|
|
I-THINF WS 0203 - Vorlesung mit Übung
|
Die Beschäftigung mit dem Konzept der Turingmaschine und dann dem der universellen Turingmaschine versetzt uns in die Lage, ein Thema grundsätzlich abzuhandeln, das zwar von Anbeginn der Informatik immer im Kontext der Informatik genannt wurde, aber bis heute von vielen immer noch als ein Randthema angesehen wird, nämlich die frage intelligenter Computer bzw. intelligenter Systeme. Andere äquivalente Begriffe wären Computational Intelligence oder Computational Semiotic Systems. Glaubt man dem Bericht IT2006 der Bundesregierung, der von namhaften Experten aus Forschung und Wirtschaft erstellt worden ist, dann gewinnt das Thema intelligente Systeme aufgrund der wachsenden Anwendungsanforderungen eine immer grössere strategische Bedeutung. Auf Dauer kann die Informationstechnologie den wachsenden Anforderungen der zu lösenden komlexen aufgaben ineins mit den steigenden Anforderungen an die Mensch-Maschine-Interaktion (MMI) (engl. 'human computer interaction' (HCI)) nur dann gerecht werden, wenn 'auf irgendeine Weise' das Intelligenzpotential von Maschinen verstärkt wird. Und dass die Frage von Computational Intelligence kein bloss theoretischge Frage mehr ist, sondern den Bereich des konkreten Engineerings soweit durchdrungen hat, dass das konkrete Messen von künstlicher Intelligenz zu einem drängenden Thema geworden ist, das zeigt u.a. eine Konferenz wie 'Measuring Performance and Intelligence of Intelligent Systems' Aug. 2000, zu der sich führende Experten im NIST (National Institut of Standards and Technologies der USA) versammelt hatten.
Die heutige Vorlesung soll zeigen, warum die theoretische Informatik die zentrale theoretische Disziplin ist, in der das Konzept der Computerintelligenz (engl. 'computational intelligence') originär eingeführt und entwickelt wird. Zugleich wird deutlich werden, dass das Thema formale Sprachen/ formale Grammatiken ein Teilthema des umfassenderen Themas ist.
Als wissenschaftstheoretische Ausgangslage wird folgendes Szenario angenommen (siehe Bild): die Diskussion über Computerintelligenz wird geführt im Gegenüber zu den Disziplinen Psychologie, Neurobiologie und Neuropsychologie. Historisch ist die Psychologie die erste Wissenschaft, die das Verhalten des Menschen untersucht hat und versucht hat, auf dieser Basis Erkenntnisse über die zugrundeliegenden Strukturen zu gewinnen. Die Rekonstruktion der postulierten zugrundeliegenden Strukturen auf der Basis des Verhaltens ist bis heute kaum von Erfolg gekrönt; sowohl das zu analysierende Verhalten wie auch die zugrundeliegenden Strukturen sind einfach zu komplex, um sie mit den verfügbaren psychologischen Messmethoden und formalen Modellen befriedigend rekonstruieren zu können.
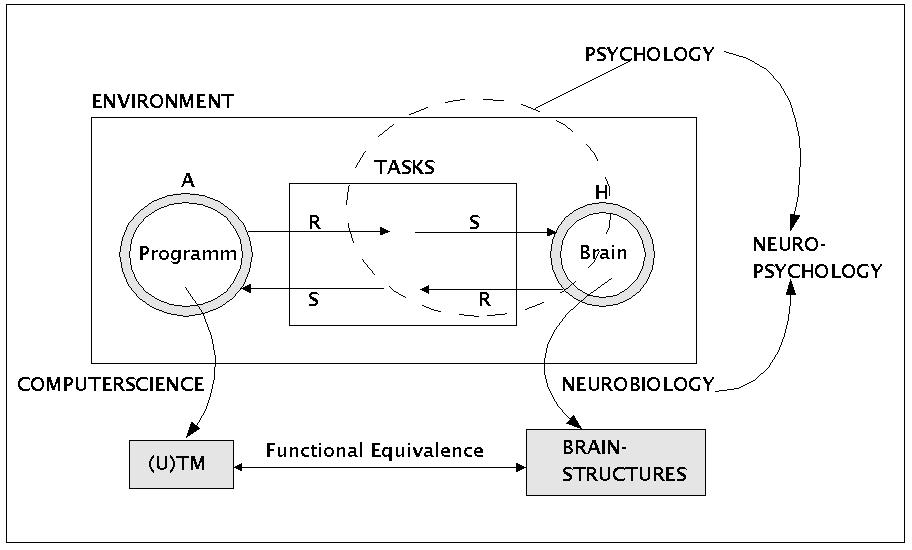
Automat A und Human H
In diesem Kontext gewinnt die Neurobiologie eine immer grössere Bedeutung. Mit der Verbesserung der Messmethoden gelingt es mehr und mehr, erste Erkenntnisse über den konkreten Aufbau und die Funktionsweise des Nervensystems -und damit des Gehirns- zu sammeln und in ersten formalen Modellen zu organisieren.
