|
|
I-PROGR2 SS03 - PROGRAMMIEREN2 - Vorlesung mit Übung
|
In der vorausgeheden VL wurde die Grundidee des Klassenkonzeptes als einer abstrakten Beschreibung einer potentiell unendlich grossen Menge möglicher konkreter Objekte eingeführt. Zugleich wurde die Entscheidung gefällt, die Repräsentationen von Klassen, ihren Objekten und deren Interaktionen primär mit den Mitteln von UML darzustellen und diese abstrakten Konzepte dann mit den Mitteln von C++ zu implementieren. Auf den ersten Blick mag diese Entscheidung umständlich erscheinen, im weiteren Verlauf wird man aber --hoffentlich-- sehen, dass die Einbeziehung der UML-Darstellungsmittel einen Zuwachs an konzeptioneller Klarheit bringen wird. Schon das heutige kleine Beispiel wird zeigen, dass ohne die Einbeziehung von UMl schon elementare Sachverhalte kaum sichtbar werden.
Es sei aber hier ausdrücklich darauf hingewiessen, dass bei den UML-Darstellungen in der Regel Vereinfachungen vorgenommen werden, da der primäre Zweck hier kein Kurs in UML ist (dazu sei auf den Standard direkt verwiessen), sondern eine Einführung in die objektorientierte Programmierung, für die wir UML soweit einbeziehen, als es uns dabei hilft.
Wir beginnen die Überlegungen mit einen Ausschnitt aus unserem Synapsenproblem, nämlich der Punpe als Teil einer postsynaptischen Membran. Wir übersetzen dieses Problem in eine onbjektorientierte Struktur mittels UML. Anschliessend wird die UML-Darstellung in eine C++-Darstellung konvertiert.
Das auf die Ionenpumpe reduzierte Problem kann man vereinfachend so umschreiben: im Rahmen des synaptischen Spaltes ('synaptic gap') liegt für eine bestimmte Substanz eine bestimmte Konzentration 'sextern' vor, die sich im Vergleich zur Konzentration im Innern der postsynaptischen Membran (sintern) praktisch nicht ändert. Wohl kann sich die interne Konzentration in Abhänigkeit von verschiedenen Ereignissen ändern (Wertebereich [0,n] mmol). Für eine Ionenpumpe wird angenommen, dass sie einen Rezeptor hat, der auf einen bestimmten Schwellwert ('threshold', theta) eingestellt ist. Wird dieser Schwellwert in Abhängigkeit von der Pumprichtung ('direction', dir = in bzw. 0 oder dir = out bzw. 1) unterschritten bzw. überschritten, dann wird die Pumpe eingeschaltet und sie pumpt entsprechend ihrer Kapazität ('capacity', cap) eine bestimmte Menge entweder 'hinein' oder 'hinaus'.
Sicher sind bei dieser Problemstellungen verschiedene Analysen möglich. Die folgende Lösung wurde im Hinblick auf die weitere Fortsetzung gewählt und um besondere Eigenschaften von Klassen/ Objekten sichtbar zu machen.
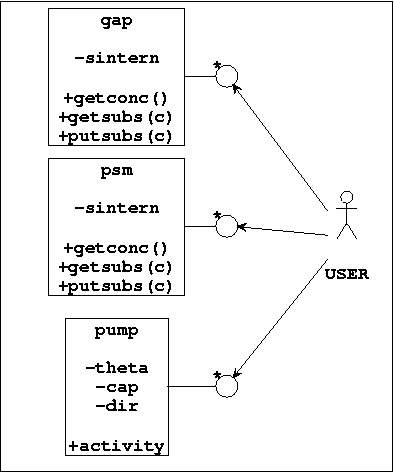
Use Case für Pumpenbeispiel
Das Diagramm zeigt einen sogenannten Use Case: ein User in Interaktion mit den im Problem identifizierten Klassen.
Diese Art der Darstellung ergibt sich aus der Tatsache, dass Klassen 'in sich geschlossene' Gebilde sind, von denen gegenüber der Ausenwelt, also gegenüber einem potentiellen User, nur das sichtbar ist, was öffentlich ('public', '+') ist (Idee des 'Information Hiding').
