|
|
I-THINF WS 0203 - Vorlesung mit Übung
|
In dieser und der nächsten Vorlesung soll das Konzept der kontextfreien Grammatik sowie die damit verbundenen Parsingmethoden eingehender vorgestellt werden. Von allen bekannten Grammatiktypen haben die kontextfreie Grammatik mit ihren vielfältigen Varianten die grösste praktische Bedeutung. Einige der Anwendungsszenarien, in denen solche Grammatiken zur Anwendung kommen, sind die folgenden:
Naürlichsprachliche Schittstellen
Hilfesysteme
Befehlsschnittstellen
Mustererkennung ('Pattern Recognition')
Bildschirmlayout-Masken
Textübersetzung
Sprachübersetzungübersetzung
Spracherkennung
Sprachsynthese
Bildbearbeitung
usw.
Entsprechend der grossen praktischen Bedeutung ist das Gebiet der kontextfreien Grammatiken sehr umfangreich. Wir werden in der verbleibenden Zeit nur einige wenige Grundkonzepte vorstellen können. Wer sein Wissen gezielt vertiefen will, dem seien neben [SCHÖNING 2001] und [HEDSTÜCK 2002] die beiden theoretisch orientierten Überblicksartikel von [J-M.AUTEBERT/ J.BERSTEL/ L.BOASSON 1997] und [K.SIKKEL/ A.NIJHOLT 1997] empfohlen sowie die eher praxisorientierte Einführung von [Alfred V.AHO/ Ravi SETHI/ Jeffrey D.ULLMAN 1988].
Für verschiedene theoretische Zwecke (spezielle Beweise) wie auch für bestimmte praktische Aufgaben (z.B. spezielle Parsing-Algorithmen) wurden unterschiedliche Normalformen entwickelt, in die hinein sich eine formale Grammtik vom Typ2 übersetzen lässt. Einige der wichtigsten Normalformen seien hier aufgelistet (siehe dazu ausführlicher [J-M.AUTEBERT/ J.BERSTEL/ L.BOASSON 1997]):
Kontextfreie Grammatik (Context Free Grammar [CFG]): (u,w) in P dann u in V und w in (V u T)*
Schwache Chomsky Normalform [WCNF]: (u,w) in P dann u in V und w in V* oder w in T u {§}
Chomsky Normalform [CNF]: wenn Schwache Chomsky Normalform und w in V* mit |w| < 2
Greibach Normalform [GNF]: (u,w) in P dann u in V und w in AV*
Quadratische Greibach Normalform [2GNF]: wenn Greibach Normalform [GNF] und |V*| = 2
Doppelte Greibach Normalform [TGNF]: (u,w) in P dann u in V und w in AV*A oder A
Operator Normalform [ONF]: (u,w) in P dann u in V und w in (V u T)* und w enthält keine zwei aufeinanderfolgenden Variablen (d.h. zwischen zwei Variablen kommt mindestens ein terminales Zeichen vor).
Alle diese Normalformen sind untereinander äquivalent. Ein Beispiel für die Chomsky Normalform [CNF] wird in dieser Vorlesung gegeben; in der nächsten Vorlesung wird ein Beispiel in Greibach Normalform [GNF] verwendet werden.
An dieser Stelle ist auch die sogenannte Backus-Naur Form [BNF] bzw. die Extended Backus-Naur-Form [EBNF] zu erwähnen (siehe für eine ausführlichere Übersicht hier ( mit Link auf eine ausführliche Darstellung von EBNF).
Die BNF und die EBNF-Notation ist ebenfalls äquivalent zu einer kontextfreien Grammatik. Sie eignet sich insbesondere zur Darstellung von kontextfreien Grammatiken in computerlesbarer Form.
Es wird jetzt das Beispiel einer konkreten CFG g6 gegeben. Anhand eines allgemeinen Verfahrens wird diese Grammatik g6 dann in eine CNF umgeformt. Die Beispielsprache anbncm wird auch weiter unten im Zusammenhang mit einem Kellerautomaten verwendet werden.