Die Erfolge der Neurobiologie eröffnen auch der Psychologie im Rahmen der Neuropsychologie neue Perspektiven; erstmalig in der Geschichte der Psychologie wird es jetzt möglich, das Zusammenspiel von Verhalten und zugrundeliegender Struktur durch Rückgriff auf Erkenntnisse der Neurobiologie mit harten empirischen Strukturdaten zu untermauern. Allerdings ergeben sich aus den noch existierenden Grenzen der neurobiologischen Messmethoden noch starke Bschränkungen in der Möglichkeit mehr als 5 neuronale Zellen im Detail und gleichzeitig im Rahmen eines 'ungestörten' Funktionszusammenhanges untersuchen zu können. Die existierenden bildgebenden Verfahren können nur als erste, noch sehr grobe Annäherung an das tatsächliche Geschehen in grösseren Zellverbänden angesehen werden.
Aus Sicht der Informatik (engl. 'Computerscience') gibt es mindestens zwei natürliche Anknüpfungspunkte, um sich mit dem Forschungsszenario zu vergleichen, das markiert ist durch Psychologie, Neurobiologie und Neuropsychologie. Zum einen kann die Informatik ähnlich wie die Psychologie das Verhalten ihrer Automaten (A) relativ zu definierten Aufgaben (engl. 'tasks') untersuchen. Dadurch ergibt sich die Möglichkeit, die Leistung von Automaten gegenüber dem Verhalten von Menschen ('humans' (H)) zu evaluieren. Zum anderen kann die Informatik aber auch formale Modelle von Gehirnstrukturen, sofern die Neurobiologie solche produziert, mit der Leistungsfähigkeit von Automaten, hier speziell natürlich der universellen Turingmaschine, zu vergleichen. Erste Überlegungen legen die These nahe, dass das menschliche Gehirn (und damit alle ähnlichen Gehirne) mit einer universellen Turingmaschine funktional äquivalent ist.
Der soeben eingeführte wissenschaftstheoretische Kontext gibt nun die Möglichkeit, den Bgriff der Intelligenz vorläufig zu situieren. Historisch wurde der wissenschaftliche Begriff der Intelligenz zuerst im Rahmen der Psychologie eingeführt. Zu Beginn des 20.Jahrhunderts begann die Pychologie damit, das Verhalten von Menschen relativ zu definierten Aufgaben und relativ zu experimentell definierten Eigenschaften zu messen und zu vergleichen. Aufgrund der Natur des komplexen menschlichen Verhaltens in nicht weniger komplexen Umgebungen war und ist der Intelligenzbegriff bis heute ein notorisch vager Begriff und immer nur soweit mit fassbaren Inhalten verbunden, insoweit man die jeweils unterstellten Aufgabenkataloge und Testbatterien berücksichtigt.