In unserem Beispiel wurde angenommen, dass sich das Problem in drei Klassen zerlegen lässt:
Die Klasse gap: sie repräsentiert den synaptischen Spalt. Ihre einzige Eigenschaft (Attribut) besteht darin, dass sie zu jedem Zeitpunkt eine bestimmte Substanzkonzentration (-sextern) besitzt. Diese Eigenschaft ist 'privat' ('-'); von aussen ist sie niemandem zugänglich. Allerdings stellt die Klasse gap einige öffentliche Operationen (Methoden) zur Verfügung, mittels deren ein externer User mit der Klasse kommunizieren kann. Es gibt die öffentliche Operation +getconc(); über die kann ein externer User abfragen, welchen Wert die externe substanzkonzentration aktuell hat. Ferner gibt es noch die beiden öffentlichen Operationen +getsubs(c) sowie +putsubs(c). Mittels diesen Operationen kann man c-viele Einheiten einer substanz entweder von der Klasse gap anfordern oder in der Klasse gap 'abladen'. Allerdings gelten die durch Ionenpumpen transportierbaren Mengen als so gering im Verhältnis zum Volumen der Flüssigkeit ausserhalb der Membran, dass diese Mengen sich auf den Wert sextern nicht auswirken.
Die Klasse psm: sie repräsentiert eine postsynaptische Membran. Sie ähnelt in der Stuktur der Klasse gap. Einziger Unterschied, statt dem Attribut '-sextern' hat die Klasse psm das Attribut -sintern. Werden mittels der Operationen +getsubs(c) sowie +putsubs(c) Substanzen aus der Membran 'herausgeholt' bzw. 'hineingetan', hat dies --im Gegensatz zur Klasse gap-- sehr wohl eine Wirkung; entsprechend den c-vielen Elementen, die entweder in die Klasse hineingetan oder herausgeholt werden, verändert sich der Wert von sintern!
Die Klasse pump: dies ist die Pumpe, die modelliert werden soll. Sie hat drei private Attribute und eine öffentliche Operation. Das private Attribut -theta repräsentiert den Schwellwert, auf den die Pumpe eingestellt sein soll. cap repräsentiert die Kapazität, die durch die Pumpe bewältigt werden kann (zur Erinnerung: 'tatsächliche' Ionenpumpen transportieren immer nur 1-2 Ionen einer Substanzart; dafür gibt es pro Substanz mehrere tausend solcher Pumpen; im Modell idealisieren wir diese tausenden von 'Einfachpumpen' als eine 'Mehrfachpumpe'). Schliesslich wird mit -dir die Pumprichtung festgelegt; jede Pumpe ist für eine ganz bestimmte Richtung (zusammen mit Schwellwert und Substanzart) festgelegt. diese privaten Werte kennt nur die Pumpe. Als einzige öffentliche Operation gibt es die Operation +activity(si). Diese Operation bekommt als Input den aktuellen Konzentrationswert der Membran, hier als si, und muss dann in Abhängigkeit davon entscheidne (i) ob gepumpt werden muss, und wenn ja, (ii) wieviel in welche Richtung.
Es stellt sich jetzt die Frage, wer ist eigentlich der User? Wir stellen die Beantwortung dieser Frage für einen Moment zurück. Stattdessen wollen wir der Frage nachgehen, wie denn generell die Interaktion zwischen unseren Klassen aussehen muss.

Sequenzdiagramm zur Repräsentation von Interaktion
Das Sequenzdiagramm setzt voraus, dass es konkrete Objekte der zuvor definierten Klassen gibt, nämlich das Objekt g1 der Klasse gap, usw.
Zu jedem Objekt gehört eine 'Lebenslinie' als Zeitachse (von oben nach unten). Bevor der eigentliche Lauf ('Run') losgeht, müssen bei allen beteiligten Objekten die notwendigen Anfangswerte gesetzt werden (Initialisierung, 'Initialize'). Ist diese Phase abgeschlossen, beginnt das eigentliche Geschehen als 'Run'. Dieser Run ist repetitiv: Ist das Ende der Zeitpfeile erreicht, beginnt der Run wieder von vorne.
