|
|
GRUNDLAGEN DER INFORMATIK WS 0203 - Vorlesung
|
In der vorausgehenden Vorlesung ist verdeutlicht worden, dass die prinzipielle Veränderungsfähigkeit, die biologischen lernenden (=intelligenten) Systeme zugrunde liegt, auch einem Computer zur Verfügung steht. In dieser Vorlesung soll der Frage nachgegangen werden, ob ein Computer auch so lernen könnte, so wie biologische Systeme im allgemeinen und Menschen im Besonderen lernen.
Wenn man die Frage beantworten will, ob Computer lernen können, dann muss man, wie schon in der vorausgehenden Vorlesung zur Frage der Intelligenz, klären, was man unter dem Begriff 'Lernen' in diesem Kontext verstehen will. Auch in diesem Fall gibt es unter der Überschrift Lerntheorien eine starke Tradition in der Psychologie; zugleich gibt es eine umfangreiche Literatur zu mathematischen Lerntheorien und zum maschinellen Lernen; z.T. gbt es zwischen diesen Gebieten Wechselwirkungen. Da in dieser Vorlesung keine Einführung in diese umfangreichen Gebiete gegeben werden kann, muss versucht werden, anhand eines Beispiels die Grundidee des Problems zu vermitteln. In diesem Kontext ist der Begriff des Lernparadigmas wichtig.
Ein Lernparadigma ist praktisch die Beschreibung desjenigen Rahmens, innerhalb dessen man einen bestimmten Begriff von Lernen definiert. Das nachfolgende Bild zeigt z.B. die Elemente, die im sogenannen Reinforcement-Learning (Verstärkungs-Lernen) als Bestandteile des Lernens angenommen werden.
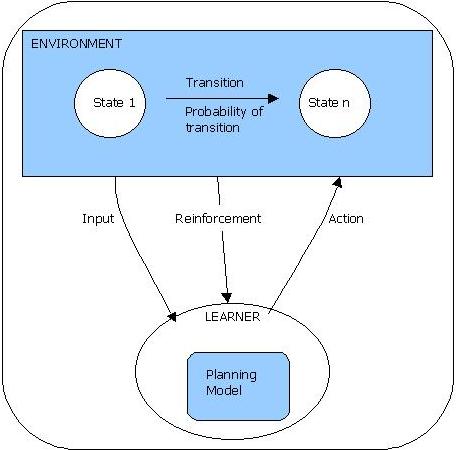
Diagramm zum Paradigma des Reinforcement-Learnings
In einer Kurzbeschreibung des Reinforcement-Learnings (für eine ausführlichere Diskussion siehe Lernparadigma des Reinforcement Learnings) könnte man sagen, dass ein Lerner L in einer Welt ('environment') lebt, die stationär ist (d.h., sich nicht verändert), oder nicht-stationär (d.h. die Zustände der Welt ändern sich mit gewissen Wahrscheinlichkeiten). Von der Welt bekommt der Lerner L einen näher zu bestimmenden Input und Informationen, die der Lerner als Reinforcement (Verstärkung) auffasst. Ferner kann eine Lerner über zu beschreibende Aktionen auf die Welt einwirken. Das Lernziel besteht darin, die Verstärkung zu maximieren.
Das nächste Bild zeigt eine Variante eines Paradigmas zum Textlernen. In diesem Beispiel besteht die Umgebung des Lerners L aus Texten, die ihm in Form von Sätzen dargeboten werden. Jeder Satz besteht aus Worten über einem Alphabet T. Die Aufgabe des Lerners besteht darin, eine Vermutung (Hypothese) darüber auszubilden, wie die Worte aus der Textmenge innerhalb von Sätzen angeordnet werden dürfen. Das Lernverfahren besteht darin, dass der Lerner aus einer Trainingsmenge nacheinander alle Sätze bekommt, und er anhand dieser Beispiele eine Vermutung über die mögliche Form ausbilden muss. Falls er es schafft, anhand der Trainingsmenge eine solche Vermutung auszubilden, kann er mit den Sätzen einer vorher festgelegten Testmenge geprüft werden. Eine korrekte Antwort liegt vor, wenn er bei einem Satz, der zur Testmenge mit 'YES' antwortet und bei einem Satz, der nicht dazu gehört, mit 'NO'.
