
|
|
|
II-PRT REALZEITSYSTEME SS04
|
In den letzten Vorlesung wurde der Begriff der Zeit eingeführt, verschiedene Charakterisierungen von Systemen anhand des Zeitbegriffs, die Frage der Zuverlässigkeit, und ansatzweise auch schon das Problem der Planung der Behandlung von Ereignissen unter Beachtung von zeitlichen Vorgaben (Deadlines). Hauptgegenstand der nächsten Vorlesungen ist nun genau dies, die Konstruktion von Plänen und Algorithmen zur Vermeidung von Zeitkonflikten. Man nennt dies allgemein Scheduling (vom englischen Ausdruck 'schedule' mit den Bedeutungen 'Ablaufplan/ Fahrplan/ Flugplan, ...').
Will man Planungsalgorithmen zur Vermeidung von Zeitkonflikten modellieren, dann muss man zunächst klären, welches die 'Mitspieler' im Spiel sind, welche Eigenschaften haben diese, und wie lassen sich diese kombinieren.
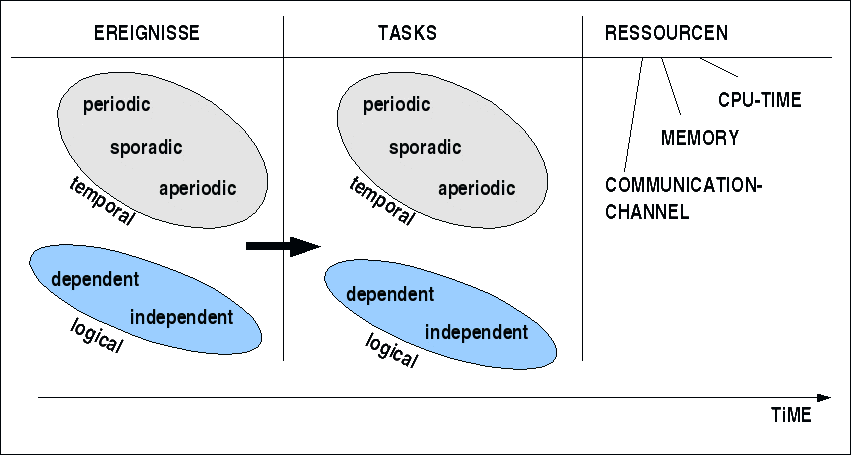
Basiselemente für Realzeitsysteme
Die (externen) Ereignisse bilden die Umgebung des Systems erweitert um die Dimension der Zeit, innerhalb deren sich Deadlines auszeichnen lassen. Die Menge der Tasks und Ressourcen repräsentieren das System, das auf die Ereignisse unter Berücksichtigung der Deadlines reagieren soll. Allerdings kann es auch in einem konmkreten Realzeit-System Ereignisse geben, interne Ereignisse, die durch irgendwelche speziellen Prozesse --z.B. Überlauf eines Timerbausteins-- ausgelöst werden. Strengenommen gehören diese internen Ereignisse auch zur 'Umgebung' des Systems insofern das System auf diese Ereignisse keinen direkten Einfluss nehmen kann. Diese Unterscheidung wollen wir zunächst beibehalten: Ereignisse gehören zur Umgebung!
Aus systemtheoretischer Sicht haben wir es bei RT-Systemen mit Input-Output-Systemen zu tun, deren Input durch Ereignisse und Zeitmarken einer externen Uhr gebildet wird; die Zeitmarken repräsentieren eine externe Zeitdimension. Ohne solchen externen Zeitmarken könnte man ein bestimmtes System S1 nicht mit einem anderen System S2 synchronisieren.
Ganz wichtig ist ferner, dass alle Operationen von RT-Systemen an endliche Ressourcen gebunden sind. Auf der Basis von Input und verfügbaren Ressourcen berechnet dann die Systemfunktion FS jeweils einen Output.
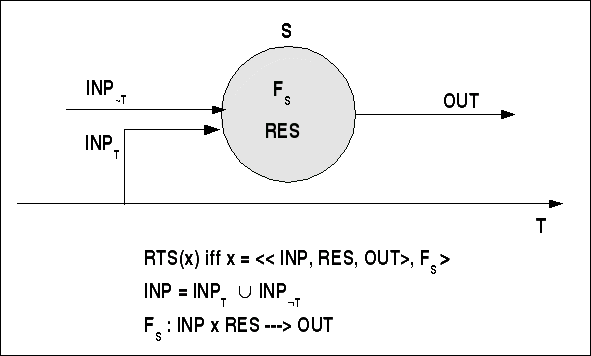
RT-Systeme als Systeme mit Zeit und Ressourcen
Die Einbeziehung von endlichen Ressourcen in die Modellierung ist hier wesentlich, da es gerade die konkrete Beschaffenheit dieser Ressourcen ist, die das Verhalten des Systems in der Zeit --also die Systemfunktion FS-- wesentlich bestimmen.
Die Ereignisse kann man nach ihrer 'Herkunft' charakterisieren oder nach dem zeitlichen Muster ihres Auftretens. Nach Herkunft kann man unterscheiden zwischen externen (ein Stimulus), internen (ein Interrupt) und zeitbedingten (ein Taktereignis). Nach dem zeitlichen Muster ihres Auftretens kann man unterscheiden periodische, sporadische oder aperiodische Ereignisse. Periodische Ereignisse sind solche, die nach bekannten, festen Zeitintervallen auftreten. Sporadische Ereignisse treten 'irgendwann' auf, man weiss nicht, wann, aber, wenn sie auftreten, dann vergeht eine bekannte definierte minimale Zeitspanne bis zum nächsten Auftreten. Aperiodische Ereignisse sind hinsichtlich ihres Verhaltens in der Zeit völlig unbestimmt; sie können zu beliebigen Zeitpunkten mit beliebigen Intervallen auftreten. Weitere Charakterisierung von Ereignissen ist möglich, z.B. eine Charakterisierung bzgl. der Abhängigkeit der Ereignisse untereinander. Weitere häufig vorkommende Unterscheidungen sind z.B. auch gebundene Ereignisse; dies sind solche, die entweder mit einer minimalen oder einen maximalen Zeit zwischen ihrem auftreten bschreibbar sind. Ferner gibt es noch die Unterscheidung gehäufte ('bursty') Ereignisse. Diese sind gekennzeichnet durch ein Häufungsintervall ('burst interval') und eine Häufungsgrösse ('burst size'); beide Grössen zusammen liefern die Häufungsdichte ('burst density'). Ein Beispiel wäre eine Anzahl von 50 Transaktionen innerhalb von 1 Sekunde, wobei das genaue Auftreten dieser Transaktionen innerhalb dieser Sekunde offen ist. Statt von aperiodischen Ereignissen kann man dann auch von ungebundenen Ereignissen sprechen; diese haben keinerlei Beschränkungen.