Der verhaltensbasierte psychologische Intelligenzbegriff ist grundsätzlich nicht an eine bestimmte zugrundeliegende Struktur gebunden. Methodisch ist es also denkbar, dass es eine Vielzahl von ausführenden Strukturen gibt, die ein ähnliches oder sogar identisches Verhaltensprofil in den definierten Aufgaben zeigen. Von daher kann man diesen Intelligenzbegriff sehr wohl auch dazu benutzen, um das Verhalten von Maschinen relativ zu den benutzten Testmethoden als mehr oder weniger 'intelligent' zu bezeichnen. Genauer müsste man natürlich sagen, dass der verhaltensbasierte psychologische Intelligenzbegriff kein eindeutiger Begriff ist, sondern eher eine ganze Familie von ähnlichen Begriffen umfasst, die sich aufgrund der verwendeten Aufgabenkataloge und Testverfahren mehr oder weniger unterscheiden.
Bewegt man sich also im Rahmen des verhaltensbasierten psychologischen Intelligenzbegriffs, dann kann man methodisch sehr wohl den Begriff von intelligenten Maschinen bzw. von Computerintelligenz begründen. In diesem Rahmen ist die Informatik auch nicht genötigt, die von ihnen benutzten Strukturen, die ein verhaltenstheoretisch begründetes Reden von intelligentem Verhalten ermöglich, biologisch zu motivieren; jede Struktur, die ein verhaltensdefinierte Intelligenz ermöglicht, lässt sich dann als intelligente Struktur qualifizieren.
Mit der fortschreitenden Entwicklung in der Neurobiologie und der Neuropsychologie, durch die mehr und mehr Erkenntnisse über die beim Menschen wirkenden zugrundeliegnden Strukturen zugänglich werden, wird es allerdings möglich, den rein verhaltenstheortisch motivierten Intelligenzbegriff zunehmend auch mit bestimmten Leistungsstrukturen, nämlich dem biologischen Nervensystem, zu korrelieren. Für die Informatik besteht kein Zwang, diese neuen Erkenntnisse über die konkreten biologischen Strukturen der Informationsverarbeitung zu berücksichtigen, um intelligente Systeme zu realisieren. Dennoch gewinnen diese biologischen Strukturen, die intelligentes Verhalten ermöglichen, für die Informatik eine ganz spezielle Bedeutung, nämlich dort, wo die Informatik gezwungen ist, die Mensch-Maschine Interaktion (MMI) (engl. 'Human-Computer Interaction (HCI)) im Interesse des menschlichen Anwenders substantiell zu verbessern. In dem Masse nämlich, als die Mensch-Maschine Interaktion von der Informatik fordert, dass die Maschinen/ Computersysteme mit den Menschen auf menschliche Weise kommunizieren können, ist die Informatik gezwungen, eine solche Kommunikationsfähigkeit bereit zu stellen (Informatik als Dienstleistung an der Gesellschaft!). In Fortführung der Erkenntnisse von Linguistik, Sprachpsychologie und Phonetik hat gerade die Neuropsychologie -mit der Unterabteilung Neurolinguistik- in den letzten Jahrzehnten zeigen können, dass die menschliche Kommunikation mit diversen Zeichensystemen so eng mit den konkreten Verarbeitungsstrukturen des Gehirns (z.B. in den Bereichen Wahrnehmung, Konzeptbildung, Gedächtnis, Denken usf.) verknüpft ist, dass die Generierung einer entsprechenden Kommunikationsfähigkeit in Maschinen bis auf Weiteres nicht vorstellbar erscheint ohne eine Rekonstruktion der einschlägigen Funktionen der neurobiologischen Strukturen. Auch wenn es in einer ferneren Zukunft vielleicht einmal möglich sein wird, von den konkreten biologischen Strukturen mehr und mehr zu abstrahieren, wird sich der Weg der Informatik in den nächsten Jahren in hinreichender Nähe zur Neuropsychologie bewegen müssen, zumindest sofern man die Mensch-Maschine Interaktion substantiell verbessern will.