Zielobjekt ist die Sprache L = {anbncm | n,m > 1}:
Es sei FG(g6,2) mit Vg6 = {S,A,B} und Tg6 = {a,b,c} und
Pg6 = {
S ---> AB
A ---> ab | aAb
B ---> c | cB
}
Beispiele von Ableitungen mit g6:
S
AB
abB
abc
S
AB
aAbB
aabbB
aabbc
S
AB
aAbB
aabbB
aabbcB
aabbccB
aabbccc
Satz: Wenn es eine kontextfreie Grammatik g gibt, dann kann man eine kontextfreie Grammatik g' in CNF effektiv konstruieren.
Für die Konstruktion wird das folgende Verfahren vorgeschlagen (siehe [J-M.AUTEBERT/ J.BERSTEL/L.BOASSON 1997:125]
Zu jedem terminalen Zeichen a der Grammatik g wird ein nichtterminales Zeichen Xa der Grammatik g' eingeführt; zugleich wird jedes terminale Zeichen a in g durch das neue Zeichen Xa in g' ersetzt. Dann wird für jedes terminale Zeichen a in g' die Regel Xa ---> a hinzugefügt.
Für alle nichtterminalen Worte mit Länge grösser 2 werden diese Worte von links nach rechts so zerlegt, dass jeweils zwei Variablen X1X2REST durch eine neue Variable Y ersetzt werden und die Regel V ---> X1X2 hinzugefügt wird.
Wendet man dieses Verfahren auf die Grammatik g6 an, dann erhält man folgendes Ergebnis:
Anwendung von Regel 1: Vg6' = {S,A,B,C,D,E} und Tg6' = {a,b,c} und
Pg6' = {
S ---> AB
A ---> CD | CAD
B ---> E | EB
C ---> a
D ---> b
E ---> c
}
Anwendung von Regel 2: Vg6' = {S,A,B,C,D,E,F} und Tg6' = {a,b,c} und
Pg6' = {
S ---> AB
A ---> CD | FD
B ---> E | EB
F ---> CA
C ---> a
D ---> b
E ---> c
}
Beispiele von Ableitungen:
S
AB
CDB
aDB
abB
abc
S
AB
FDB
CADB
aADB
aCDDB
aaDDB
aabDB
aabbB
aabbc
S
AB
FDB
CADB
CCDDB
CCDDEB
CCDDEEB
aCDDEEB
aaDDEEB
aabDEEB
aabbEEB
aabbcEB
aabbccB
aabbccc
aabbccc
Die Umwandlung in eine Greibach Normalform (GNF) benutzt die Umwandlung in eine Chomsky Normalform als ersten Schritt. Die nächsten Umwandlungsschritte sind allerdings etwas aufwendiger (siehe dazu die Darstellung in [SCHÖNING 2001:54ff]).