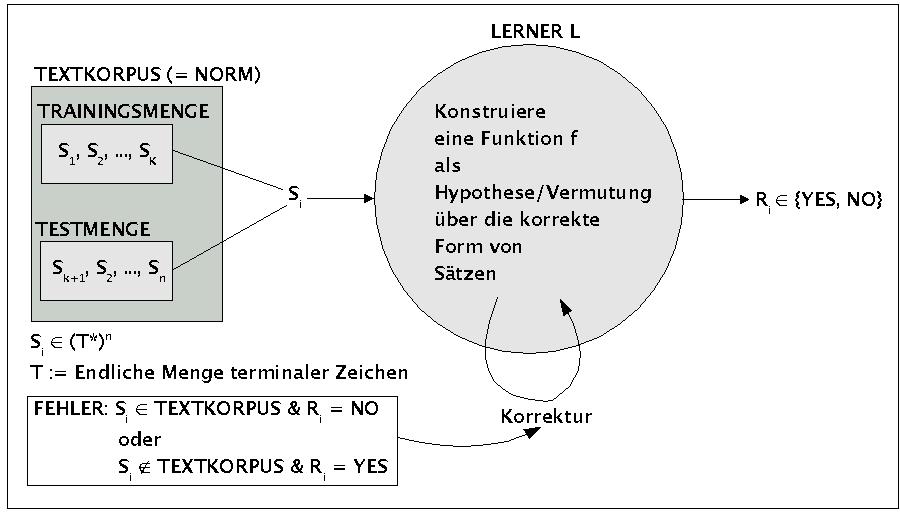
Diagramm zu einem Paradigma des Textlernens
Während der Lernphase erhält der Lerner keine zusätzlichen Informationen wie beim Reinforcement-Learning; er kann nur überprüfen, ob der neue Satz aus der Trainingsmenge aufgrund seiner bisherigen Vermutung 'korrekt' ist. Falls nicht, dann muss er entweder die bisherige Vermutung korrigieren oder sie erweitern.
Um nun etwas mehr Licht in die Frage zu bekommen, ob ein Computer lernen kann, wollen wir uns ein sehr einfaches Beispiel des Textlernens etwas näher anschauen.
Stark vereinfacht soll hier überlegt werden, wie das Erlernen von Satzformen stattfinden könnte. Ausgangspunkt sei ein Textkorpus mit 2-4 Wort Sätzen, etwa:
Hans ist gross.
Inge singt.
Das Haus brennt.
Peter lacht.
Inge war traurig.
Peter lacht nicht.
Das Auto ist klein
Peter weint.
Das Tor ist dünn.
Peter kennt Hans.
Anna kommt nicht.
Inge ist lustig.
Inge ist dünn.
Anna kommt.
Anna ist traurig.
Hans lacht.
Anna ist gross.
Peter singt.
Anna kennt Inge nicht.
Hans kennt das Auto.
Inge kommt nicht.
Dieses Textkorpus soll alle Sätze einer Testsprache repräsentieren. Das Textkorpus wird unteteilt in eine Trainingsmenge TEXT-TR und eine Testmenge TEXT-TST:
Hans ist gross.
Inge singt.
Das Haus brennt.
Peter lacht.
Inge war traurig.
Peter lacht nicht.
Das Auto ist klein
Peter weint.
Das Tor ist dünn.
Peter kennt Hans.
Anna kommt nicht.
Inge ist lustig.
Inge ist dünn.
Anna kommt.
Anna ist traurig.
Hans lacht.
Anna ist gross.
Peter singt.
Anna kennt Inge nicht.
Hans kennt das Auto.
Inge kommt nicht.
Die Lernaufgabe besteht nun darin, dass man dem Lerner L nach und nach die Sätze der Trainingsmenge übergibt. Der Lerner L muss anhand dieser Sätze 'intern' eine Vermutung konstruieren, wie die (syntaktische) Form der Sätze der zu lernenden Sprache aussieht. Nach jedem neuen Satzereignis gibt es für den Lerner L dann die folgende Situation:
Das neue Satzereignis Si = < w1, w2,...,wk > stimmt mit der bisher konstruierten Form der Vermutung überein; keine Änderung notwendig
Das neue Satzereignis Si = < w1, w2,...,wk > stimmt mit der bisher konstruierten Form der Vermutung nicht überein; Änderung der Vermutung notwendig.