Vor diesem methodischen Hintergrund verabreden wir hier die folgende Begriffe:
Intelligente (Computer-)Systeme (IS): Dies sind solche (Computer-)Systeme, die relativ zu einer verhaltenstheoretischen Definition von 'intelligentem Verhalten' als intelligent qualifiziert werden können
Funktional Bioanaloge Intelligente (Computer-)Systeme (FBIS): Dies sind intelligente (Computer-)Systeme, deren zugrundeliegende Struktur die Funktionsweise biologischer Informationverarbeitung simuliert, ohne aber die gleichen biologischen Materialien zu benutzen, die die entsprechenden biologischen Systeme auszeichnen.
Materiale Bioanaloge Intelligente (Computer-)Systeme (MBIS): dies sind funktional bioanaloge intelligente (Computer-)Systeme, die zugleich auch noch aus biologischem Material gebaut sind, das denen der biologischen Systeme ähnelt.
Auf den ersten Blick könnte man meinen, dass das Konzept Materialer Bioanaloger Intelligenter (Computer-)Systeme keinen Sinn macht, da man damit doch nur eine aufwendige Kopie existierender biologischer Systeme generieren würde, die es als solche doch schon gibt. Doch kann dies ein Trugschluss sein. Biologische Strukturen der Informationsverarbeitung können Eigenschaften besitzen, die jene der heute bekannten Technologien bei weitem überragen. Eine ingenieurmässige Beherrschung solcher Materialien wäre nicht einfach nur eine Kopie des Originals, sondern würde es erlauben, gezielt Strukturen zu entwickeln, die alle Vorteile der biologischen Strukturen enthalten aber zusätzlich nach Bedarf nach einem ingenieurmässigen Plan generiert werden können.
Aus dem umfangreichen Thema Intelligente (Computer-)Systeme sollen im folgendne nur zwei Aspekte kurz aufgegriffen werden, nälich der Aspekt des 'Lernens von Umwelteigenschaften' sowie der 'symbolischen Kommunikation', wobei die symbolische Kommunikation den Aspekt des 'Erlernens einer Sprache' beinhaltet.
Die Themen Wissenserwerb und symbolische Kommunikation sind eingebettet in das Interaktionsgeflecht zwischen Menschen, Maschinen und Umwelt (engl. 'environment' (ENV)). Wie das nachfolgende Bild zeigt, kann man fünf grundsätzliche Typen von Interaktionen unterscheiden:
Human-Human-Interaction (HHI): Interaktionen zwischen Menschen
Human-Environment-Interaction (HEI): Interaktionen zwischen Menschen und Umwelt
Human-Computer-Interaction (HCI): Interaktionen zwischen Menschen und Computern
Computer-Computer-Interaction (CCI): Interaktionen zwischen Computern und Computern
Computer-Environment-Interaction (CEI): Interaktionen zwischen Computern und Umwelt
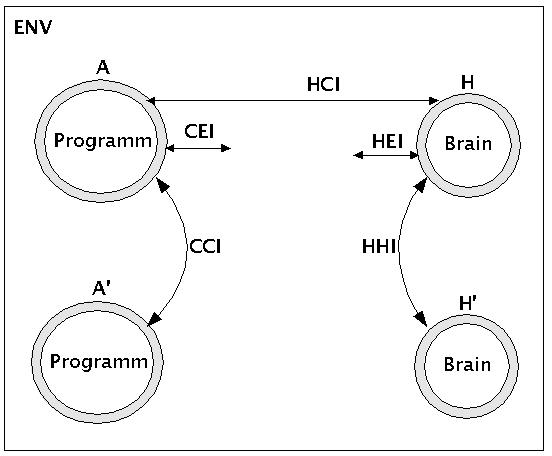
Interactions between Humans, Computers, and Environments
Ausgenommen vielleicht (noch) bei der Computer-Computer-Interaktion handelt es sich bei der Human-Computer-Interaktion sowie der Computer-Umgebungs-Interaktion aus Sicht des Computers um eine Interaktion mit einer sich prinzipiell dynamisch verhaltenden Grösse. Während man sich in der Vergangenheit damit zufrieden geben konnte, dass Computer ihre Leistungen auf klar definierte Ausschnitte von Umwelt oder menschlichem Verhalten mit konstanten Eigenschaftsprofilen beschränkten, ist es schon heute so, dass man von Computern fordert -und mehr und mehr fordern wird-, dass sie sich zunehmend adaptiv verhalten, d.h. dass sie sich zunehmen selbständig auf Veränderungen von Eigenschaftsprofilen einstellen. Dies betrifft einmal den Aufbau von Wissen im allgemeinsten Sinne, wie auch speziell den Erwerb von solchen Sprachen, mit denen Menschen gewohnt sind, untereinander zu kommunizieren. Der Aufbau von Wissen hat u.a. zu tun mit der Generierung dynamischer Modelle mit vagen Grössen, die es gestatten, wahrnehmbare veränderliche Eigenschaften der Umgebung als Teile von Prozessen mit Vagheiten und Zufälligkeiten zu repräsentieren und jederzeit zu aktualisieren bzw. anzupassen.