Diejenigen Automaten, die in der Lage sind, alle kontextfreien Sprachen zu erkennen, das sind die Kellerautomaten ('push down automata' [PDA]). Ausgehend von einer Turingmaschine kann man das Prinzip von Kellerautomaten wie folgt einführen (siehe Bild):
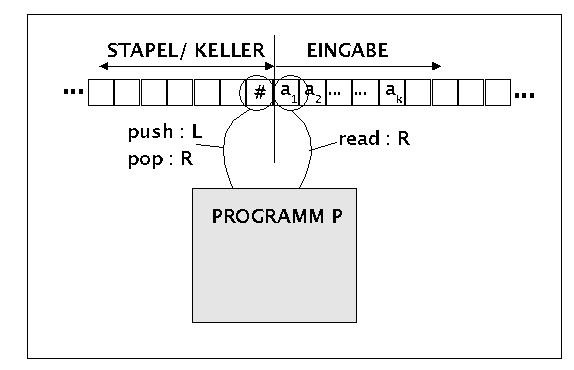
Prinzipschaltbild eines Kellerautomaten
Statt nur einen Schreib-Lese-Kopf besitzt ein Kellerautomat zwei Leseköpfe, wobei der eine auch schreiben kann. Der eine Lesekopf -nennen wir ihn KE- ist dazu da, dass er eine Eingabe E lesen kann. Im Bild wird angenommen, dass dies von links nach rechts geschieht; man könnte die Vereinbarung aber auch umgekehrt treffen. Das Lesen der Eingabe E = a1,a2, ..., ak geschieht einmalig und ist unumkehrbar; mit jedem gelesenen Zeichen wandert der Lesekopf KE ein Feld nach rechts. Der andere Schreib-Lesekopf -nennen wir ihn KS-, beginnt in einer Ausgangsposition und kann mittels Schreiben (Operation 'push') ein Feld nach links bewegt werden, und mittels Lesen (Operation 'pop') ein Feld nach rechts. Der Bereich des Bandes, der von KS gelesen und geschrieben werden kann, funktioniert hier als ein Stapel ('stack'), der für das Programm wie ein Speicher/ Gedächtnis/ Keller fungiert. In der hier angenommenen Version eines Kellerautomaten hat der Stapel zu Beginn das Start-Keller-Zeichen '#' (Doppelkreuz). Vereinbarungsgemäss steht KS zu Beginn auf dem Feld mit dem Zeichen '#' und KE auf dem ersten Feld der Eingabe, von links nach rechts.
Def.: PDA(a) gdw a = << Q, Ti, Ts, {q0}, {#}>, P >
mit
Q: Endliche Menge von Zuständen
Ti: Alphabet für mögliche Eingaben
Ts: Alphabet für den Stapel/ Keller; Ti cut Ts = 0
q0: der Startzustand; q0 in Q
# : das Startelement für den Stapel; '#' in Ts
P: das Programm von a bzw. die Überführungsfunktion:
Das Programm P eines Kellerautomaten berechnet in Abhängigkeit von einem aktuellen Zustand q aus Q, einem aktuell gelesenen Zeichen a aus Ti (aus der Eingabe) sowie einem aktuell gelesenen Zeichen A aus Ts (dem Stapel/ Keller) die nächste Aktion. Dies kann nicht-deterministisch geschehen oder deterministisch.
Während bei Turingmaschinen die deterministische Turingmaschine den Standardfall darstellt, ist es bei Kellerautomaten die nichtdeterministische Variante. Die deterministische Variante von Kellerautomaten ist schwächer als die nichtdeterministische. Nur der nichtdeterministische Kellerautomat erkennt alle Sprachen, die von einer kontextfreien Grammatik erzeugt werden können.
Def.: NPDA(a) gdw PDA(a) und es gilt
P: Q x (Ti u {§}) x (Ts u {§}) ---> 2e(Q x Ts*)
(Anmerkung: '2e' repräsentiert die Menge aller endlichen Teilmengen)
Diese Überführungsfunktion P besagt also, dass in Abhängigkeit von einem aktuellen Zustand q aus Q, einem aktuell gelesenen Zeichen a aus Ti (aus der Eingabe) sowie einem aktuell gelesenen Zeichen A aus Ts (dem Stapel/ Keller) eine endliche Menge von Folgezuständen bestimmt wird, wobei jedem Folgezustand q' ein Wort B1...Bk über Ts* korrespondiert, d.h. das oberste Element des Stapels A wird durch ein neues Wort B1...Bk ersetzt. Ist das Wort B1...Bk = 0 (d.h. 'leer'), dann entspricht dies der 'pop'-Aktion, d.h. das oberste Element des Stapels wird entfernt.
