Next: Genetic Reorganization Up: Basic Idea Previous: Basic Idea Contents
Figure 4.6 shows the general idea of the specialized feedback based on the vital state. The first assumption is that the perception (P) has a built-in causal relationship impact() onto the vital state (V). If something happens this can increase or decrease ENERGY. Then the absolute level of ENERGY will be mapped onto a certain threshold ![]() . If ENERGY is above the threshold
. If ENERGY is above the threshold ![]() than the parameter VITAL (V) is set to '1'; otherwise it is set to '0'.
than the parameter VITAL (V) is set to '1'; otherwise it is set to '0'.
| (4.75) | |||
| (4.76) | |||
| (4.77) |
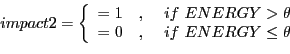
Based on the actual perception ![]() and the actual vital state
and the actual vital state ![]() will the memory as represented by
the set of classifiers CLASSIF be matched with regard to those classifiers
will the memory as represented by
the set of classifiers CLASSIF be matched with regard to those classifiers
![]() which agree with
which agree with ![]() . This generates the match-set (M). From this
match-set
. This generates the match-set (M). From this
match-set ![]() will that classifier be selected which either has the highest reward value
(R) or -if there are more than one such classifiers- which has been randomly selected from the
set of highest valued rewards. From this selected classifier will then the action (A) be
selected and executed.
will that classifier be selected which either has the highest reward value
(R) or -if there are more than one such classifiers- which has been randomly selected from the
set of highest valued rewards. From this selected classifier will then the action (A) be
selected and executed.
This action ![]() as part of classifer
as part of classifer
![]() as
as ![]() generates a new perception
generates a new perception ![]() which
again can change the energy level and with this the vital state
which
again can change the energy level and with this the vital state ![]() . When the energy
difference
. When the energy
difference ![]() is positiv -signaling an increase in energy- then will this cause a
reward action (REW+) for all classifiers
is positiv -signaling an increase in energy- then will this cause a
reward action (REW+) for all classifiers
![]() of CLASSIF which have with
their actions preceeded the last action
of CLASSIF which have with
their actions preceeded the last action ![]() , written as (
, written as (
![]() ,
,
![]() ,
,
![]() :
:
Here arises the crucial question how the reward should be distributed over the
participating actions which can be understood as a sequence of actions
![]() with the last action
with the last action ![]() as that action which caused the
change of the internal states. The first action
as that action which caused the
change of the internal states. The first action ![]() is that action which is the first
action after the last reward. In a general sense one has to assume that all actions before
is that action which is the first
action after the last reward. In a general sense one has to assume that all actions before ![]() have somehow contributed to the final success. But how much did every single
action contribute?
have somehow contributed to the final success. But how much did every single
action contribute?
From the point of the acting system it is interesting to learn some kind of a statistic telling
the likelihood of success doing in a certain situation some action. Thus if action
![]() predes a successful acxtion
predes a successful acxtion ![]() more often than an action
more often than an action ![]() then this should
somehow to be encoded. Because we do not assume any kind of a sequence memory here (not
yet), we have to find an alternative mechanism.
then this should
somehow to be encoded. Because we do not assume any kind of a sequence memory here (not
yet), we have to find an alternative mechanism.
An alternative approach could be to cumulate amounts of reward saying that an action -independent of all other actions- has gained some amount of reward and therefore making this action preferrable. An experimental approach copuld be the following one where the success is partitioned proportionally:
As general formula:
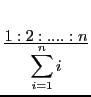
This allows in the long run some ordering: the actions with the highest scores are those leading directly to the goal and those with the lower scores are those which precede the higher scoring ones.
Such a kind of proportinal scoring implies that one has to assume some minimal action
memory
if ![]() .
.
Gerd Doeben-Henisch 2012-03-31
![\includegraphics[width=4.5in]{animat2_evaluation.eps}](img596.png)