|
|
I-THINF WS 0203 - Vorlesung mit Übung
|
Nach den vorausgehenden theoretischen Überlegungen soll jetzt anhand einfacher Beispiele darauf eingegangen werden, wie man endliche Automaten praktisch nutzen kann. Als erstes wird ein Algorithmus für einen endlichen Automaten angegeben (vgl. dazu [AHO et al 1988:140ff])
EINGABE: Ein Eingabestring w, abgeschlossen mit einem Linefeed LF. Der DFA a startet im Startzustand q0 und besitzt die akzeptierenden Endzustände E
AUSGABE: nicht als Inschrift, sondern nur als akzeptierender Zustand 1 in E oder als nicht-akzeptierender Zustand 0 in E. Tritt keiner dieser Zustände ein, wird '-1' ausgegeben: Fehler.
ALGORITHMUS:
/* P'() ist die Ableitungsfunktion von a */
Für diesen Algorithmus kann man zwei grosse Fälle unterscheiden:
FALL1: c in w vor LF
FALL2: c == LF
Im FALL1 gibt es die folgende Fälle:
c ist nicht in w: return 0
c ist in w und Wortende erreicht: return 1
c ist in w und Wortende nicht erreicht: hole nächstes Zeichen
FALL2 kann nur erreicht werden, wenn w ein Teilwort eines Wortes w' ist, das der Automat a akzeptieren würde: -1
Von der Struktur her könnte man diesen Automaten direkt (z.B. in C) programmieren. Der einzig aufwendige Teil wäre die Implementierung der Ableitungsfunktion P'(), da diese eine Tabelle darstellt. Jedesmal, wenn man die Tabelle ändert, müsste man diesen Teil des Automaten neu programmieren. Bei grösseren Automaten mit einigen hundert (oder gar tausenden) von Zuständen, eine mühsame Aufgabe. Einfacher wäre es, man hätte ein automatisches Generierungsverfahren, das, ausgehend von der Spezifikation der zu erkennenden Sprache L(g,3) automatisch einen entsprechenden deterministischen Automaten a generieren würde. Solche Generatoren gibt es. Einer der berühmtesten ist lex (bzw. flex, die GNU-Version von lex).
Um diese Version verstehen zu können, muss man noch kurz den Begriff der Regulären Ausdrücke [RE := Regular Expressions] einführen.
So, wie man mittels einer formalen Grammatik g vom Typ3 eine reguläre Sprache L(g,3) definieren kann, so kann man dies auch mittels sogenannter regulärer Ausdrücke (ursprünglich eingeführt von dem berühmten Logiker und Metamathematiker KLEENE, siehe [SHENG YU 1997]).
Reguläre Ausdrücke stellen praktisch AusdrucksSCHEMATA dar, d.h. sie beschreiben ein allgemeines MUSTER ('PATTERN'), das eine ganze Menge von möglichen konkreten Ausdrücken festlegt. Man definiert diese Ausdrücke meist induktiv:
Sei RE die Menge der regulären Ausdrücke über einem endlichen Alphabet T
0 ist in RE
§ ist in RE
Wenn a in T dann ist a auch in RE
Wenn e,e' in RE, dann ist auch (e | e') in RE; auch geschrieben [e,e']
Wenn e,e' in RE, dann ist auch (e . e') in RE; auch geschrieben ee'
Wenn e in RE, dann ist auch e* in RE; e* bezeichnet kein Zeichen aus T oder beliebig viele aneinandergereiht
Wenn e in RE, dann ist auch e+ in RE; e+ bezeichnet beliebig viele Zeichen aus T, mindestens aber eines
Nur was nach (1) - (8) gebildet wurde, ist ein regulärer Ausdruck.
Um Klammern zu sparen gelten folgende Prezedenz-Regeln: * > . > |
Beispiele:
[abc]+ := beliebige Zeichenketten aus 'a' oder 'b' oder 'c', mindestens aber ein Buchstabe, z.B. 'a', 'b', 'c','aa', 'aab',...
[abc]+[0123456789]* := Buchstabenketten aus 'a' oder 'b' oder 'c', gefolgt von Ziffern, z.B. 'a001', 'aabb1234' usw.
In der Praxis werden die syntaktischen Elemente von regulären Ausdrücken oft noch stark erweitert. nachstehend ein Auszug aus der Beschreibung des Scannergenerators flex (siehe weiter unten und mit dem Befehl 'man flex' unter einer Linux-Shell):
PATTERNS
The patterns in the input are written using an extended
set of regular expressions. These are (only a subset):
x match the character 'x'
. any character (byte) except newline
[xyz] a "character class"; in this case, the pattern
matches either an 'x', a 'y', or a 'z'
[abj-oZ] a "character class" with a range in it; matches
an 'a', a 'b', any letter from 'j' through 'o',
or a 'Z'
[^A-Z] a "negated character class", i.e., any character
but those in the class. In this case, any
character EXCEPT an uppercase letter.