Das Programm eines nichtdeterministische Kellerautomaten besteht damit also aus einer Menge von 4-Tupeln der Art:
< q,a,A,{(q'1,B1), (q'2,B2)...}> (Bi Wort über Ts*)
Vergleicht man dies mit den Aktionen <q,a,q',b,m > einer deterministischen Turingmaschine, dann fällt sofort auf, dass ein nichtdeterministischer Kellerautomat neben den Eingabezeichen eben noch von dem Zustand des Stapels gesteuert wird. Ferner wird nicht allgemein auf das Band geschrieben, sondern nur auf jenen Bereich, der für den Stapel reserviert ist. Schliesslich sind die Bewegungen m der Turingmaschine nur implizit gegeben: ein leeres Wort entspricht der Aktion 'pop', d.h. gehe ein Feld nach rechts, und ein nicht-leeres Wort bedeutet die Aktion 'push', d.h. gehe ein Feld nach links. Man kann also schon von dieser Architektur her augenfällig erkennen, dass der nichtdeterministische Kellerautomat gegenüber der Turingmaschine dadurch beschränkt ist, dass er für einen reservierten Teil des Bandes nur 'passiv' lesen kann.
Analog zur Turingmaschine und zum endlichen Automaten benötigen wir hier auch wieder den Begriff der durch einen nichtdeterministischen Kellerautomaten erkennbaren Sprache:
Def.: LNPDA(a) = {x in Ti* | NPDA(a) & (E:q)( <q0,x,#>
|---a* <q,§,§> & q in Qa )}
Die durch einen nichtdeterministischen Kellerautomaten a erkennbaren Sprache LNPDA besteht also aus denjenigen Worten x über Ti*, für die gilt, dass ausgehend von dem Anfangszustand q0, dem Wort x, und dem Keller-Startsymbol # ein Zustand q so abgeleitet werden kann, dass sowohl die Eingabe wie auch der Keller leer (= §) sind.
Um den dabei zur Verwendung kommenden Ableitungsbegriff '|---a*' benutzen zu können, muss dieser zuvor eingeführt worden sein. Dies wird hier -analog zum Fall der Turingmaschine- über den Begriff der Konfiguration geleistet.
Zu jedem Zeitpunkt ist der aktuelle Zustand eines Kellerautomaten eindeutig gegeben durch den aktuellen
Zustand q, durch den aktuellen Rest der Eingabe a1...an sowie durch den aktuellen Kellerinhalt
k1...km, also
< q,a1...an, k1...km> in Q x (Ti* u {§}) x (Ts*
u {§}).
Ein solches 3-Tupel soll eine Konfiguration heissen. Durch Anwendung des Programms P() geht diese Konfiguration in eine
Folgekonfiguration über mit
<
q',a1...an, B1...Br...km>,
falls P(q,§,k1)
oder in
< q',a2...an, B1...Br...km>,
falls P(q,a1,k1)
Def.: k ist eine Konfiguration vom NPDA a: CONFIG(k,a) gdw NPDA(a) & k in Q x (Ti* u {§}) x (Ts* u {§})
Def.: k' ist eine direkte Ableitung von k mit NPDA a: DABL(k,k',a) gdw CONFIG(k,a) & CONFIG(k',a) &
(E:q,q',a1,...,an,k1, ...,km,B1,...,Br)(
(i) [ k=< q,a1...an, k1...km> & k'= < q',a1...an,
B1...Br...km> & <q,§,k1,{...,(q',B1...Br),...} >
in P]
or
(ii) [ k=<
q,a1...an, k1...km> & k'= < q',a2...an,
B1...Br...km> & <q,a1,k1,{...,(q',B1...Br),...} >
in P]
)
Def.: x ist ableitbar mit NPDA a: ABL(x,a) gdw (E:t,n,q)( t ist ein Tupel der Länge n & q in Qa & (A:i,j)( i,j in dm(t) & j=i+1 ==> DABL(ti,tj) & t0 = <q0,x,#, > & tn-1 = <q,§,§ >))
Wie üblich soll folgende Schreibweise vereinbart werden:
k |--a k' gdw DABL(k,k',a)
<q0,x,#, > |--a* <q,§,§ > gdw ABL(x,a)
Anmerkung: Eine interessante Variante von (N/D)PDAs bilden jene, in denen man mehr als ein spezielles Kellerzeichen einführt, nämlich sogenannte Fehler-Zeichen F*. Dise kann man benutzen, um unerwünschte Anordnungen von Eingabezeichen als 'Fehler' zu markieren. Man könnte dann neben dem Begriff 'ableitbar in a' auch den Begriff 'fehlerhaft in a' definieren.