Die Ressourcen des Systems werden gebildet durch alle Betriebsmittel, die vom System in Anspruch genommen werden. Am wichtigsten sind hier natürlich die verfügbare CPU-Zeiten, die verfügbaren Speicher und Komunikationskanäle mit den daran geknüpften Transaktionszeiten. Zu beachten sind auch Latenzzeiten hervorgerufen z.B. durch Unterbrechungen ('interrupts'), Speicherzugriffe, komplexe Befehle (wie Divison), Sprünge und damit verbundene Umgruppierungen in der CPU-Pipeline) oder auch Umschaltzeiten durch Kontextwechsel). Welche Systemfunktion auch immer ausgeführt werden mag, die durch die Ressourcen vorgegebenen Eckwerten können nicht unterlaufen werden und müssen daher vollständig in der Analyse eines Realzeitsystems eingebracht werden.
Die Systemfunktion FS wird gebildet durch die Menge der Tasks, deren Verwaltung, sowie den Randbedingungen induziert durch die Eigenart der Ressourcen. Die Verwaltung der Tasks --meist Scheduling genannt-- hat darüber zu entscheiden, welcher Task bei welchem Ereignis welche Ressource zugeteilt bekommt. Dabei ist zu beachten, dass die Task-Verwaltung selbst auch Ressourcen benötigt! In einem schlecht aufgesetzten System kann die Task-Verwaltung u.U. mehr Ressourcen benötigen als die Tasks selbst (Es sei hier nochmals erinnert an den Begriff des WCAO := Worst Case Administrative Overhead aus der vorausgehenden Vorlesung).
Im Falle der Tasks sind zwei Unterscheidungen wichtig: ob ein Task T von einem Task T' abhängig ist oder nicht, sprich unabhängig ist, oder ob ein Task während seiner Ausführung unterbrochen werden darf --Prememption-- oder nicht.
Unter Berücksichtigung der hier genannten Eigenschaften wären also Systeme mit Systemfunktionen, die nur unabhängige Tasks zulassen, die nicht preemptiv sind (nicht unterbrochen werden dürfen), die 'theoretisch einfachsten' Systeme.
Auch im Bereich der Tasks ist die Unterscheidung in periodische, sporadische sowie aperiodische üblich. Die Bedeutung ist analog zur Menge der Ereignisse.
Für manche Analysen erweist es sich als hilfreich, wenn man den Begriff des 'Task' nochmals weiter herunterbricht auf das Konzept der Aktion als kleinstmöglichster Analyseeinheit. Eine Aktion selbst ändert laut Definition keine Ressourceneinstellung, wohl aber beginnen und enden Aktionen mit sogenannten Planungs-Punkten ('scheduling points'). Die Planungspunkte korrelieren mit Zeitpunkten, an denen Entscheidungen bzgl. Ressourcennutzung vorgenommen werden können (z.B. Änderung der Priorität, Start/Stopp von I/O-Aktivitäten, Synchronisierung mit anderen Aktionen).
Schliesslich muss man die Typen der Interaktion der Tasks/Aktionen festlegen. Mindestens zwei Typen erweisen sich als wichtig: in einer sequentiellen ('sequential') Ordnung folgen die Tasks einer nach dem anderen; in einer parallelen ('parallel') Ordnung können die Tasks zeitlich gleichzeitig auftreten. Formal kann man die Menge der Tasks und deren Anordnung als Graphen repräsentieren.
TGRAPH(g) iff t = < < K,O >, TU>
mit
K := Endliche Menge von Knoten ('nodes', 'vertices')
O = {s,p}; Ordnungstyp s := sequentiell, p := parallel
TU subset K x O x K; eine Taskunit besteht also aus zwei Tasks die entweder sequentiell oder parallel angeordnet sind.
Beispiele:
<t1,s,t2 > auch geschrieben als t1 --> t2
<t1,p,t2 > auch geschrieben als t1 || t2
Man kann dann Operatoren definieren, die solche Tasksunits dann zu kompletten Graphen 'zusammenbauen', z.B.:
A --> ( B || (C --> D) || ( E --> F --> G )) --> H
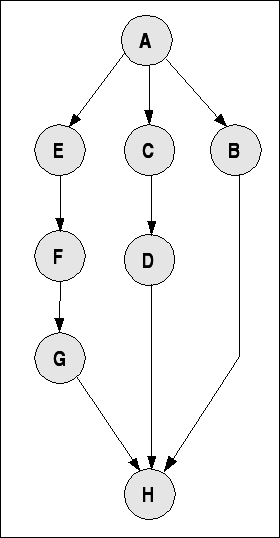
Einfacher Taskgraph
Da wir schon wissen, dass ein Task nicht nur eine rein 'logische' Grösse ist, sondern unterschiedlichste Ressourcen benötigt, die wiederum eine Auswirkung auf den Zeitbedarf haben, muss man den Taskgraphen mit zusätzlichen Informationen anreichern (siehe Bild):
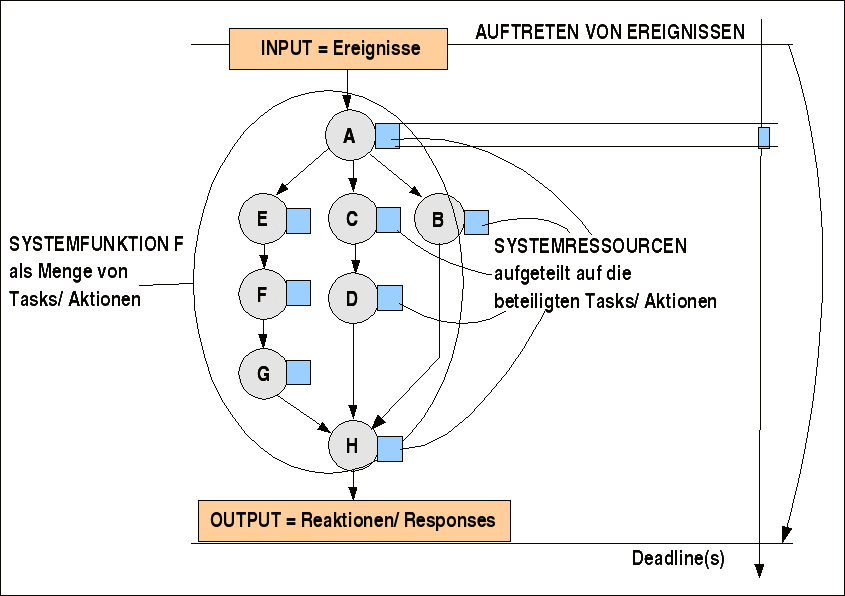
Angereicherter Taskgraph
Für jeden Task muss eine Reihe von Eigenschaften geklärt werden, die die Basis für die weitere Analyse bilden. Die wichtigsten Eigenschaften sind hier aufgeführt:
|
RESSOURCEN |
Welche Ressourcen ein Task benötigt, z.B. CPU, Datenobjekt, Device, Bus, LAN, anderes |
|
PRIORITÄT |
Prioritäten sind geordnete Werte, die bei der Zuteilung von Ressourcen benutzt werden, um Präferenzen zu realisieren. Z.B. (höchster Wert zuerst) Hardware, Kernel, very high, high, medium, low, very low, +. '+' wird benutzt, um anzuzeigen, dass die Priorität von einem vorausgehenden Task geerbt wird. |
|
NUTZUNGSZEIT |
Jene Zeit ('usage', 'time used'), für die ein Task eine Ressource benötigt, wenn er nicht konkurrieren muss. Falls die Ressource eine CPU ist, spricht man von Ausführungzeit ('execution time'). Gewöhnlich wird die 'worst-case' Zeit genommen; es gibt aber auch Fälle, wo eine durchschnittliche Zeit ('average time') nützlich ist. |
|
RESSOURCEN-ALLOKATIONS-POLICY |
Diese ist abhängig von der jeweiligen Ressource.