Das Thema Wissenserwerb soll an dieser Stelle nur erwähnt, aber nicht ausführlicher behandelt werden. Es sei nur soviel bemerkt, dass die Basis von dynamischen Modellen die elementaren Wahrnehmungsprozesse sind, die ein intelligentes Systeme mit Eigenschaftsprofilen der Umgebung sowie des eigenen Systems versorgen. Diese Werte sind multimodal (visuell, akustisch, olfaktorisch, kinematisch usf.), hochdimensional (nicht nur einzelne Werte, sondern simultan mehrere tausend bis hundertausend oder gar Millionen gleichzeitig), und sind bezogen auf implizite räumliche und zeitliche Strukturen, die bei der Generierung der Modelle zu berücksichtigen sind.
Allerdings einige Bemerkungen zur sprachlichen Kommunikation und dem Erwerb von Sprache. Das nachfolgende Bild zeigt stark vereinfacht eine minimale Struktur, die bei (menschlichen) intelligenten Systemen anzunehmen ist, die in der Lage sind, sprachlich zu kommunizieren.
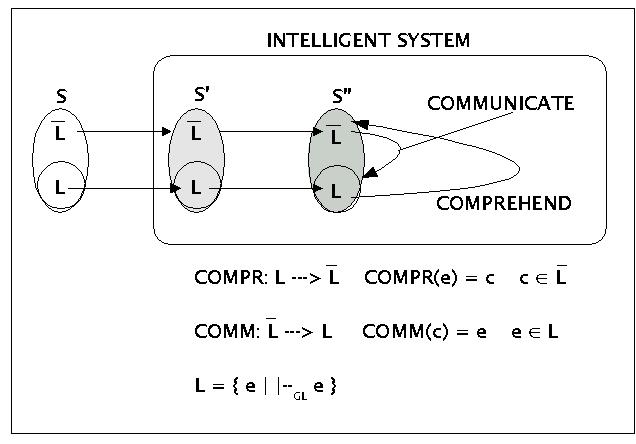
Basics of Language Communications
In diesem theoretischen Rahmen wird angenommen, dass man grundsätzlich mindestens drei Stufen der Signalverarbeitung in einem intelligenten System unterscheiden muss:
Der physikalische Reiz S (:= Stimulus), wie er in einer Umwelt auftritt
Diejenigen Sinnesreize S', die durch die Verarbeitung durch Sinnesorgane dem iternen System zur Verfügung stehen
Die abstrakten Konzepte S'', die auf der Basis konkreter Sinnesreize S' vom System generiert werden.
Für intelligente Systeme, die sprachlich kommunizieren, muss man zusätzlich minimal fordern, dass sie auf jeder Verarbeitungsstufe {S, S', S''} zwischen jenen Elementen unterscheiden können, die als sprachliche Ausdrücke (engl. 'expressions (E)) die eigentliche Sprache L (L := Language) konstituieren, und jenen Elementen, die nicht als sprachliche Ausdrucksmittel dienen, eben das Komplement zu L, compl(L) (in der Grafik: L-quer). Diese nichtsprachlichen Elemente compl(L) werden hier einfach als Konzepte (Modelle/ Strukturen) bezeichnet, ohne dass sie näher beschrieben werden (dies gehört zum Thema 'Wissen').