Analog zu den anderen Automaten kann man auch im Fall des Kellerautomaten einen passenden Zustandsgraphen definieren (siehe nachfolgendes Bild).
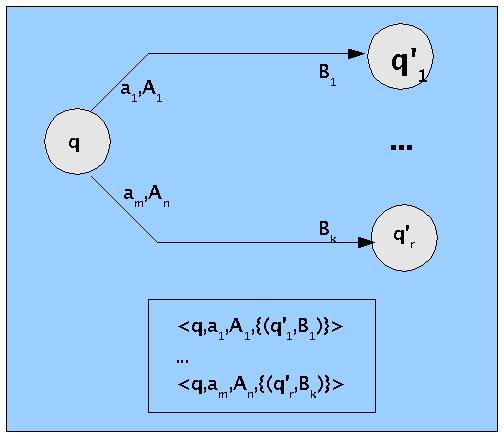
Zustandsgraph zum Kellerautomaten
Auf diese Weise lassen sich einfache Automaten übersichtlich darstellen. Im folgenden geben wir zu der Sprache L = {anbncm | n,m > 1} einen Kellerautomaten an, der diese Sprache erkennen kann.
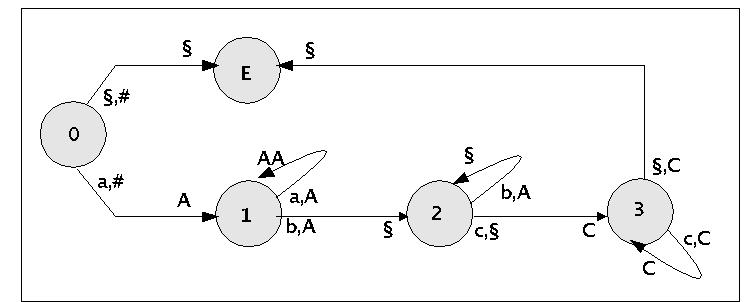
Zustandsgraph zum Kellerautomaten für die Sprache anbncm
Das zugehörige Programm lautet wie folgt:
<0,§,#,{(E,§)} >
<0,a,#,{(1,A)} >
<1,a,A,{(1,AA)} >
<1,b,A,{(2,§)} >
<2,b,A,{(2,§)} >
<2,c,§,{(3,C)} >
<3,c,C,{(3,C)} >
<3,§,C,{(E,§)} >
<E,§,§,{(E,§)} >
Damit lassen sich folgende Ableitungen durchführen:
<0,abc,# >
<1,bc,A >
<2,c,§ >
<3,§,C >
<E,§,§ >
<0,aabbc,# >
<1,abbc,A >
<1,bbc,AA >
<2,bc,A >
<2,c,§ >
<3,§,C >
<E,§,§ >
Def.: DPDA(a) gdw PDA(a) und es gilt
P: Q x (Ti u {§}) x (Ts u {§}) ---> Q x Ts*
Diese Überführungsfunktion P besagt also, dass in Abhängigkeit von einem aktuellen Zustand q aus Q, einem aktuell gelesenen Zeichen a aus Ti (aus der Eingabe) sowie einem aktuell gelesenen Zeichen A aus Ts (dem Stapel/ Keller) genau ein Folgezustand bestimmt wird, wobei jedem Folgezustand q' ein Wort B1...Bk über Ts* korrespondiert, d.h. das oberste Element des Stapels A wird durch ein neues Wort B1...Bk ersetzt. Ist das Wort B1...Bk = 0 (d.h. 'leer'), dann entspricht dies der 'pop'-Aktion, d.h. das oberste Element des Stapels wird entfernt.