|
|
EXKLUSIVITÄT |
Kann der Task die Ressourcen alleine benutzen oder muss der Task die Ressourcen mit anderen Tasks teilen. |
|
WELCHER JITTER |
Man muss festlegen, welche Art von Jitter --falls überhaupt-- berücksichtigt werden soll (s.u.). |
Eine andere bewährte Darstellungsform ist die Tabelle. Sehr ausführliche Darstellungen findet man z.B. in dem exzellenten Hanbuch [Mark H.KLEIN et al. 1993:3-35ff]. Wir übernehmen für unsere Zwecke eine vereinfache Form, die bei [Mark H.KLEIN et al. 1993:3-40] 'technique table' heisst; wir nennen sie analog technische Tabelle
| EVENT ID (e) | RELEASE TIME (r) | ARRIVAL PERIOD (T) | TASK ID | EXECUTION TIME (C) | PRIORITY (P) | BLOCKING DELAYS (B) | DEADLINE (D) |
| e1 | r0 = 0 | 40 | a1 | 4 | v.high | 0 | 40 |
| e2 | r0 = 0 | 150 | a2 | 10 | high | 15 | 150 |
| e3 | r0 = 0 | 180 | a3 | 20 | medium | 0 | 180 |
| e4 | r0 = 0 | 250 | a4 | 10 | low | 5 | 250 |
| e5 | r0 = 0 | 300 | a5 | 80 | v.low | 0 | 300 |
Dabei kommt in dieser Tabelle noch der Begriff Blocking Delay (B) vor. Damit ist gemeint, dass ein abhängiger Task t --in der letzten Vorlesung auch komplexer Task genannt bzw. CTask-- bei seiner Ausführung auf die Beendigung anderer Tasks t' warten muss. Die Ausführungszeit dieser anderen Tasks t' blockiert den wartenden Task t. Davon zu unterscheiden ist die Wartezeit, die dadurch entsteht, dass in einem präemptiven System ein Task warten muss, weil ein anderer eine höhere Priorität hat.
Aus den zuvor geschilderten Rahmenbedingungen ergeben sich eine Reihe von fundamentalen Begriffe, die für die Beschreibung und Berechnung von Zeitverhältnissen wichtig sind.
Zuvor wurde schon der Begriff Jitter definiert. Neben dem Jitter jitterS, der eine aktuelle Eigenschaft eines Realzeitsystems S darstellt, muss man noch die Jittertoleranz jeS für ein System S berücksichtigen. Jittertolranz jeS repräsentiert eine Anforderung von der Problemstellung an das System. Sie sagt aus, welche Abweichung maximal zulässig ist, als es muss gelten
jitterS < jeS
Dabei wird zwischen einer absoluten und einer relativen Jittertoleranz unterschieden. Die relative Jittertoleranz bezieht sich nur auf den Zeitpunkt ein Task später, also
ti+1 = ti T + jeS
Die absolute Jittertoleranz bezieht sich auf alle Zeitpunkte seit der ersten Aktion, also
ti+1 = ( t1 + (i * T) + jeS )
Während ein relativer Jitter von z.B. 0.1 s nicht viel sein mag kann dieser aber nach 10 Aktionen schon zu 1 s kumulieren und sehr schnell das erlaubte Mass sprengen. Ein absoluter Jitter von 0.1 s für alle bisherigen Aktionen ist dagegen ein klarer Referenzpunkt.
Zu einem Ereignis ei gehört immer eine relative Deadline Di, das ist die höchste erlaubte Verzögerung bis zur Ausführung des zugehörigen Tasks. Ereignis ei zusammen mit der Deadline Di bilden ein Zeitfenster (t(ei),Di).
Jeder Task i hat eine spezifische Ausführungszeit ('execution time') ci. Die restliche Ausführungszeit zum Zeitpunkt t ist C(t) (0 < C(t) < C
Ein periodisches Ereignis ei hat eine Periode pi (oder auch Ti).
Mit der Auftretenszeit ('release time', request time', 'arrival time', 'ready times') ri eines Ereignisses ei ist der Zeitpunkt gemeint, an dem ein Ereignis einem System bekannt wird und einen zugehörigen Task anfordert. Wenn ri.0 die Auftretenszeit des Ereignisses ei zum 0-ten Zeitpunkt ist, dann gilt die Auftretenszeit vom k-ten sukzessiven Ereignis ist: ri.k = ri.0 + k*Ti
Neben der relativen Deadline Di eines Ereignisses ei gibt es auch die absolute Deadline di = ri + Di. Die restliche relative Deadline zum Zeitpunkt t ist D(t) = d -t.
Ein Task ist 'well formed' wenn gilt: 0 < C < D < T.

Taskmodell Symbole
Ausgehend von der absoluten Deadline di und der Ausführungszeit ci eines Tasks kann man die laxity li des Tasks berechnen bezogen auf den aktuellen Zeitpunkt: li = di - ci
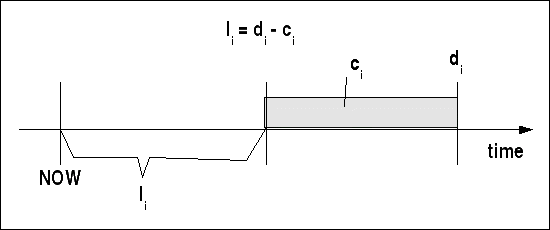
Laxity
Die restliche nominale Laxity L(t) berechnet sich mit L(t) = D(t) - C(t) oder L(t) = r+D-t-C(t) (siehe Beispiel mit LLF-Algorithmus unten).
Mit der Periode kann ein Offset verbunden sein, z.B. 3 msec offset nach der Periode. Ferner kann auch das durch das Ereignis verursachte Signal einen Jitter haben. Wird eine Nachricht zur Netzwerk-Queue gesendet, spricht man auch von einer Release time; zusammengenommen ergibt sich also die Formel (bei perfekter Zeitmessung):
Release timen= (n*period) + offset + jitter
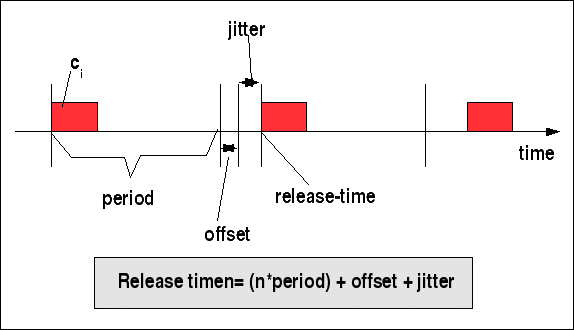
Periode
Wenn s die Startzeit eines Tasks ist und e die Endzeit, dann ist TR = e-s die Task-Antwortzeit.