Eine offene Frage ist an dieser Stelle ferner, ob die Menge der Trainingssätze ausreichend gross ist, um eine hinreichend gute Vermutung für die Einschätzung der Testsätze zu konstruieren. Angenommen, dass die Menge der Trainingssätze gross genug sei, dann würde ein erfolgreicher Lerner also daran zu erkennen sein, ob er auf der Basis dieser Trainingsmenge in der Lage ist, eine 'richtige' Einschätzung über die zulässige Form der Sätze zu bilden. Konkret: würde man dem erfolgreichen Lerner nun einen Satz aus der Testmenge vorlegen, dann würde er immer mit 'YES' antworten; wäre es ein Satz, der nicht zur Testmenge gehört, dann müsste er sagen 'NO'. Entlang der Zeitachse bedeutet dies, dass ein Erfolgreicher Lerner L nach endlich vielen Schritten einen Zustand erreicht hat, wo er auf der Basis einer endlichen Menge von Beispielen eine Vermutung konstruieren konnte, wie die Form aller Sätze der Testsprache aussieht, auch von solchen Sätzen, die es möglicherweise noch gibt, die er aber zu diesem Zeitpunkt noch nicht explizit kennengelernt hat.
Die Korrektheit (Richtigkeit)einer Antwort ist im Lernkontext eine relative Grösse! Nur insoweit, als man eine bestimmte SOLL-Form (NORM) explizit angeben kann, kann man mit Bezug auf diese Norm sagen 'richtig' oder 'falsch'. Im Falle jeder natürlichen Sprache ist dies ein unlösbares Problem, da die Menge der korrekten Sätze nicht als fertiger Katalog irgendwo dokumentiert ist und auch aus prinzipiellen Gründen nirgendwo vollständig dokumentiert werden kann. Die 'korrekte' Sprache existiert letztlich nur in den Sprechern/ Hörern einer Sprache und diese äussern sich immer nur punktuell, partiell, fragmentarisch, gelegentlich. Selbst mehrere Millionen von Textzeugnissen bilden nur einen kleinen Ausschnitt der Menge der möglichen korrekten Sätze.
In dieser Vorlesung ist es nicht möglich, das vorliegende Beispiel technisch in allen Einzelheiten zu analysieren. Dennoch wenigstens ein paar Überlegungen.
Interessant ist offensichtlich die Frage, wie ein Lerner geeignete Vermutungen konstruieren kann. Vom Gehirn wissen wir, dass es seine heutige Form in vielen Millionen Jahren gefunden hat und dass seine heutigen Strukturen implizit sehr viel ' Wissen' enthält, wie Ereignisse 'gelernt' werden können. Bisher kann die Neurobiologie dieses 'implizite' Wissen des Gehirns aber noch nicht vollständig erfassen und als verwertbares Wissen verfügbar machen. Aus der vorausgehenden Vorlesung wissen wir zwar, dass ein Computer im Prinzip alle Strukturen simulieren kann, die das Gehirn auszeichnen, doch kann die Informatik diese Strukturen des Gehirns sich nur in dem Masse zunutze machen, als dieses implizite Wissen auch verfügbar ist. Die Informatik ist also in der Lage zu sagen, dass es im Prinzip einen Algorithmus für alle bekannten Lernaufgaben geben muss, sie kann dieses theoretisch postulierte Postulat bislang aber noch kaum nutzen; es fehlt Detailwissen zu wissenstypischen Anwendungen.
Vor diesem allgemeinen Hintergrund noch der Hinweis, dass ein einfaches 1-zu-1 Erinnern nicht ausreichen würde. Angenommen der Lernern L wäre in der Lage, alle Sätze, die ihm begegnen, einfach vollständig so abzuspeichern, dass er diese bei ihrem nächsten Auftreten wieder erinnern könnte. Mit einer solchen Lernstrategie würde der Lerner L keinen einzigen der Testsätze als korrekt erkennen können.Offfensichtlich hat der Lerner L nur dann eine chance, wenn er in der Lage ist, aufgrund der konkreten Satzbeispiele ein abstrakteres Schema (ein Konzept, eine Grammatik, eine funktion...) zu konstruieren, das es ihm erlaubt auch solche Beispiele zu identifizieren, die er zuvor nicht kennengelernt hat. Die Fähigkeit, ein abstrakteres Schema zu konstruieren, nennt man auch Generalisieren. Es ist nicht möglich, an dieser Stelle eine ausführliche Theorie der Konstruktion solch einer Verallgemeinerung darzulegen, aber zumindest ein Beispiel.