[^A-Z\n] any character EXCEPT an uppercase letter or
a newline
r* zero or more r's, where r is any regular expression
r+ one or more r's
r? zero or one r's (that is, "an optional r")
r{2,5} anywhere from two to five r's
r{2,} two or more r's
r{4} exactly 4 r's
{name} the expansion of the "name" definition
(see above)
"[xyz]\"foo"
the literal string: [xyz]"foo
\X if X is an 'a', 'b', 'f', 'n', 'r', 't', or 'v',
then the ANSI-C interpretation of \x.
Otherwise, a literal 'X' (used to escape
operators such as '*')
\0 a NUL character (ASCII code 0)
\123 the character with octal value 123
\x2a the character with hexadecimal value 2a
(r) match an r; parentheses are used to override
precedence (see below)
rs the regular expression r followed by the
regular expression s; called "concatenation"
r|s either an r or an s
r/s an r but only if it is followed by an s. The
text matched by s is included when determining
whether this rule is the "longest match",
but is then returned to the input before
the action is executed. So the action only
sees the text matched by r. This type
of pattern is called trailing context".
Eine Kurzcharakteristik von (f)lex erhält man über die man-page mit der Abfrage 'man lex':
flex is a tool for generating scanners: programs which
recognized lexical patterns in text. flex reads the given
input files, or its standard input if no file names are
given, for a description of a scanner to generate. The
description is in the form of pairs of regular expressions
and C code, called rules. flex generates as output a C
source file, lex.yy.c, which defines a routine yylex().
This file is compiled and linked with the -lfl library to
produce an executable. When the executable is run, it
analyzes its input for occurrences of the regular expres
sions. Whenever it finds one, it executes the correspond
ing C code.
flex ist also ein Hilfsmittel, das es einem ermöglicht, einen endlichen Automaten automatisch generieren zu lassen. Was man benötigt ist eine Beschreibung der zu erkennenden Sprache mittels einer endlichen Menge von regulären Ausdrücken. Den generellen Einsatz von flex zeigt das folgende Schaubild (siehe zu (f)lex generell das ausführliche Buch von [HEROLD 1992]):
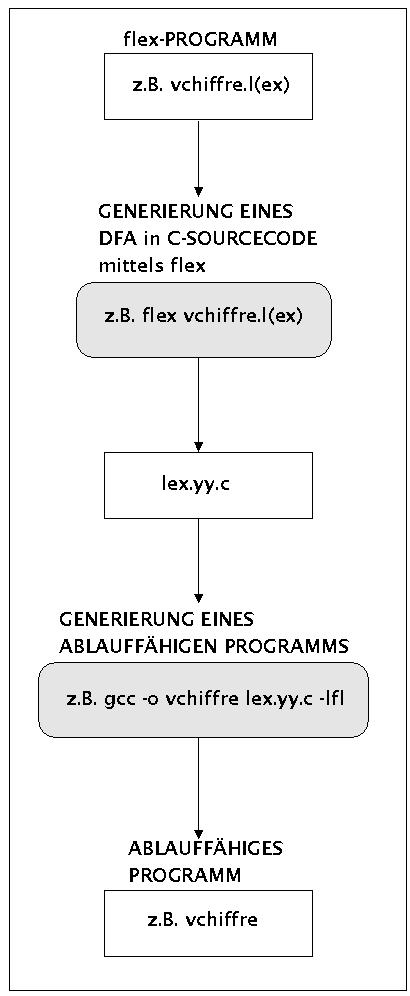
Übersicht zum Einsatz des GNU-Scannergenerators flex
Aufbau und Funktion eines flex-Programms soll nun anhand einiger einfacher Beispiele erläutert werden. Generell besteht ein (f)lex-Programm aus drei Teilen:
Definitionen
%% (f)lex-Regeln %%
Benutzerdefinierte Routinen
Eine (f)lex-Regel besteht dabei aus zwei Teilen: PATTERN AKTION. PATTERN ist ein regulärer Ausdruck und AKTION ist eine Folge von C-Befehlen, die in geschweiften Klammern stehen.