Die Auslastung bzw. den Nutzungsgrad ('utilization') myi bezogen auf einen einzelnen Task i und eine CPU bekommt man durch myi = ci / Ti. Die Auslastung gibt an, zu wieviel Prozent ein Task i die Zeit bis zu seiner 'Wiederkehr' verbraucht. pi ist die Periode des Tasks.
Die totale Auslastung ('utilization') U(S,n) eines Systems S erhält man dann durch den Ausdruck
U(S,n) = SUM(i=1,n) ci/Ti
mit
n := Anzahl der verschiedenen Tasks (bzw. Aktionen). Es muss gelten U(S,n) < 1
Für den Prozessor Beladungsfaktor ('proessor load factor') gilt
ch(S,n) = SUM(i=1,n) ci/di
Für den restlichen Prozessor Beladungsfaktor gilt
CH(S,n,t) = SUM(i=1,n) Ci(t)/Di(t)
Im Fall von geteilten Ressourcen kann es passieren, dass ein Task tj einen Task ti blockiert. Daraus entsteht eine Verzögerungszeit ('blocking time') (B). Es soll Bi die gesamte Verzögerungszeit sein, die ein Task Task ti erfahren kann. Dann kann man die totale Verzögerungszeit B(S,n) eines Systems S berechnen durch den Ausdruck
B(S,n) = MAX(i=1,n) Bi/pi
mit
n := Anzahl der verschiedenen Tasks (bzw. Aktionen).
Planungsperiode ('scheduling period' or 'major cycle' or 'hyper peruid'): bei quasi unendlich lang laufenden Prozessen genügt es für die Planung, nur denjenigen Zeitabschnitt zu untersuchen, der sich ab einem bestimmten Zeitpunkt wiederholt. Diese Auswertungsperiode ('evaluation period', 'pseudo-period', 'scheduling period', 'schedule length', 'hyper period') beginnt (vgl. [COTTET et al 2002:16]) bei der frühesten Release-Zeit eines Ereignisses und erstreckt sich bis zum {Maximum entweder einer Releasezeit eines periodischen Ereignisses oder der Releasezeit eines aperiodischen Ereignisses + Deadline } plus 2* dem kleinsten gemeinsamen Vielfachen ('Least Common Multiple, LCM') der Perioden der periodischen Tasks.
MAX{ri.0, (rj.0 + Dj)} + 2 * LCM(Ti)
Nach diesen vorbereitenden Bemerkungen sollen nun einige wichtige Typen von Planungsalgorithmen vorgestellt werden. Eine Diskussion und zusätzliche Berechnungsformeln folgen im Anschluss.
Einen ersten Überblick gibt die folgende Tabelle.
Die Tabelle geht davon aus, dass entlang einer Zeitachse beginnend mit einem definierten Anfangswert zu jedem Zeitpunkt eine Menge von Tasks MT gegeben ist, die ausgeführt werden sollen (diese Menge kann leer sein).
Um zu entscheiden, welcher Task t aus MT ausgeführt werden soll benötigt man den Namen einer Regel, die angewendet werden soll. Bekannte Namen sind 'RM := Rate Monotonic'; 'ID := Inverse Deadlinbe oder DM := Deadline Monotonic'; 'EDF := Earliest Deadline First', 'LLF := Least Laxity First'.
Jede Regel muss festlegen, zu welchem Zeitpunkt (Point of Computation) der Kandidat t aus MT berechnet werden soll. Generelle Optionen sind z.B. 'zu jedem Zeitpunkt', 'nur wenn ein neues Ereignis auftritt', 'nur wenn ein Task beendet wurde'.
Ferner muss die Regel definieren, wie die Prioritäten ermittelt werden. Generelle Optionen sind z.B.: 'Prioritäten werden nach einem bestimmten Kriterium einmal fixiert ohne weitere Änderungen', 'Prioritäten werden nach einem bestimmten Kriterium dynamisch immer wieder neu ermittelt'.
Bekannte Kriterien orientieren sich z.B. an 'T := Periode', 'D := relative Deadline', 'd := absolute Deadline' und 'L := Laxity'.
|
Point of Computation |
Priorities |
Names |
|
|---|---|---|---|
|
Task Completion + Task Arrival |
fixed |
D = T |
RM |
|
D < T |
ID/DM |
||
|
Task Arrival |
dynamic |
d |
EDF |
|
Task Arival + Every Cycle |
L |
LLF |
|
|
L |
|||
Die allgemeine Situation, wie man eine Menge von Tasks nach einer Regel priorisiert und dann die Tasks nacheinander zur Ausführung bringt, lässt sich für den Fall von periodischen Tasks durch nachfolgenden Algorithmus angenähert beschreiben:
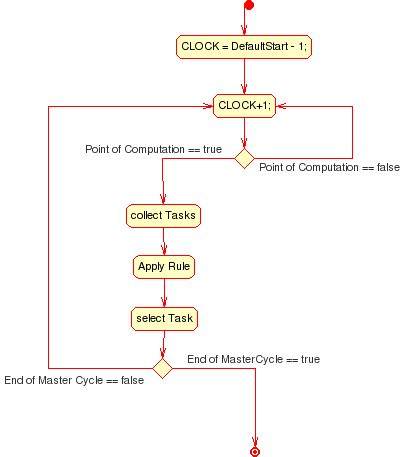
Basisalgorithmus für Scheduling
Man eröffnet eine Zeitachse mit einem definierten Anfangswert -1 und beginnt nachfolgende Zeitpunkte zu generieren. Für jeden Zeitpunkt muss man klären, ob die aktuelle Regel anwendbar ist oder nicht. Wenn nicht, geht man zum nächsten Zeitpunkt. Falls ja, wendet man die Regel auf alle aktuellen Tasks an und erzeugt eine geordnete Menge. Aus dieser geordneten Menge wählt man dann die Teilmenge mit der höchsten Priorität aus. Wenn diese Menge mehr als ein Element hat, wählt man ein Element per Zufall aus. Wird ein definierter Endzeitpunkt erreicht, wird der Algorithmus beendet, ansonsten läuft er weiter.