Die Grundstruktur stellt sich wie folgt dar: Zuerst wird das ps1-Objekt nach dem aktuellen Konzentrationswert si gefragt. Dann wird das Pumpenobjekt p1 aufgerufen und die Funktion p1:activity(si) gestartet. Diese prüft, ob gepumpt werden muss. Wenn ja, dann wird --in Abhängigkeit von der eingestellten Richtung-- entweder von aussen nach innen oder von innen nach aussen gepumpt. Für jeden Pumpvorgang müssen also die entsprechenden Funktionen des Objektes g1 und ps1 aktiviert werden.
An dieser Stelle der UML-orientierten Analyse soll abgebrochen werden und geschaut werden, wie sich diese bislang erarbeiteten Strukturen nach UML übersetzen lassen.
Für eine Übersetzung der UML-Klassen in die entsprechende C++-Klassen genügt es, zu wissen, wie man die Attribute und Operationen samt der 'Sichtbarkeit' (privat, öffentlich...) übersetzt.
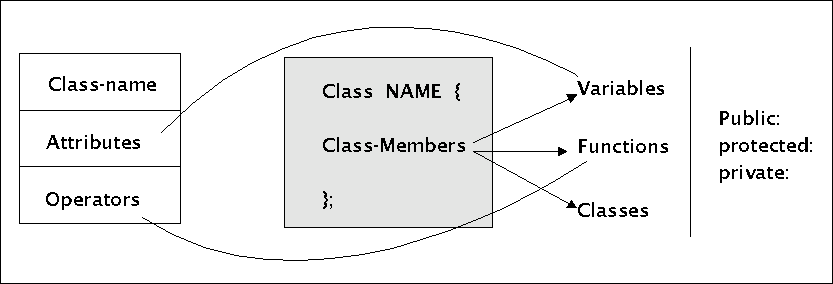
Von UML nach C++
Aus dem Schaubild kann man entnehmen, dass dem Rechteck, das in UML eine Klasse repräsentiert, in C++ das struct-Gebilde 'class NAME { ... }; entspricht.
Die UML-Attribute werden innerhalb einer C++-Klasse als Elemente dargestellt, die wie Variablen deklariert werden.
Die UML-Operationen werden in einer C++-Klasse ebenfalls als Elemente aufgeführt, die wie Funktionen (und zwar normalerweise) nur die Prototypen) deklariert werden.
Die UML-Sichtbarkeitsindikatoren '-', '#' sowie '+' werden in C++ entsprechend durch die Schlüsselwörter 'private:', 'protected:' sowie 'public:' dargestellt.
Während die Anordnung der Attribute und Operationen in einer UML-Klasse streng geregelt ist, kann man in einer C++-Klasse die Elemente (inklusive der Sichtbarkeitsindikatoren) beliebig anordnen und mischen.
