From the preceding considerations we derive some experiments. All experiments are done with TOLMAN1 and TOLMAN2.1-7 and the possible actions are the following ones:
- Doing 'nothing':
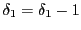
- Moving on free space:
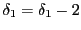
- Moving against obstacles:
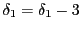
- Moving on a food-position with automatic 'eat':
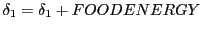
As first basic experiments we assume the following conditions:
- Hungry-Short: Measuring learning function compared to time/ actions and/or errors. Systems: A0 and A1
- Hungry-Long: Measuring learning function compared to time/ actions and/or errors. Systems: A0 and A1
- NotHungry-Hungry-Short: Measuring learning function compared to time/ actions and/or errors. Systems: A0 and A1
- NotHungry-Hungry-Long: Measuring learning function compared to time/ actions and/or errors. Systems: A0 and A1
- NotHungry-Hungry-Short-Goal1-Goal2: Measuring learning function compared to time/ actions and/or errors. Systems: A0 and A1
- NotHungry-Hungry-Long-Goal1-Goal2: Measuring learning function compared to time/ actions and/or errors. Systems: A0 and A1
The following outcomes are inferred from the from the assumptions:
- Hungry-Short: A0 and A1 will solve the task. After the first success A1 will improve quickly to an optimal path, A0 not.
- Hungry-Long: A0 will more and more be 'stuck' in the fast growing number of possibilities. A1 will be guided by its built-in rules and will solve the task. After the first success A1 will improve quickly to an optimal path, A0 not. An open question is, to which extend the episodic memory of A1 has to be increased or whether this kind of memory will be sufficient for long solution paths.
- NotHungry-Hungry-Short: A0 should show no difference in its behavior to the caseHungry-Short. The behavior of A1 will depend on the internal structure of the reward mechanism: (i) if reward is given only in the case of being hungry AND finding food then the learning can not start before being hungry. (ii) If reward will be given to find food even if the system is not hungry (system A1.1) then learning can start from the beginning. But then the behavior would change simultaneously even in the case of being not hungry. This implies that we have to construct a system A1.2 which can learn from the beginning but will make use of this 'learned' information only in the case of being hungry.
- NotHungry-Hungry-Long: The same as before in the case NotHungry-Hungry-Short, but again there will be the question whether and how the size of the episodic memory can enable a solution.
- NotHungry-Hungry-Short-Goal1-Goal2: This assumes that there is at least a version of A1.x which could solve all preceding tasks. While A0 will be able to find a solution but without any observable improvements A1.x should not be able to cope with a changing place of the learned goal. To enable such a behavior one needs a mechanism built into a A1.3 system which allows re-learning either by 'forgetting' or by weakening the old fitness values in case of no success. 'no-success' has to be defined as a kind of 'expectation' which will be 'frustrated'. How shall this be done?
- NotHungry-Hungry-Long-Goal1-Goal2: The same as before again with the special role of the episodic memory. Eventually this requires an A1.4 system.
Gerd Doeben-Henisch
2013-01-14