Im Folgenden werden jetzt wichtige Beispiele von Schedulingalgorithmen für periodische Tasks vorgestellt
Wie aus der Tabelle zu entnehmen, gilt für den RM-Planungs-Algorithmus, dass die Priorität P eines Tasks t aus der Menge der auszuführenden Tasks TM anhand der Periode T errechnet wird: 'je kürzer T, umso höher P'. Diese Berechnung kann auf unterschiedliche Weise durchgeführt werden: (i) ohne Präemption --dann wird nur dann neu berechnet, wenn ein Task t beendet wurde--, oder (ii) mit Präemption -- dann wird jedes Mal neu berechnet, wenn ein Task neu gestartet werden soll--. Im folgenden wird immer Präemption vorausgesetzt, sofern nicht anders vermerkt. Insofern sich die Periode während der Laufzeit nicht mehr ändert, kann man sich eine Neuberechnung der Prioritäten sparen und man kann direkt die einmal errechneten Prioritäten bei der Anordnung der Taskmenge TM benutzen. Insofern kann man hier auch von festen Prioritäten sprechen, da die Neuberechnung keine Veränderung bewirkt. Ferner ist zu beachten, dass im Falle des RM gilt: D = T.
|
Berechne einen Plan mit dem RM Algorithmus (Auftreten eines Ereignisses: Pfeil nach oben; deadline: Pfeil nach unten) |
|---|
|
- t1 (r0 = 0, C = 1, D = T = 3) -> 3 - t2 (r0 = 0, C = 1, D = T = 4) -> 2 - t3 (r0 = 0, C = 2, D = T = 6) -> 1 |
Der Inverse Deadline (ID) oder Deadline Monotonic (DM) unterscheidet sich von dem EDF dadurch, dass der Inverse Deadline Algorithmus statt mit den Perioden T mit den Deadlines D rechnet. Ansonsten verhält er sich aber auch wie der EDF. Allerdings gilt für ID, dass D < T ist!
Wie aus der Tabelle zu entnehmen, gilt für den EDF-Planungs-Algorithmus, dass die Priorität P eines Tasks t aus der Menge der auszuführenden Tasks TM anhand der asoluten Deadline d errechnet wird: 'je kürzer d, umso höher P'. Diese Berechnung wird einmal zu Beginn durchgeführt und dann jedesmal, wenn ein Task t neu auftritt. Da sich die Zuordnung der Prioritäten während der Laufzeit ändern kann, spricht man in diesem Fall auch von einer dynamischen Priorität. Im Falle des EDF gilt: D < T.
|
Berechne einen Plan mit dem EDF- Algorithmus (Auftreten eines Ereignisses: Pfeil nach oben; deadline: Pfeil nach unten) |
|---|
|
- t1 (r0 = 0, C = 1, D = 3, T = 3) - t2 (r0 = 0, C = 1, D = 4, T = 4) - t3 (r0 = 0, C = 2, D = 3, T = 6) |
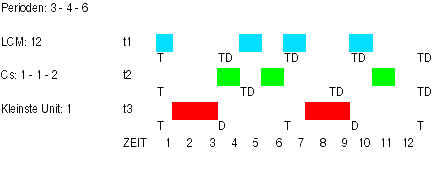
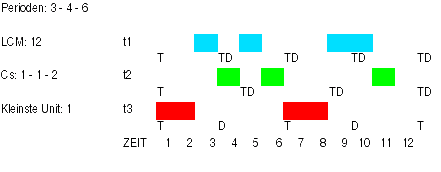
Wie aus der Tabelle zu entnehmen, gilt für den LLF-Planungs-Algorithmus, dass die Priorität P eines Tasks t aus der Menge der auszuführenden Tasks TM anhand der Laxity L errechnet wird: 'je kleiner L, umso höher P'. Diese Berechnung wird einmal zu Beginn durchgeführt und dann entweder, wenn ein Task t neu auftritt, oder zu jedem Zeitpunkt. Im ersten Fall ist der LLF mit dem EDF gleichwertig; im zweiten Fall kann er geringfügig besser hat, hat aber zusätzlich einen höheren Managementaufwand. Auch im Fall des EDF spricht man von einer dynamischen Priorität. Im Falle des LLF gilt: D < T.
|
Berechne einen Plan mit dem LLF- Algorithmus (Auftreten eines Ereignisses: Pfeil nach oben; deadline: Pfeil nach unten) |
|---|
|
Im folgenden Beispiel wird die relative Laxity immer bei Eintreffen eines neuen Tasks berechnet. |
|
Ausgehend
von der absoluten Deadline di und der Ausführungszeit
ci eines Tasks kann man die laxity li
des Tasks berechnen bezogen auf den aktuellen Zeitpunkt: li
= di - ci. |
|
- t1 (r0 = 0, C = 1, D = 3, T = 3) - t2 (r0 = 0, C = 1, D = 4, T = 4) - t3 (r0 = 0, C = 2, D = 3, T = 6) |
Allgemein gilt, dass das Planen von aperiodischen oder sporadischen Tasks nur sehr eingeschränkt möglich ist. Hier sei eine Situation geschildert, in der man eine feste Menge periodischer Tasks hat, die aber die CPU nicht vollständig belegen, d.h. es gibt immer wieder untätige Zeiten ('idle times') , zu denen die CPU nicht beschäftigt ist.
Die Grundidee eines hybriden Taskalgorithmus besteht nun darin, relativ zu den bekannten Zeiten der Untätigkeit der CPU, vorkommende aperiodische Tasks dynamisch einzuordnen.
Eine 'natürliche' Situation für solch ein Vorgehen ist dort gegeben, wo man aufgrund von historischen Daten eine gute Abschätzung der empirischen Maxima von bestimmten Arten von sporadischen und aperiodischen Tasks relativ zu deren Auftretenszeiten besitzt (z.B. Anzahl von Supportanrufen bei einer Hotline bezogen auf Tageszeiten). In diesem Fall könnte man die periodischen Tasks so planen, dass man hinreichend grosse freie CPU-Zeiten von vornherein einplant, so dass die Wahrscheinlichkeit, dass man auftretende periodische Tasks bedienen kann, hinreichend gross ist.
Hier ein einfaches Beispiel für eine hybride Taskmenge:
Gegeben seien die folgenden drei periodischen Tasks {t1, t2, t3}:
- t1 (r0 = 0, C = 5, D = 25, T = 30)
- t2 (r0 = 0, C = 10, D = 40, T = 50)
- t3 (r0 = 0, C = 20, D = 55, T = 75)
-Hier einige aperiodische Tasks
- t4 (r= 40, C = 10, D = 25, T = 15)
- t5 (r= 70, C = 15, D = 40, T = 35)
- t6 (r= 100, C = 20, D = 55, T = 40)
- t7 (r= 105, C = 5, D = 25, T = 25)
- t8 (r=12 0, C = 5, D = 40, T = 15)
|
Ein Plan mit Hilfe des EDF-Algorithmus. |

|
Zeiten während deren der Prozessor untätig ('idle') ist. |
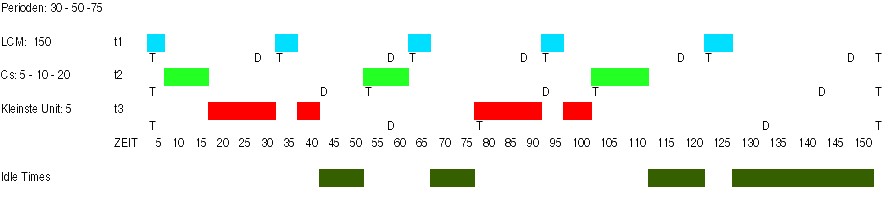
|
Aperiodische Tasks relativ zu den verfügbaren freien Zeiten des Prozessors |

Bislang haben wir immer eine Menge A unabhängiger Tasks betrachtet, für die nur die Ressource CPU-Zeit einer einzigen CPU berücksichtigt wurde. Ferner haben wir Präemption angenommen. Unter diesen Voraussetzungen hatten wir die Algorithmen RM, DM, EDF und LLF angewendet.