Man kann dann zwischen mindestens zwei grundsätzlichen Abbildungen (Funktionen) unterscheiden:
COMPREHEND (COMPR) (Verstehen): COMPR: L --> compl(L); COMPR(e) = c
COMMUNICATE (COMM) (Kommunizieren): COMM: compl(L) ---> L; COMM(c) = e
Die Idee hinter dieser Formalisierung ist die, dass es zwei grundsätzlich verschiedene Vorgänge sind, ob ich nichtsprachliche Elemente c aus compl(L) in sprachliche Ausdrücke e aus L abbilde (kodieren, mitteilen, kommunizieren, sagen, artikulieren, ...), oder ob ich sprachliche Ausdrücke e aus L auf nichtsprachliche Konzepte c aus compl(L) projiziere (verstehen, einsehen, dekodieren...). Die Menge der benutzten sprachlichen Ausdrücke (immer in bestimmten Kontexten aus compl(L) bildet dann die Sprache L. Sofern man die Sprache L mit einer Grammatik GL beschreiben kann, könnte man dann auch sagen, dass die Sprache L die Menge jener Ausdrücke e ist, die sich in der Grammatik GL erzeugen lassen:
L = { e | |--GL e }
In einer etwas detaillierteren Systematik müsste man allerdings mindestens die folgenden Unterscheidungen treffen:
SYNTAX: man betrachtet ausschliesslich die Ausdrucksseite einer Sprache L unter dem Aspekt der erlaubten korrekten Ausdrücke von L. Dies wird üblicherweise abgehandelt im Rahmen des Themas formale Sprachen, formale Grammatiken.
LOGIK: man betrachtet eine Menge von Ausdrücken einer Sprache L unter dem Aspekt, welche Ausdrücke sich aus welchen anderen unter Beibehaltung ihres Wahrheitswertes folgern lassen. Dies wird üblicherweise abgehandelt im Rahmen der (formalen) Logik.
SEMANTIK: den Wertebereich der Funktion COMPREHEND (s.o.) bezeichnet man informell auch oft als Bedeutung (engl. 'meaning') jener Ausdrücke e, denen die Funktion COMPR Werte zuordnet. Im Rahmen einer formalen Semantik handelt es sich dabei naturgemäss wieder nur um formale Strukturen, die für die postulierten Bedeutungswerte stehen.
Natürlichsprachliche Syntax mit Semantik und Logik: Während in den formalen Disziplinen Syntax, Logik und Semantik die Aspekte Korrektheit, Wahrheit und Bedeutung in der Regel isoliert betrachtet werden (was für spezielle Kontexte sehr wohl Sinn machen kann), bestehen diese drei Aspekte im Rahmen einer sogenannten natürlichen Sprache gleichzeitig nebeneinander und sie interagieren beständig; im Rahmen einer natürlichen Sprache ist es praktisch unmöglich, diese einzelnen Aspekte isoliert zu untersuchen, ohne dabei wesentliche Eigenschaften des Gegenstandes zu verlieren. Dies macht auch die Untersuchung natürlicher Sprachen unverhältnismässig viel schwieriger als die Untersuchung isolierter künstlicher Teilsysteme.
Traditionellerweise werden an der FH im Rahmen der theoretischen Informatik nur Teile der formalen Syntax untersucht. An Universitäten kommen noch Teilgebiete der formalen Logik (z.B. automatisches Theorembeweisen) und Aspekte der formalen Semantik hinzu. Im Hinblick auf die immer drängendere Herausforderung in Form intelligenter Systeme ist dies sicherlich zu wenig.
Abschliessend zum allgemeinen Thema intelligenter Systeme und überleitend zum Thema formale Sprachen und Automaten sei hier das Thema Erkennbarkeit und Erlernbarkeit von Sprachen angesprochen.
Mit Erkennbarkeit (engl. 'recognizability') ist gemeint, ob ein System A in der Lage ist, nach endlich vielen Schritten zu entscheiden, ob ein Pattern p ein Element einer bestimmten Sprache L ist oder nicht.