Eine einfache C++Klasse zeigt das nachfolgende Code-Fragment:
//--------------------------
//
// dummy.h
//
//--------------------------
class DUMMY {
// Variables
private:
int x;
public:
float size;
// Member-Functions
public:
dummy();
float show_size();
private:
void change(int);
~dummy();
};
Auffällig könnten in diesem Code-Fragment jene Element-Funktionen sein, die den gleichen Namen haben wie die Klasse. Jene Funktionen mit gleichen Namen wie die Klasse und ohne vorausgehende Tilde '~' das sind die sogenannten Konstruktoren. Jene mit einer vorausgehenden Tilde, das sind die Dekonstruktoren. Konstruktoren und Dekonstruktoren sind in UML nicht notwendig (trotzdem natürlich darstellbar). Konstruktoren und Dekonstruktoren bilden einen deutlichen UNterschied von C++ zu UML und dokumentieren, dass C++ nicht nur eine abstrakte objektorientierte Darstellungsweise bietet, sondern darüberhinaus ja auch eine mögliche konkrete Implementierung. Man könnte auch sagen, dass die Konstruktoren und Dekonstruktoren gleichsam eine Brücke schlagen zwischen den abstrakten Klassenkonzepten und konkreten, lauffähigen Objekten als Instanzen der Klassen. Ein Konstruktor ist nämlich genau jene Funktion, die aktiviert wird, wenn in einem Programm eine konkrete Instanz einer abstrakten Klasse --auch Objekt genannt-- gebildet wird. Zu jeder konkreten Instanz gehört neben dem Namen (:= Objektnamen) und dem Typ (:= hier eine Klasse!) normalerweise auch die Reservierung von Speicherplatz und die Belegung mit konkreten Werten. Diese 'Arbeiten' werden bei Initialisierung eines konkreten Objektes von der Konstruktorfunktion geleistet. Der Dekonstruktor ist dann --wie der Name schon nahelegt, für das 'Abräumen' bzw. das 'Aufräumen' eines zuvor eingeführten Objektes zuständig. Soll ein Objekt wieder gelöscht werden, dann ist es Aufgabe des Dekonstruktors, alle zuvor reservierten Speicherplätze, aktivierten Funktionen und Filedeskriptoren wieder zu löschen.
In den meisten Fällen benötigt eine Anwendung --wie auch schon unser einfaches Beispiel-- mehr als nur eine Klasse. Um hier den Überblick zu halten, empfiehlt es sich, die verschiedenen Code-fragmente in einer klaren Anordnung abzulegen. Wie schon in C, wo in der Regel zwischen dem Hauptprogeamm mit main(), verschiedenen Headerdateien (.h) mit den Funktionsprototypen sowie den Implementierungen der Funktionen in .c-Dateien unterschieden wurde, wird im allgemeinen auch in C++ eine ähnliche Vorgehensweise ('policy') befolgt (siehe Schaubild):
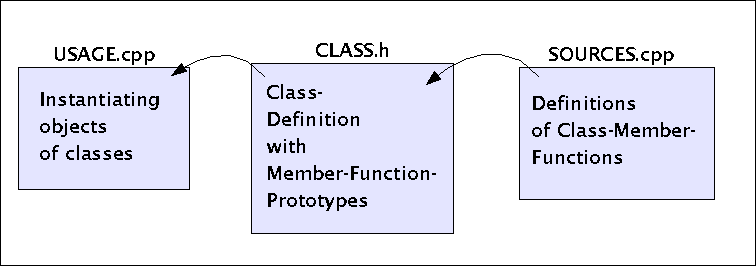
Verteilung des Codes auf verschiedene Dateien
Jede Klasse hat normalerweise ihre eigene Headerdatei (.h oder .hpp) mit der Klassendefinition und Funktionsprototypen und zusätzlich eine Implementierungsdatei gleichen Namens, nur mit der Endung .cc oder .cpp. Ausserdem gibt es auch hier eine Hauptdatei mit der Funktion main(), in der die Instanzen der Klassen erzeugt und benutzt werden.
An dieser Stelle wird deutlich, dass der User in C++ eine Funktion ist, nämlich die main-Fuktion, in der Objekte der Klassen erzeugt und nach Bedarf über ihre öffentlichen Element-Funktionen benutzt werden.
Nach dieser Identifizierung des Users unseres Use Cases als das Programm mit der main-Funktion --das wir deshalb auch usage.cpp nennen-- kann man noch zwei weitere wichtige Einsichten festhalten:
Die Umsetzung des Aktivitätsdiagramms findet in dem Programm statt, in dem die Objekte erzeugt werden, denn nur dort stehen die Elementfunktionen der erzeugten Objekte zur Verfügung.
Die Initialisierungsphase wird durch die Konstruktoren der jeweiligen Klassen bei der Objektinstantiierung geleistet.
Der eigentliche 'Run' wird ebenfalls in jenem Programm geleistet, in dem die Objekte erzeugt wurden. Sofern der Run repetitiv ist, muss dies durch eine Schleife realisiert werden.