In diesem Abschnitt sei angenommen, dass zusätzlich zur Menge A von Tasks noch eine Menge P von Präferenzen existiert, also
| < A, P > | |
| A | := Menge der Tasks |
| P | := Menge der Präferenzen |
| P C A x A | |
Beispiel:
| <A1 , P1 > | |
| A1 | = {t1,t2,t3,t4} |
| P1 | = {(t1,t2), (t1,t3), (t2,t4), (t3,t4)} |
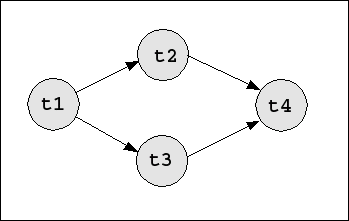
Beispiel mit Tasks unter Präferenzen
Will man auch in einem solchen Fall die bisherigen Planungs-Algorithmen benutzen, dann muss vor der Anwendung sicherstellen, dass die geforderten Präferenzen in die Voraussetzungen so 'eingearbeitet' wurden, dass die Anwendung der Algorithmen diese Präferenzen korrekt berücksichtigt. Wie soll dies gehen?
| Algorithmen mit Präferenzen | |||
|---|---|---|---|
| RM | DM | EDF | |
| Allgemeine Voraussetzungen | D = T WENN Ti < Tj DANN Pi > Pj |
D < T WENN Di < Dj DANN Pi > Pj |
d <= T WENN di < dj DANN Pi > Pj |
| Spezielle Voraussetzungen | Ti = Tj WENN ti ---> tj DANN r*j >= Max(rj,r*i) |
Ti = Tj WENN ti ---> tj DANN (i) r*j >= Max(rj,r*i) (ii) D*j >= Max(Dj,D*i) |
Ti = Tj WENN ti ---> tj DANN (i) r*j >= Max((r*i + Ci), ,rj) (ii) d*i >= Min((d*j - Cj),di) |
Betrachten wir dazu einige Beispiele.
| Technische Tabelle für RM-Beispiel | |||||
|---|---|---|---|---|---|
| Ereignis | r | C | D | T | P |
| e1 | 0 | 1 | 5 | ||
| e2 | 0 | 1 | 5 | ||
| e3 | 0 | 1 | 5 | ||
| e4 | 0 | 1 | 5 |
Würde man in diesem Beispiel nur die allgemeinen Voraussetzungen für RM annehmen, dann hätten alle Ereignisse die gleiche Priorität, da sie die gleiche Periode T = 5 besitzen. Dami waere es z.B. möglich, dass der Task zu Ereignis e4 vor (!!!) dem Task zu Ereignis e1 ausgeführt würde. Dies stände im Konflikt mit den angenommenen Präferenzen. Man kann daraus ersehen, dass die allgemeinen Voraussetzungen durch zusätzliche spezielle Voraussetzungen zu erweitern sind. Die einfachste Möglichkeit besteht darin, dass man die Prioritäten so setzt, dass sie die Präferenzforderungen erfüllen. Da alle Perioden als gleich angenommen werden, besteht freie Wahl bzgl. der Prioritäten. Daraus kann sich folgende Tabelle ergeben:
| Technische Tabelle für RM-Beispiel mit festen Prioritäten | |||||
|---|---|---|---|---|---|
| Ereignis | r | C | D | T | P |
| e1 | 0 | 1 | 5 | 4 | |
| e2 | 0 | 1 | 5 | 3 | |
| e3 | 0 | 1 | 5 | 2 | |
| e4 | 0 | 1 | 5 | 1 |
Im Falle von DM werden die Prioritäten nach den relativen Deadlines D vergeben.
| Technische Tabelle für DM-Beispiel | |||||
|---|---|---|---|---|---|
| Ereignis | r | C | D | T | P |
| e1 | 0 | 1 | 4 | 5 | |
| e2 | 0 | 1 | 4 | 5 | |
| e3 | 0 | 1 | 4 | 5 | |
| e4 | 0 | 1 | 4 | 5 |
Im Beispiel sind die Deadlines für alle Tasks die gleichen, also könnte laut DM task t4 vor task t1 ausgeführt werden, im Widerspruch zur Präferenz. Die einfachste Möglichkeit wäre hier wieder, die Prioritäten so festzulegen, dass sie mit den Präferenzen übereinstimmen, also:
| Technische Tabelle für DM-Beispiel mit Prioritäten | |||||
|---|---|---|---|---|---|
| Ereignis | r | C | D | T | P |
| e1 | 0 | 1 | 4 | 5 | 4 |
| e2 | 0 | 1 | 4 | 5 | 3 |
| e3 | 0 | 1 | 4 | 5 | 2 |
| e4 | 0 | 1 | 4 | 5 | 1 |
Im Falle von EDF werden die Prioritäten nach der absoluten Deadline d vergeben. Wenn ri.k die Auftretenszeit ('release time') eines Ereignisses ei nach k-vielen Zeiteinheiten ist, dann ist die absolute Deadline di = ri.k + Di. Mit k = 3 würde für e3 gelten: r3.0 + 3 * T3 + D3 = 0 + (3 * 5) + 4 = 19.
| Technische Tabelle für EDF-Beispiel | |||||
|---|---|---|---|---|---|
| Ereignis | r | C | D | T | P |
| e1 | 0 | 1 | 4 | 5 | |
| e2 | 0 | 1 | 4 | 5 | |
| e3 | 0 | 1 | 4 | 5 | |
| e4 | 0 | 1 | 4 | 5 |
Aufgrund der Gleichheit aller Werte wären die Prioritäten auch alle gleich. Da man im Falle von EDF aber nicht wie bei RM und DM Prioritäten einmalig fest vergeben kann, muss man die Parameter so anpassen, dass die jeweils neue --dynamische !-- Berechnung genau die Prioritäten liefert, die die Präferenzen verlangen. Dies geht nur so, dass man die Werte der Tabelle einmalig so abändert, dass die dynamische Berechnung immer wieder die richtigen Werte liefert.
Die dynamisch zu ermittelnden Prioritäten sind im Falle von EDF abhängig von der absoluten Deadline d; d wiederum ist abhängig von der Auftretenszeit r und der relativen Deadline D. Da D festliegt, bleibt nur die Möglichkeit, die Auftretenszeit r zu modifizieren. Ändert man die Auftretenszeit r entsprechend den Präferenzen ab, so ergibt sich z.B.:
| Technische Tabelle für EDF-Beispiel mit modifizierten Auftretenszeiten | |||||
|---|---|---|---|---|---|
| Ereignis | r0 | C | D | T | P |
| e1 | 0 | 1 | 4 | 5 | |
| e2 | 1 | 1 | 4 | 5 | |
| e3 | 2 | 1 | 4 | 5 | |
| e4 | 3 | 1 | 4 | 5 |
Damit kann man EDF anwenden und die Präferenzen werden erfüllt.