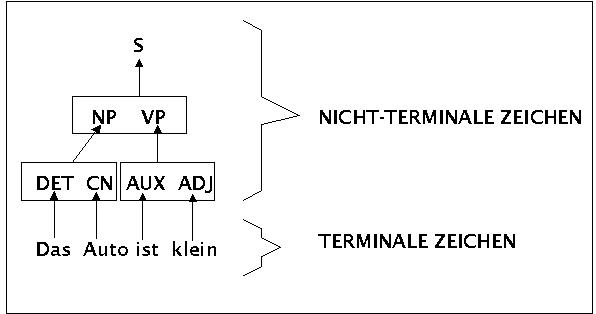
Es ist bekannt, dass man in den Sprachwissenschaften versucht, die korrekte Form von Sätzen mit Hilfe sogenannter Grammatiken zu beschreiben. Im Rahmen der Informatik hat man diesen Ansatz in Form sogenannter formaler Grammatiken für bestimmte Anwendungen ebenfalls ausgearbeitet. Es sei nachfolgend auf informelle Weise kurz gezeigt, wie man zu dem Textkorpus eine Grammatik konstruieren kann, die man als eine Verallgemeinerung der konkreten Satzbeispiele auffassen kann und die so beschaffen ist, dass man damit auch Sätze beurteilen kann, die zuvor noch nicht aufgetreten sind.
Als erstes ordnet man jedem einzelnen Wort, das in den sätzen der Trainingsmenge auftritt, eine Abkürzung zu (die Sprachwissenschaftler sprechen in diesem Fall auch von lexikalischen Kategorien oder Wortkategorien oder auch 'Parts of Speech' (POS)).
N := Hans; AUX := ist; ADJ := gross.
N := Inge; V := singt.
DET := Das; CN := Haus; V := brennt.
N := Peter; V := lacht.
N := Inge; AUX := war; ADJ := traurig.
N := Peter; V := lacht; NEG := nicht.
DET := Das; CN := Auto; AUX := ist; ADJ := klein
N := Peter; V := weint.
DET := Das; CN := Tor; AUX := ist; ADJ := dünn.
N := Peter, V := kennt; N := Hans.
N := Anna; V := kommt, NEG := nicht.
N := Inge; AUX := ist; ADJ := lustig.
Im Anschlusss daran kann man erste 'Regeln' der folgenden Art aufstellen:
S := N AUX ADJ
S := DET CN V .
S := N V
S := N AUX ADJ .
S := N V NEG .
S := DET CN AUX ADJ
S := N V .
S := DET CN AUX ADJ
S := N V N
S := N V NEG
S := N AUX ADJ
Die 'Logik dahinter' ist die, dass die Menge aller Worte eines Satzes eben einen Satz bilden sollen. Nachdem man für jedes Wort eine Abkürzung eingeführt hat, kann man statt der konkreten Worte die Abkürzungen benutzen und erhält dann die obigen Regeln. Diese Regeln sind so zu lesen:
S := N AUX ADJ : Wenn man ein S ersetzt durch N AUX ADJ dann erhält man einen gleichwertigen Ausdruck.
S := DET CN V : Wenn man ein S ersetzt durch DET CN V dann erhält man einen gleichwertigen Ausdruck.
usw.
Schon mit diesen wenigen Abstraktionen könnte man jetzt Sätze auf abstrakte Art konstruieren:
S
N AUX ADJ : Wenn man ein S ersetzt durch N AUX ADJ dann erhält man einen gleichwertigen Ausdruck.
Hans AUX ADJ : Wenn man ein N ersetzt durch "Hans" dann erhält man einen gleichwertigen Ausdruck.
Hans ist ADJ : Wenn man ein AUX ersetzt durch "ist" dann erhält man einen gleichwertigen Ausdruck.
Hans ist gross : Wenn man ein ADJ ersetzt durch "gross" dann erhält man einen gleichwertigen Ausdruck.