Der folgende Sourcekode ist nicht vollständig bzgl. der geplanten Funktionalität der Klassen, ist aber in einem Zustand, dass er sich kompilieren lässt.
Ab diesem Beispiel wird auch Gebrauch gemacht von dem Programm 'make' (für Details siehe 'man make' oder 'info make' unter Linux). Ab einer bestimmten Anzahl von beteiligten Dateien ist dieses Werkzeugt fast unverzichtbar. Man listet in einer Datei mit Namen 'Makefile' alle Dateien auf, die zum Projekt gehören sowie ihre Abhängigkeiten untereinander. Nach jeder Änderung einer einzelnen --oder einiger weniger-- Datei(en) genügt es dann, in dem Ordner, in dem das Makefile und die beteiligten Dateien abgelegt sind, 'make' auf der Kommandozeile einzugeben. Das Programm make identifiziert dann mit Hilfe der Makefile-Datei, welche Dateien überhaupt im Projekt vorkommen und überprüft automatisch, welche Dateien seit dem letzten Mal tatsächlich verändert wurden. Es werden dann nur diejenigen Dateien neu kompiliert, die geändert wurden.
objects = usage.o gapsrc.o psmsrc.o pumpsrc.o usage: $(objects) g++ -o usage $(objects) usage.o: usage.cpp g++ -c usage.cpp gapsrc.o: gapsrc.cpp gap.hpp g++ -c gapsrc.cpp psmsrc.o: psmsrc.cpp psm.hpp g++ -c psmsrc.cpp pumpsrc.o: pumpsrc.cpp pump.hpp g++ -c pumpsrc.cpp clean: rm usage $(objects)
In der nachfolgenden Datei usage.cpp mit dem Hauptprogramm main() wurde das Aktivitätsprogramm noch nicht vollständig implementiert; auch sind die nachfolgenden Klassen noch 'unvollständig'. Man kann aber zu Beginn deutlich die drei Konstruktoren gap::gap g1(100); psm::psm psm1(120); pump::pump pmp1(80,50,0); erkennen, für jedes instantieerte Objekt einer. Jeder Konstruktor ist so gebaut, dass er die notwendigen Initialisierungswerte für die Objekte zu Beginn übernehmen kann.
//-----------------------
//
// usage.cpp
//
// Compilation: make
// Usage: usage
//
// author: gerd d-h
// first: april-2, 2003
//-----------------------
#include "gap.hpp"
#include "psm.hpp"
#include "pump.hpp"
#include <iostream>
using namespace std;
int main(){
int si;
int c;
gap::gap g1(100); // Init with sextern
psm::psm psm1(120); // Init with sintern
pump::pump pmp1(80,50,0); //Init with Theta, cap, dir=0 := 'in'
cout << "Nur ein Test" << endl;
cout << "Ausgabe von gap = " << g1.getsubst(20) << endl;
cout << "TEST = " << psm1.getsubst(20) << endl;
cout << "TEST = " << psm1.putsubst(30) << endl;
cout << "TEST = " << psm1.getconc() << endl;
si = psm1.getconc();
cout << "PMP-Out = "<< pmp1.activity(si) << endl;
}
//-----------------------------
//
// gap.hpp
//
//------------------------------
#ifndef GAP_HPP
#define GAP_HPP
#include <iostream>
class gap {
private:
int sextern;
public:
gap(int);
int getsubst(int);
};
#endif
Am Beispiel des Konstruktors 'gap(int)' der Klase gap kann man sehen, wie der Mechanismus der Initialisierung von Werten realisiert ist. Zwischen Funktionskopf gap::gap(int se) und Funktionsrumpf {...} gibt es eine Liste, eingeleitet mit einem Doppelpunkt ':', gefolgt von Variablennamen der Klasse gap --hier nur einer-- mit runden Klammern (). Die Werte in den runden Klammern übergeben Initialisierungswerte an diese Variablen. sextern(se) besagt dann, dass das Argument der Funktion gap::gap(int se) an die Variable sextern überwiesen werden soll. Da es sich bei der Funktion gap::gap(int se) um einen Konstruktor handelt, der zu Beginn eines Programms aufgerufen wird, und bei diesem aufruf ein Argumentwert übergeben werden kann, kann man auf diese Weise beim Aufruf den Variablen einer Klasse Werte zuweisen.
