I-PROGR3/I-PROGR3-TH/VL5> g++ -o usage_dame usage_damelex.cpp lex.yy.c -lfl
Es folgt ein Aufruf mit Beispielen:
gerd@kant:~/public_html/fh/I-PROGR3/I-PROGR3-TH/VL5> ./usage_dame a1:b2 ZUG ZEILENENDE a1:b2,c5 ZUG ZEILENENDE a1:b4t3 /* <--- Falsche Eingabe mit 't3' */ ZUG t3ZEILENENDE
Natürlich kann man in flex zur Vereinfachung von längeren Ausdrücken auch Makros einführen. Dazu schreibt man
im Definitionsteil ausserhalb des durch %{ %} geklammerten Teils eine Kombination
NAME ERSETZUNGSTEXT
z.B. (siehe unten)
FELD [a-h][1-8]
Hier steht der Name 'FELD' als Abkürzung für den regulären Ausdruck '[a-h][1-8]'. Man kann dann den Namen 'FELD' im Regeltext benutzen, indem man dieses Makro durch geschweifte Klammern '{FELD}' markiert. Das bisherige Beispiel sieht dann wie folgt aus:
/****************
*
* dame2.l
*
* author: gdh
* first: nov-1, 2003
* last:-
* idea: flex-demo-datei fuer zug im damespiel
*
****************/
%{
#include "dame1.h"
%}
FELD [a-h][1-8]
%%
[ \t]+ ; /* Blanks und Tabs werden ueberlesen */
\n {return(ZEILENENDE);}
{FELD}:{FELD}(,{FELD})* {return(ZUG);}
%%
Kompilierung und Gebrauch (Usage) folgt:
gerd@kant:~/public_html/fh/I-PROGR3/I-PROGR3-TH/VL5> flex dame2.l gerd@kant:~/public_html/fh/I-PROGR3/I-PROGR3-TH/VL5> g++ -o usage_dame2 usage_damelex.cpp lex.yy.c -lfl gerd@kant:~/public_html/fh/I-PROGR3/I-PROGR3-TH/VL5> ./usage_dame2 a1:b4 ZUG ZEILENENDE a1:b3,c5,h8 ZUG ZEILENENDE a9:b3 /* <------- Falsche Eingabe mit '9' */ a9:b3ZEILENENDE
Als nächstes kann man die Zeichenkette, die mit einem Pattern erkannt worden ist, als Wert auch direkt ausgeben. Dazu muss man auf die Variable 'yytext' zugreifen, in der flex die erkannten Zeichen speichert.
/****************
*
* dame3.l
*
* author: gdh
* first: nov-1, 2003
* last:-
* idea: flex-demo-datei fuer zug im damespiel
*
****************/
%{
#include "dame1.h"
#include
%}
FELD [a-h][1-8]
%%
[ \t]+ ; /* Blanks und Tabs werden ueberlesen */
\n {return(ZEILENENDE);}
{FELD}:{FELD}(,{FELD})* { printf(" INPUT = %s\n ",yytext); return(ZUG);}
%%
gerd@kant:~/public_html/fh/I-PROGR3/I-PROGR3-TH/VL5> flex dame3.l gerd@kant:~/public_html/fh/I-PROGR3/I-PROGR3-TH/VL5> g++ -o usage_dame3 usage_damelex.cpp lex.yy.c -lfl gerd@kant:~/public_html/fh/I-PROGR3/I-PROGR3-TH/VL5> ./usage_dame3 a1:b3 INPUT = a1:b3 ZUG ZEILENENDE a1:b4,c5,h3 INPUT = a1:b4,c5,h3 ZUG ZEILENENDE b9:t2 b9:t2ZEILENENDE
Natürlich kann man die Werte von yytext auch in eine andere Variable kopieren, z.B. in den array 'token_input':
/****************
*
* dame4.l
*
* author: gdh
* first: nov-1, 2003
* last:-
* idea: flex-demo-datei fuer zug im damespiel
*
****************/
%{
#include "dame1.h"
#include
#include
char token_input[100];
%}
FELD [a-h][1-8]
%%
[ \t]+ ; /* Blanks und Tabs werden ueberlesen */
\n {return(ZEILENENDE);}
{FELD}:{FELD}(,{FELD})* { printf(" INPUT = %s\n ",yytext);
strcpy(token_input,yytext);
printf(" KONTROLLE = %s\n ",token_input);
return(ZUG);
}
%%
gerd@kant:~/public_html/fh/I-PROGR3/I-PROGR3-TH/VL5> flex dame4.l gerd@kant:~/public_html/fh/I-PROGR3/I-PROGR3-TH/VL5> g++ -o usage_dame4 usage_damelex.cpp lex.yy.c -lfl gerd@kant:~/public_html/fh/I-PROGR3/I-PROGR3-TH/VL5> ./usage_dame4 a1:b4 INPUT = a1:b4 KONTROLLE = a1:b4 ZUG ZEILENENDE c4:b5,d1,h8 INPUT = c4:b5,d1,h8 KONTROLLE = c4:b5,d1,h8 ZUG ZEILENENDE a2:b4,k3,c5 /* <--- Fehler k3 */ INPUT = a2:b4 KONTROLLE = a2:b4 ZUG ,k3,c5ZEILENENDE
Diese Variable 'token_input' kann man dann auch vom Hauptprogramm aus aufrufen. Man muss sie dem Programm nur bekannt machen:
/****************
*
* usage_dame5.cpp
*
* author: gdh
* first: nov-1, 2003
* last:-
* idea: Benutzung einer lex-datei
*
* compilation: gcc -o usage_dame4 usage_dame4.cpp lex.yy.c -lfl
* usage: usage_dame4
*
****************/
#include <iostream>
#include "dame1.h"
using namespace std;
int main(void){
extern int yylex(void);
extern char token_input[];
int token;
while(token=yylex() ){
switch(token){
case ZUG: { cout << "ZUG" << endl;
cout << "C++ Ausgabe von token_input : " << token_input << endl;
break; }
case ZEILENENDE: {cout << "ZEILENENDE" << endl; break; }
default: {cout << "FEHLER" << endl; break;}
}/* End of token */
}/* End of while */
return (1);
}
Kompilierung und Nutzung wie vorher:
gerd@kant:~/public_html/fh/I-PROGR3/I-PROGR3-TH/VL5> g++ -o usage_dame5 usage_dame5.cpp lex.yy.c -lfl gerd@kant:~/public_html/fh/I-PROGR3/I-PROGR3-TH/VL5> ./usage_dame5 a1:b4,c5 INPUT = a1:b4,c5 KONTROLLE = a1:b4,c5 ZUG C++ Ausgabe von token_input : a1:b4,c5 ZEILENENDE c2:b4,c5,d6 INPUT = c2:b4,c5,d6 KONTROLLE = c2:b4,c5,d6 ZUG C++ Ausgabe von token_input : c2:b4,c5,d6 ZEILENENDE
Werden in den Übungsstunden bekannt gegeben