Man könnte jetzt versuchen, die schon eingeführten Abkürzungen noch weiter abzukürzen, z.B.:
NP := N
NP := DET CN
NP := DET CN NEG
VP := AUX ADJ
VP := V
VP := V NEG
Mit diesen zusätzlichen Abkürzungen könnte man die S-Regeln etwas kompakter fassen:
S := NP VP
S := NP VP NP
NP := N
NP := DET CN
NP := DET CN NEG
VP := AUX ADJ
VP := V
VP := V NEG
Lassen wir zunächst einmal offen, ob der Lerner L solche (oder ähnliche) Regeln tatsächlich lernen könnte. Nehmen wir nur einmal an, er könnte es; dann würde der Lerner L sich in einem Test jetzt wie folgt verhalten:
Inge ist dünn : N AUX ADJ ==> NP VP ==> S ==> YES
Anna kommt : N V ==> NP VP ==> S ==> YES
Anna ist traurig : N AUX ADJ ==> NP VP ==> S ==> YES
Hans lacht : N V ==> NP VP ==> S ==> YES
Anna ist gross : N AUX ADJ ==> NP VP ==> S ==> YE
Peter singt : N V ==> NP VP ==> S ==> YES
Anna kennt Inge nicht : N V N NEG ==> NP VP NP ==> S ==> YES
Hans kennt das Auto : N V DET CN ==> NP VP NP ==> S ==> YES
Inge kommt nicht : N V NEG ==> NP VP ==> S ==> YES
Dies bedeutet, der Lerner würde den Test gut bestehen. Nicht so klar ist der Fall, wie sich der Lerner mit Sätzen verhält, die nicht im Textcorpus vorkommen. Der Satz:
Inge kennt Anna nicht
kommt so im Textkorpus nicht vor, würde aber vom Lerner mit 'YES' klassifiziert. Die Generalisierung produziert also mehr mögliche Ereignisse als in der endlichen Norm tatsächlich erfasst sind.
Kehren wir aber nochmals zu der Frage zurück, ob es denn vorstellbar sei, dass ein (maschineller) Lerner L überhaupt solch eine Generalisierung wie oben angedeutet generieren kann?
Betrachtet man sich das vorausgehende Beispiel und die Art und Weise, wie dort Regeln 'erfunden' wurden, so kann man auf die Idee kommen, dass man dieses 'Erfinden' von Regeln in einen allgemeinen Prozess, in einen Algorithmus umfformt, dessen Inhalt darin besteht, ausgehend von konkreten Sätzen solche Ersetzungs-Regeln zu finden, die es mit möglichst wenigen Regeln erlauben, damit grössere Mengen konkreter Sätze kompakt zu beschreiben.
Raum möglicher Regeln
Die Frage, ob ein Computer lernen kann würde damit auf die Frage hinauslaufen, ob man einen Algorithmus angeben kann, der es einem Computer erlaubt, solche 'abstrakte Beschreibungen' konkreter Beispiele zu finden, die die 'Identifizierung' auch von solchen konkreten Beispielen erlaubt, die in einer zurückliegenden Lerngeschichte noch nicht aufgetreten sind. Und eines ist sicher: sollte der Raum er Möglichkeiten, der 'abgesucht' werden muss, 'zu gross' sein, dann hat unser Lerner sicher keine Chance. Wenn der Raum überschaubar, endlich ist, dann sollte man vermuten, dass es prinzipiell Wege geben müsste, diejenigen Kombinationen zu finden, die für die jeweils konkrete Lernaufgabe relevant sind. Dennoch kann es sein, dass solche Lösungen, auch wenn Sie prinzipiell erreichbar erscheinen, 'zu lange' dauern um praktisch genutzt werden zu können.
Für eine weitergehende Behandlung dieses spannenden Themas muss aber an dieser Stelle auf eine zukünftige Vorlesung zu lernenden Systemen verwiesen werden.
Was ist ein Lernparadigma?
Wie würden Sie die Aufgabenstellung des vorgestellten Textlernens beschreiben?
Warum reicht eine 1-zu-1 Erinnerung als Lernstrategie nicht aus?
Erzeugen sie mit Hilfe der eingeführten Grammatik ein paar Sätze, die nicht im Textkorpus vorkommen.
Haben Sie eine Idee, nach welcher Strategie Sie einen Algorithmus entwickln würden, mit dem Sie die oben gestellte aufgabe lösen würden?