Bisher wurde gezeigt, wie man mit Hilfe von Diagrammen die Planbarkeit einer Ereignis-Taskmenge feststellen und darstellen kann. Bei grösseren Taskmengen bietet sich als eine erste Orientierung auch eine Abschätzung der Planbarkeit mit Hilfe von Näherungsformeln an.
Anhand der vorausgehenden Beispiele sollen hier daher einige Abschätzungformeln vorgestellt werden. Für eine ausführlichere Darstellung sei auf das immer noch sehr hilfreiche Buch [KLEIN et al 1996] verwiesen.
Die Grundidee bei der Abschätzung der Planbarkeit einer Taskmenge ist die Klärung, ob der Bedarf an CPU-Zeit die kleinste obere Schranke der machbaren Auslastung nicht überschreitet. Das Problem besteht darin, die Auslastungszeiten in Beziehung zu setzen zu den verfügbaren Deadlines = Perioden. Für den RM-Algorithmus (Herleitung siehe bei [COTTET 2002:27ff]) gilt als hinreichende Bedingng der Planbarkeit die Formel:
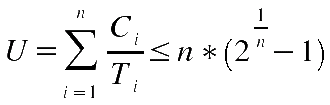
Ausserdem konnte bewiessen werden, dass der RM-Algorithmus optimal ist. Dies bedeutet, dass es keinen anderen Algorithmus im Bereich feste Prioritäten mit D = T gibt, der besser als RM ist (vgl. [COTTET 2002:24ff]). Die Optimalität kann auch für den DM-Algorithmus bewiessen werden für die Klasse der Algorithmen mit festen Prioritäten und D < T. Die formel für die hinreichende Bedingng der Planbarkeit lautet in diesem Fall:
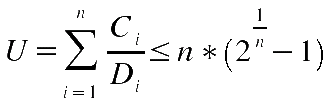
Hier ist anzumerken, dass eine negative Abschätzung nicht ausschliesst, dass konkrete Anordnungen dennoch möglich sind. Desgleichen --siehe nachfolgendes Beispiel-- kann es sein, dass die Formel sagt, dass eine Taskmenge nicht planbar sei und dass diese dann doch planbar ist.
| RM-Algorithmus | C | D | T | P | C_i/T_i | SUM | N | n*(2^1/n - 1) |
| - t1 (r0 = 0, C = 1, D = T = 3) -> 3 | 1 | 3 | 3 | 0,33 | 0,92 | 3 | 0,78 | |
| - t2 (r0 = 0, C = 1, D = T = 4) -> 2 | 1 | 4 | 2 | 0,25 | ||||
| - t3 (r0 = 0, C = 2, D = T = 6) -> 1 | 2 | 6 | 1 | 0,33 |
Der RM-Algorithmus benutzt die absolute Deadline zur Bestimmung der Priorirär. Dies geschieht jedesmal, wenn ein Task neu ankommt.
Im Fall des EDF-Algorithmus kann die Optimalität nur insofern nachgewiessen werden, dass der EDF-Algorithmus eine Lösung findet, sofern es sie gibt.
Eine notwendige und hinreichende Bedingung der Planbarkeit gibt es allerdings nur für den Fall, dass D = T; lässt man aber zu, dass D < T, dann gibt es nur eine notwendige Bedingung:
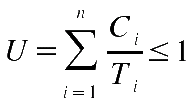
Angewendet auf das vorausgehende Beispiel mit dem EDF-Algorithmus erhellt man als notwendiges kriterium:
| EDF-Algorithmus | C | D | T | P | C_i/T_i | SUM | 1 | |
| - t1 (r0 = 0, C = 1, D = 3, T = 3) | 1 | 3 | 3 | 0,33 | 0,92 | 1 | ||
| - t2 (r0 = 0, C = 1, D = 4, T = 4) | 1 | 4 | 4 | 0,25 | ||||
| - t3 (r0 = 0, C = 2, D = 3, T = 6) | 2 | 3 | 6 | 0,33 |
Ein hinreichende Bedingung gibt es für die Planbarkeit von hybriden Taskmengen mit der Formel:
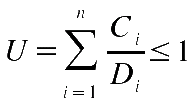
Angewendet auf das vorausgehende Beispiel sieht man, dass die Formel sagt, dass diese Menge nicht planbar sei; in der Tat ist einer der aperiodischen Tasks nicht planbar.
| EDF-Algorithmus (hybrid) | C | D | T | P | C_i/D_i | SUM | 1 | |
| - t1 (r0 = 0, C = 5, D = 25, T = 30) | 5 | 25 | 30 | 0,2 | 2,28 | 1 | ||
| - t2 (r0 = 0, C = 10, D = 40, T = 50) | 10 | 40 | 50 | 0,25 | ||||
| - t3 (r0 = 0, C = 20, D = 55, T = 75) | 20 | 55 | 75 | 0,36 | ||||
| - t4 (r= 40, C = 10, D = 25, T = 15) | 10 | 25 | 15 | 0,4 | ||||
| - t5 (r= 70, C = 15, D = 40, T = 35) | 15 | 40 | 35 | 0,38 | ||||
| - t6 (r= 100, C = 20, D = 55, T = 40) | 20 | 55 | 40 | 0,36 | ||||
| - t7 (r= 105, C = 5, D = 25, T = 25) | 5 | 25 | 25 | 0,2 | ||||
| - t8 (r=12 0, C = 5, D = 40, T = 15) | 5 | 40 | 15 | 0,13 |
Der LLF-Algorithmus ordnet die Prioritäten anhand der relativen Laxity zu, wobei D <.
Für diese Klasse von Algorithmen ist LLF optimal. Nimmt man wie im Fall von EDF an, dass die Priorität nur bei Ankunft eines neuen Tasks berechnet wird, dann kann die Planbarkeit garantiert werden mit der Formel
Würde man im Falle des LLF-Algorithmus die relative Laxity für jeden Zeitpunkt messen, dann würde sich damit zwar die 'Feinheit' der Ausnutzung verbessern, aber zugleich würde auch der Verwaltungsaufwand erheblich ansteigen.
Wie schon beim EDF-Algorithmus festgestellt, gibt es --unter Voraussetzung von EDF-- eine hinreichende Bedingung für die Planbarkeit von hybriden Taskmengen mit der Formel:
Der nächste Planbarkeitstest hat veränderte Voraussetzungen: (i) die Deadlines können kürzer sein als die Periode und (ii) die Prioritäten sind nicht monoton an der Länge der Deadline fixiert und (iii) es wird die Planbarkeit nur für einzelne Ereignisse ermittelt.
