|
|
I-THINF WS 0203 - Vorlesung mit Übung
|
Nach der Einführung des Konzeptes einer kontextfreien Grammatik und des zugehörigen Kellerautomaten soll nun das Thema aus Sicht des Parsing analysiert werden.
Parsing kann man entweder auffassen als (i) die Abbildung einer terminalen Kette K aus den terminalen Elementen Tg* einer Grammatik g in den Ableitungsbaum Sg der Grammatik g oder aber (ii) als die Abbildung in die akzeptierenden Endzustände (oder ausgezeichnete Kellerzeichen) eines Automaten a. In dieser Vorlesung betrachten wir den Fall (i).
Bezüglich der Algorithmen, die sprachliche Ausdrücke erkennen können, gibt es die grobe Unterscheidung in Top down oder Bottom up sowie Generell und speziell (siehe Tabelle):
|
|
TOP DOWN |
BOTTOM UP |
|
GENERELL |
Early (Top Down, CFG) |
CYK (Bottom up, CNF) |
|
SPEZIELL |
LL |
LR |
Mit 'generell' ist gemeint, dass dieser Algorithmus alle kontextfreien Sprachen erkennen kann, mit speziell, dass es nur eine Untermenge ist.
Ein Top down Parser analysiert eine Eingabe dadurch, dass er mit dem Startsymbol beginnt und solange Ableitungen erzeugt, bis er eine terminale Kette erzeugt hat, die mit der Eingabe übereinstimmt.
Ein Bottom up Parser analysiert seine Eingabe, indem er ausgehend von den terminalen Zeichen der Eingabe Erzeugungsregeln sucht, mittels deren Teile der Eingabe erzeugt werden konnten. Darauf aufbauend werden weitere Erzeugungsregeln gesucht, solange, bis nur noch das Startsymbol übrig bleibt.
Es werden zunächst zwei einfache Beispiele gegeben. Beide Beispiele benutzen die folgende einfache Grammatik aus der letzten Vorlesung:
S ---> AB
A ---> ab | aAb
B ---> c | cB
Bei der Eingabe soll es sich in beiden Fällen um folgenden String handeln: 'aabbccc'
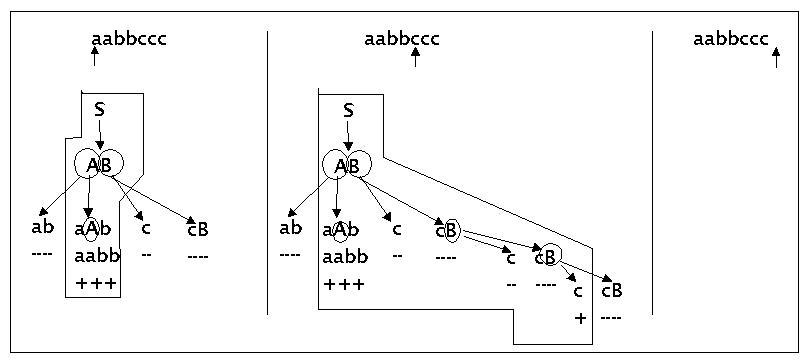
Einfaches paralleles Top-Down Parsing
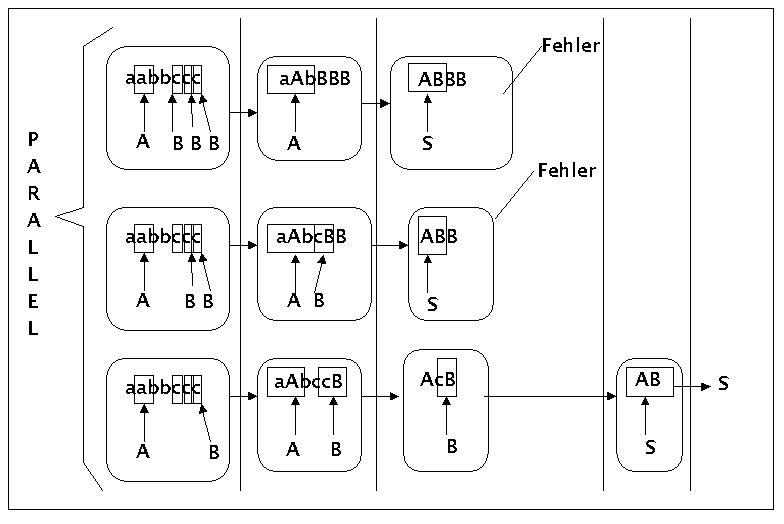
Einfaches paralleles Bottom-up Parsing
Die folgenden Überlegungen zum Top-Down Parsing basieren zu grossen Teilen auf dem sehr informativen Reader von [JURAFSKY/MARTIN 2000:357ff]. Ergänzend [AHO et al 1988].
Die wichtigsten Probleme bei einem einfachen Top-Down Parser sind:
Linksrekursivität
Mehrdeutigkeit (Ambiguität)
Backtracking
Eine Lösung der zuvor genannten Probleme bietet dynamisches Programmieren. Ein Algorithmus, der sich dynamisches Progammieren zunutze macht, ist der EARLY-Algorithmus (EARLY 1970).
...EARLY-Algorithmus...
Obwohl der EARLY-Algorithmus vom Zeitverhalten her schon polynom ist, d.h. einen Zeitbedarf von O(N3) besitzt (N ist die Anzahl der Elemente in der Eingabe), ist er für die Praxis im allgemeinen zu langsam. Es gibt effizientere Algorithmen mit einem linearen Zeitbedarf.
Sogenannte prädiktive Parser kommen ohne Rekursion aus; sie benötigen nur noch lineare Zeit, können dafür allerdings nur eine Untermenge der kontextfreien Sprachen erkennen, nämliche jene, die durch sogenannte LL(1)-Grammatiken definiert werden.
Beschreibung eines prädiktiven Parsers...
...Ausführung, Beispiele ...
LR(1)-Parser sind stärker als LL(1) Parser, aber haben dennoch nur linearen Zeitbedarf. Konkrete Beispiele für LR(1)-Parser kann man mit dem Parsergenerator 'yacc' ('yet another compiler-compiler') oder durch den verbesserten GNU-Parsergenerator Bison erzeugen (siehe auch lex/yacc für Windows)
Obgleich die LR(1)-Grammatiken eine Untermenge der Kontextfreien Grammatiken sind, kann man die meisten in der Praxis auftretenden Fälle von kontextfreien Sprachen mit LR(1)-Parsern bewältigen.
...Ausführung, Beispiele ...
Werden in der Übung gegeben.