Mit Erlernbarkeit (engl. 'learnability') einer Sprache L im schwachen Sinne soll hier gemeint sein, dass ein System A in der Lage ist, eine endliche Menge P' von Pattern nach endlich vielen Schritten auf der Basis von Vorkommnissen von Elemente aus P' in einer Umwelt E als sprachliche Ausdrücke einer Sprache L zu identifizieren, die Elemente c aus einer Menge C von Konzepten kodieren.
Mit Erlernbarkeit einer Sprache L im starken Sinne soll hier einerseits Erlernbarkeit im schwachen Sinne gemeint sein, zusätzlich aber auch, dass ein System A in der Lage ist, auf der Basis einer endlichen Menge P' von Pattern nach endlich vielen Schritten auf der Basis von Vorkommnissen von Elemente aus P' in einer Umwelt E über ein Wissen K zu verfügen, mittels dessen sich alle Ausdrücke der Sprache L erkennen lassen, auch jene, die nicht in P' enthalten sind.
Mit Formaler Erlernbarkeit einer Sprache L im schwachen Sinne soll hier gemeint sein, dass ein System A in der Lage ist, eine endliche Menge P' von Pattern nach endlich vielen Schritten auf der Basis von Vorkommnissen von Elemente aus P' in einer Umwelt E als sprachliche Ausdrücke einer Sprache L zu identifizieren, ohne zusäzlichen Bezug zu Elementen c aus einer Menge C von Konzepten.
Entsprechend soll mit Formaler Erlernbarkeit einer Sprache L im starken Sinne einerseits Formale Erlernbarkeit im schwachen Sinne gemeint sein, zusätzlich aber auch, dass ein System A in der Lage ist, auf der Basis einer endlichen Menge P' von Pattern nach endlich vielen Schritten auf der Basis von Vorkommnissen von Elemente aus P' in einer Umwelt E über ein Wissen K zu verfügen, mittels dessen sich alle Ausdrücke der Sprache L erkennen lassen, auch jene, die nicht in P' enthalten sind.
Bei der Untersuchung der Erlernbarkeit einer Sprache kann man ferner den Aspekt der Zeit im Sinne einer Folge diskreter Zeitpunkte explizit einbeziehen oder nicht.
Bezieht man den Aspekt der Zeit nicht ein, dann spricht man von mengentheoretischer Erlernbarkeit (engl. 'settheoretical learnability'). In diesem Falle bildet die Basis der Erlernbarkeit die endliche Menge der Pattern L' (in einer Umwelt E), die als Teilmenge einer Sprache L zu identifizieren ist. Es lässt sich zeigen, dass die Ausklammerung des Zeitaspekts nichts an der grundsätzlichen Komplexität eines Lernproblems ändert.
Bezieht man den Aspekt der Zeit ein, dann spricht man von Text Erlernbarkeit (engl. 'text learnability'). In diesem Falle sind die Elemente aus der endlichen Menge L' der Stimulus-Pattern dem Lerner nacheinander zu einzelnen Zeitpunkten t0, ...,tn zugänglich. In diesem Fall wird gefordert, dass es einen Zeitpunkt tn gibt, ab dem ein 'Wissen K' über die Sprache L so verfügbar ist, dass das Sytem A auch jene Ausdrücke aus L erkennen kann, die nicht in L' sind.
Was die Erkennbarkeit von Ausdrücken einer rein formalen Sprach L angeht -also einer Sprachen, die nicht zusätzlich noch irgendwelche Elemente c aus einer Menge compl(L) kodiert-, so weiss man mittlerweile, dass man sowohl die Sprachen auf der Basis von Eigenschaften ihrer Erzeugungsregeln in einer Hierarchie (Chomsky Hierarchie) anordnen kann-, wie auch die Automaten, mittels deren man diese Sprachen erkennt. Es gibt also offensichtlich so etwas wie eine Komplexität im Bereich der sprachlichen Ausdrücke. Diese Sachverhalte werden im weiteren Verlauf der Vorlesung weiter untersucht werden.