Das Programm eines nichtdeterministische Kellerautomaten besteht damit also aus einer Menge von 4-Tupeln der Art:
< q,a,A,(q',B1...Bk) >
Die Begriffe Konfiguration, direkte Ableitung sowie Ableitbar sind analog zu den Begriffe im Falle des NPDA zu bilden.
Def.: k ist eine Konfiguration vom DPDA a: CONFIG(k,a) gdw DPDA(a) & k in Q x (Ti* u {§}) x (Ts* u {§})
Def.: k' ist eine direkte Ableitung von k mit DPDA a: DABL(k,k',a) gdw CONFIG(k,a) & CONFIG(k',a) &
(E:q,q',a1,...,an,k1, ...,km,B1,...,Br)(
(i) [ k=< q,a1...an, k1...km> & k'= < q',a1...an,
B1...Br...km> & <q,§,k1,(q',B1...Br) >
in P]
or
(ii) [ k=<
q,a1...an, k1...km> & k'= < q',a2...an,
B1...Br...km> & <q,a1,k1,(q',B1...Br) >
in P]
)
Def.: x ist ableitbar mit DPDA a: ABL(x,a) gdw (E:t,n,q)( t ist ein Tupel der Länge n & q in Qa & (A:i,j)( i,j in dm(t) & j=i+1 ==> DABL(ti,tj) & t0 = <q0,x,#, > & tn-1 = <q,§,§ >))
Wie üblich soll folgende Schreibweise vereinbart werden:
k |--a k' gdw DABL(k,k',a)
<q0,x,#, > |--a* <q,§,§ > gdw ABL(x,a)
Dann kann man definieren:
Def.: LDPDA(a) = {x in Ti* | DPDA(a) & (E:q)( <q0,x,#>
|---a* <q,§,§> & q in Qa )}
Weitere Ausführungen zu Kellerautomaten folgen in der nächsten Vorlesung
Bezüglich der Algorithmen, die sprachliche Ausdrücke erkennen können, gibt es folgende grobe Unterscheidungen:
|
|
TOP DOWN |
BOTTOM UP |
|
GENERELL |
Early (Top Down, CFG) |
CYK (Bottom up, CNF) |
|
SPEZIELL |
LL |
LR |
Weitere Ausführungen folgen in der nächsten Vorlesung.
Weitere Ausführungen folgen in der nächsten Vorlesung.
Entsprechend der Darstellung von [SCHÖNING 2001:64ff] wurde anhand des CYK-Algorithmus ein Beispiel für einen generellen Erkennungs-Algorithmus für kontextfreie sprachen als Bottom-up Verfahren vorgestellt. Dieses Thema wird in der nächsten Vorlesung weiter vertieft werden.
Welche Anwendungsbeispiele kennen Sie aus eigener Erfahrung, in denen kontextfreie Sprachen und zugehörige Erkennungsverfahren benutzt werden?
Wären Sie in der Lage, zu erklären, welches Format die Normalformen CNF, GNF und EBNF haben? Wären Sie in der Lage, Beispiele für diese Formen zu konstruieren?
Beschreiben Sie das Prinzip eines Kellerautomaten.
Worin liegt der Unterschied zu einer deterministischen Turingmaschine?
Wie unterscheiden Sie einen Kellerautomaten von einem endlichen Automaten?
Wie lautet die generelle Übersetzungsvorschrift, um Zustände von Kellerautomaten in Zustandsgraphen zu übersetzen?
Versuchen Sie ein Beispiel eines Kellerautomaten für einfache Sprachen hinzuschreiben, z.B. die Sprachen a*, a*b* und anbn
Geben Sie explizite Ableitungen für die von ihnen definierten Automaten und Sprachen an.