#include <iostream>
#include "gap.hpp"
using namespace std;
gap::gap(int se)
: sextern(se) //gap mit se initialisieren
{
//Keine weiteren Anweisungen
}
int gap::getsubst(int c){
cout << "Aktuelle externe Konzentration = " << sextern << endl;
return c;
}
//-----------------------------
//
// psm.hpp
//
//------------------------------
#ifndef PSM_HPP
#define PSM_HPP
class psm {
private:
int sintern;
public:
psm(int);
int getsubst(int);
int putsubst(int);
int getconc();
};
#endif
#include <iostream>
#include "psm.hpp"
using namespace std;
psm::psm(int si)
: sintern(si) //psm mit si initialisieren
{
//Keine weiteren Anweisungen
}
int psm::putsubst(int c){
cout << "PSM: Receiving substance = " << c << endl;
sintern+= c;
return sintern; // Give new sintern back
}
int psm::getsubst(int c){
cout << "PSM: Transmitting Substance = " << c << endl;
if ((sintern - c) <= 0) sintern=0;
else sintern-=c;
return sintern; // Give new sintern back
}
int psm::getconc(){ //Get Concentration
cout << "PSM: Aktuelle interne Konzentration = " << sintern << endl;
return sintern;
}
//-----------------------------
//
// pump.hpp
//
//------------------------------
#ifndef PUMP_HPP
#define PUMP_HPP
class pump {
private:
int theta; // Threshold for activation
int cap; // Pumping capacity
int dir; // Direction of pumping
public:
pump(int,int,int); //theta, cap, dir
int activity(int); //Depending from theta and si the pump will become active
};
#endif
#include "pump.hpp"
#include <iostream>
using namespace std;
pump::pump(int t,int c,int d)
: theta(t), cap(c), dir(d)
{
//Keine weiteren Anweisungen
}
int pump::activity(int si) {
if (dir == 0) {
cout << "PMP: Case dir = 0 "<< endl;
if (si < theta){ //Pumping from extern to intern
return cap;
}
else {return 0;}
}
else {
cout << "PMP: Case dir = 1 "<< endl;
if (si > theta) {cout << "PMP: Has to pump outwards" << endl;}
else {cout << "PMP: Nothing to do" << endl; }
}
}
Was wird in einem Use Case dargestellt?
Wie können verschiedene Klassen miteinander kommunizieren?
Welches sind die drei wichtigen Abteilungen in einer UML-Klassendarstellung?
Welchen Zweck erfüllt ein UML-Aktivitätsdiagramm?
Was sind die wichtigsten Elemente eines UML-Aktivitätsdiagramms?
Beschreiben Sie, wie sie die Elemente einer UML-Klasse in eine C++-Klasse übersetzen.
Geben sie ein Beispiel für eine einfache C++-Klasse.
Was sind Konstruktoren und Dekonstruktoren; beschreiben Sie ihre Aufgabe.
Wie ordnet man normalerweise die Elemente eines Projektes mit vielen C++-Dateien an?
In welcher Weise kann das Werkzeug 'make' Sie bei einem Programmierprojekt unterstützen?
Beschreiben Sie den Zusammenhang zwischen einem UML-Aktivitätsdiagramm und jenem Programm in C++, in dem die Objekte der Klassen erzeugt werden.
Beschreiben Sie den Mechanismus, wodurch ein Konstruktor bestimmte Variablen einer Klasse initialisieren kann.
Welche zusätzlichen Möglichkeiten bietet ein Konstruktor sonst noch?
Vervollständigen Sie die Klassendefinitionen des Pumpen-Beispiels
Implementieren Sie das UML-Aktivitätsdiagramm vollständig in C++.
Erarbeiten Sie sich das Kanal-Beispiel vollständig in UML und setzen es vollstndig in C++ um.