Was die Text Erlernbarkeit von Sprachen betrifft, so konnte schon GOLD 1967 beweisen, dass keine der formalen Sprachen aus der Chomsky-Hierarchie texterlernbar sind, nicht einmal die regulären Sprachen! (siehe auch [WEXLER/CULICOVER 1980:48f]). Ferner gilt, dass mindestens Kontextfreie Sprachen auch nicht mengentheoretisch erlernbar sind. Dabei gilt der Zusammenhang, dass eine Sprache L die nicht mengentheoretisch erlernbar ist, erst recht nicht texterlernbar ist (vgl. dazu [WEXLER/CULICOVER 1980:50]). Diese Ergebnisse stehen in einem scharfen Kontrast zur empirischen Tatsache, dass alle Kinder -nahezu unabhängig von ihrem 'Intelligenzgrad'- in der Lage sind, jede natürliche Sprache L innerhalb eines endlichen Zeitabschnittes auf der Basis einer endlichen Teilmenge L' der möglichen Ausdrücke von L zu erlernen. Und da man davon ausgeht, dass zur Beschreibung der Grammatik natürlicher Sprachen Grammatiken mindestens von der Stärke der kontextfreien Grammatken notwendig sind -die meisten postulieren mindestens kontextsensitive Grammatiken-, folgt daraus, dass beim Erlernen natürlicher Sprachen durch biologische Systeme Prozesse am Werk sind und/ oder Randbedingungen gegeben sind, die von denen abweichen, die im Rahmen der klassischen Theorie der formalen Sprachen für gewöhnlich betrachtet werden. Will nun aber die Informatik die Herausforderung der Gegenwart und der Zukunft annehmen, intelligente Systeme bauen zu können, die auf menschliche Weise kommunizieren können, und dies schliesst die Fähigkeit des Erlernens jeder natürlichen Sprache als Teilaufgabe mit ein, dann muss die (theoretische) Informatik Modelle bereitstellen, die ein solches Verhalten ermöglichen. Aufgrund der Komplexität der hier angesprochenen Aufgabe kann dies nicht Gegenstand dieser Vorlesung sein. Es soll aber dennoch versucht werden, in dieser Vorlesung diesen zukunftsträchtigen Aspekt der (theoretischen) Informatik 'im Auge zu behalten'.
Bilden sie ein Team von 5 Mitgliedern
Erstellung Sie gemeinsam einen Text mit Namen und Matr.Nr. der AutorenInnen. Abgabe einer Kopie des Textes an den Dozenten vor Beginn der Übung.
Präsentation der Lösung als Team vor der gesamten Gruppe. Präsentationszeit (abhängig von der Gesamtzahl der Teams) 3-5 Min.
Auf welche Weise kann die (theoretische) Informatik die Disziplin der Neuropsychologie unterstützen? Was kann umgekehrt die Informatik von der Neuropsycholoie lernen?
Auf welche Weise könnte man von einem Computer sagen, dass er 'intelligent' sei?
Falls sie wüssten, auf welche Weise man einen Computer als 'intelligent' bezeichnen könnte, gäbe es dabei einen wesentlichen Unterschied zu einem Menschen, von dem man sagen würde, er sei 'intelligent'?
In welchen Situationen würden sie vorzugsweise (i) Intelligente (Computer-)Systeme (IS) einsetzen, die keine (FBIS) und keine (MBIS) sind, (ii) Funktionale Bioanaloge Intelligente (Computer-)Systeme (FBIS), bzw. (iii) Materiale Bioanaloge Intelligente (Computer-)Systeme (MBIS)
Was macht eine Computer-Mensch-Interaktion (HCI) und eine Computer-Umgebungs-Interaktion (CEI) aus Sicht des Computers so schwierig?
Was sind die wichtigsten Aspekte, die man im Rahmen der Sprachverarbeitung in einem intelligenten System unterscheiden muss?
Was unterscheidet die Erkennbarkeit einer Sprache L von der Erlernbarkeit von L?
Warum bilden die Erkenntnisse zur Nichterlernbarkeit von Sprachen eine Herausforderung für die (theoretische9 Informatik?