Als Beispielmenge dient die folgende Tabelle:
| EVENT ID (e) | ARRIVAL PERIOD (T) | ACTION ID | EXECUTION TIME (C) | PRIORITY (P) | BLOCKING DELAYS (B) | DEADLINE (D) |
| e1 | 40 | a1 | 4 | v.high | 0 | 10 |
| e2 | 300 | a2 | 80 | high | 0 | 300 |
| e3 | 180 | a3 | 20 | medium | 0 | 140 |
| e4 | 250 | a4 | 10 | low | 5 | 150 |
| e5 | 150 | a5 | 10 | v.low | 0 | 150 |
Die Berechnung der Planbarkeit eines einzelnen Ereignisses in solch einem Kontext erfolgt nach folgenden Schritten:
Es soll geprüft werden, ob Ereignis ei planbar ist.
Identfiziere eine Menge (H) von Ereignissen, deren Priorität höher oder gleich der Priorität Pi von ei sind. Teile dann die Menge (H) auf in zwei Mengen (H1) und (Hn). (H1) enthält solche Ereignisse, deren Perioden T grösser oder gleich der Deadline Di von ei sind. (Hn) soll solche Ereignisse enthalten, deren Perioden T kleiner als die Deadline Di von ei sind.
Berechne die totale effektive Nutzungszeit fi von Ereignis ei. Diese totale Nutzungszeit setzt sich aus zwei Bestandteilen zusammen: (i) die totale Nutzungszeit der Ereignisse in (Hn), sowie (ii) die Ausführungszeit von ei plus Verspätungszeiten durch Blockaden plus Präemptionszeiten verursacht durch Ereignisse aus (H1), alles dividiert durch die Periode von ei:
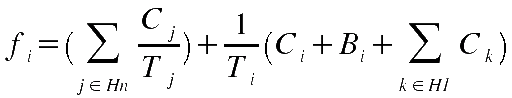
Berechne die Nutzbarkeitsgrenze U(n,Dti) mit n = Anzahl Elemente in (Hn) + 1 sowie:
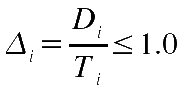
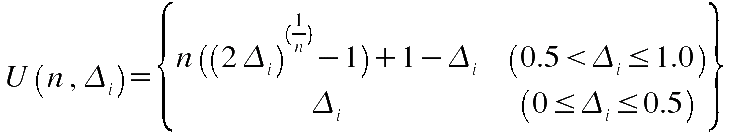
Vergleiche die effektive totale Nutzungszeit von ei mit der oberen Schranke:
![]()
Falls fi kleiner oder gleich der Grenze ist, dann kann dieses Ereignis seine Deadline einhalten.
Angewendet auf die vorausgehende Tabelle ergibt dies die folgenden Werte:
| EVENT ID (e) | ARRIVAL PERIOD (T) | ACTION ID | EXECUTION TIME (C) | PRIORITY (P) | BLOCKING DELAYS (B) | DEADLINE (D) |
| e1 | 40 | a1 | 4 | v.high | 0 | 10 |
| e2 | 300 | a2 | 80 | high | 0 | 300 |
| e3 | 180 | a3 | 20 | medium | 0 | 140 |
| e4 | 250 | a4 | 10 | low | 5 | 150 |
| e5 | 150 | a5 | 10 | v.low | 0 | 150 |
| H(e4) = | {e1,e2,e3} | |||||
| H1 = | {e2,e3} | |||||
| Hn = | {e1} | |||||
| c4/t4 = | 0,1 | |||||
| 1/t4 = | 0,0040 | |||||
| Ci + Bi + SUM(k in (H1))Ck = | 115 | |||||
| fi = | 0,56 | |||||
| n = | 2 | |||||
| Dti = Di/Ti = | 0,6 | |||||
| n*((2*Dti)^1/n -1) +1 - Dti = | 0,59 | |||||
| fi < U(n,Dti) = | TRUE |
Welche Komponenten bilden die Basiselemente eines Realzeitsystems?
Welcher Art Input kennzeichnet Realzeitsysteme?
Was haben Tasks mit Ressourcen zu tun?
Wie kann man Ereignisse nach Art ihrer Herkunft charakterisieren?
Was unterscheidet periodische Ereignisse von spontanen oder aperiodischen Ereignissen?
Was versteht man unter gehäuften Ereignissen?
Welche Art von Ressourcen müssen typischerweise bei Realzeitsystemen berücksichtigt werden?
Aus welchen Bestandteilen setzt sich die Systemfunktion zusammen?
Was unterscheidet abhängige von unabhängigen Tasks?
Was bedeutet es, dass ein System präemptiv ist?
Was ist der Unterschied zwischen einem Ereignis und einem Task?
Was ist damit gemeint, dass ein Task periodisch ist?
Wie verhalten sich Aktionen zu Tasks?
Angenommen, die Buchstaben 'A' - 'H' repräsentieren Tasks, was bedeutet dann die folgende Schreibweise: A --> ( B || (C --> D) || ( E --> F --> G )) --> H?
Was ist eine technishe Tabelle? Welche Komponenten enthält sie? Erklären sie die Funktion der einzelnen Komponenten.
Was versteht man unter einem Jitter, unter der Jitter-Toleranz und der relativen und der absoluten Jitter-Toleranz?
Wie unterscheidet sich die relative von der absoluten Deadline? Inwiefern kann man mit einer Deadline eine Zeitfenster definieren?
Was unterscheidet die restliche Ausführungszeit eines Tasks von seiner Ausführungszeit?
Was versteht man unter der Periode eines Ereignisses?
Wie berechnet man die Auftretenszeit des k-ten Ereignisses, wenn die Periode des Ereignisses T ist?
Wie berechnet man die absolute Deadline des k-ten Auftretens eines Ereignisses?
Unter welchen Bedingungen sagt man, dass ein Task wohlgeformt ist?
Was ist die totale Auslastung ('utilization') U(S,n) eines Systems S und wie berechnet man Sie?
Was unterscheidet den Prozessor Beladungsfaktor ('proessor load factor') von der totalen Auslastung eines Systems S ?
Was ist die die totale Verzögerungszeit B(S,n) eines Systems S und wie berechnet man sie?
Wofür benötigt man das kleinsten gemeinsamen Vielfachen (KGV) ('Least Common Multiple (LCM)') einer Taskmenge?
Welche Aufgabe erfüllt ein Planungsalgorithmus? Welche Algorithmen kennen Sie?
Auf welche Weise kann man einem Task in einer Taskmenge eine Priorität zuordnen?
Wodurch ist der RM-Algorithmus charakterisiert?
Wodurch ist der DM-Algorithmus charakterisiert?
Wodurch ist der EDF-Algorithmus charakterisiert?
Wodurch ist der LLF-Algorithmus charakterisiert?
Können sie ein Beispiel für das Management einer hybriden Taskmenge geben?
Was bedeutet es, wenn man sagen kann, dass ein Algorithmus optimal in seiner Klasse ist?
Was ist der Unterschied zwischen einem notwendigen und einem hinreichenden Kriterium bezüglich der Planbarkeit einer Taskmenge?
Welche Formeln für notwendige und hinreichende Kriterien für die Abschätzung der Planbrkeit von Taskmengen kennen Sie?
Welches Verfahren ur Planbarkeit eines einzelnen Ereignisses kennen Sie?