Wir erläutern diese drei Teile anhand einfacher Programmbeispiele. Das erste Programm vchiffre.lex (aus [HEROLD 1992:43]) besitzt nur einen Teil mit (f)lex-Regeln:
/*******************
*
* vchiffre.lex
*
* author: herold
*
* idea: Verschlüsselung der Eingabe
*
**************************/
%%
[A-Z] printf("%c",65+(yytext[0]-65+3) % 26);
[a-z] printf("%c",97+(yytext[0]-97+3) % 26);
Der Regelteil besteht aus zwei Regeln. Das Pattern der ersten Regel '[A-Z]' erkennt einzelne Grossbuchstaben, das Pattern der zweiten Regel '[a-z]' erkennt einzelne Kleinbuchstaben. Im aktionsteil finden wir jeweils einen C-Befehl (printf). Im Rahmen des C-Befehls wird von der Variablen yytext[] Gebrauch gemacht. Diese repräsentiert den Eingabepuffer des endlichen Automaten.Die übrigen mathematischen Operationen dienen der Berechnung eines Verschlüsselungskodes auf der Basis des ASCII-Kodes des einzelnen Zeichens.
gerd@goedel:~/WEB-MATERIAL/fh/I-THINF/EX-THINF/EX10> cat klartext.txt Dies ist ein erster Test. gerd@goedel:~/WEB-MATERIAL/fh/I-THINF/EX-THINF/EX10> ./vchiffre < klartext.txt Glhv lvw hlq huvwhu Whvw.
Das nachfolgende Programm ist das Gegenstück zu vchiffre: dechiffre transformiert den verschlüsselten Kode wieder zurück in 'normalen' ASCII-Kode. Aus Sicht eines (f)lex-Programms hat dechiffre.lex die Besonderheit, dass hier der potentielle dritte Teil eines Lex-Programms, nämlich die benutzerdefinierte Routine, genutzt wird. Es wird hier die Funktion 'dechiffre()' definiert, die dann innerhalb der Aktion benutzt wird.
/*******************
*
* dechiffre.lex
*
* author: herold
*
* idea: Entschlüsselung der Eingabe
*
**************************/
%%
[A-Z] dechiffre('A');
[a-z] dechiffre('a');
%%
void dechiffre(int start){
char c;
c = yytext[0] - start + 26 -3;
printf("%c",start + c % 26);
}
gerd@goedel:~/WEB-MATERIAL/fh/I-THINF/EX-THINF/EX10> ./vchiffre < klartext.txt > chiffre.txt gerd@goedel:~/WEB-MATERIAL/fh/I-THINF/EX-THINF/EX10> ./dechiffre < chiffre.txt Dies ist ein erster Test.
Wie man sieht, erfüllt das Programm seinen Zweck.
Das nächste Programm enthält zwar nur eine Lex-Regel, aber das Pattern dieser Regel erkennt nicht nur einzelne Buchstaben, sondern ganze Buchstabenfolgen, nämlich alle Folgen von Vokalen 'aeiou'; diese werden durch den Vokal 'i' ersetzt:
/*******************
*
* ivoc.l
*
* author: herold
*
* idea: Umlautung der Eingabe
*
**************************/
%%
[aeiou]+ printf("i");
Hier die Anwendung:
gerd@goedel:~/WEB-MATERIAL/fh/I-THINF/EX-THINF/EX10> ./ivoc Mal sehen, ob nun etwas passiert Mil sihin, ib nin itwis pissirt
Man sieht, man könnte lex auch zu allerlei stilistischen Spielereien/ Verfremdungen gebrauchen. Das folgende Beispiel benutzt alle drei potentiellen Teile eines Lex-Programms. Im Definitionsteil des Programms wordcount.l werden C-Variablen definiert und auf einen Anfangswert initialisiert. Im Aktionsteil werden diese Variablen zum Zählen von Ereignissen benutzt. Im Routinenteil wird die Lex-Standardroutine yylex() dazu benutzt, um die Vaiablen auszuwerten und eine Mittelung auf den Bildschirm zu drucken:
/*******************
*
* wordcount.l
*
* author: herold
*
* idea: Zaehlen von Eingaben
*
**************************/
int worte=0;
int lfeed=0;
int space=0;
%%
[a-zA-Z]+ {worte++;}
\n {lfeed++;}
[ ]+ {space++;}
%%
yywrap()
{
printf("\t %6d WORTE \n",worte);
printf("\t %6d LINEFEEDs \n",lfeed);
printf("\t %6d SPACEs \n",space);
}
gerd@goedel:~/WEB-MATERIAL/fh/I-THINF/EX-THINF/EX10> cat klartext.txt
Dies ist ein erster Test.
gerd@goedel:~/WEB-MATERIAL/fh/I-THINF/EX-THINF/EX10> ./wordcount < klartext.txt
. 5 WORTE
1 LINEFEEDs
4 SPACEs
Das letzte Beispiel hat folgende zwei Besonderheiten: einmal wird die Sprache der Beispielgrammtik g4 bzw. g5 aus der letzten Vorlesung hier mittels regulärer Ausdrücke beschrieben. Zusätzlich werden Zwischenräume, Tabulatoren sowie Linefeeds überlesen. Zum anderen werden hier sowohl die benutzerdefinierte Routine vom Lex-Programm durch ein eigenes C-Rahmenprogramm usage10.c ersetzt, wie auch die Definitionen durch eine eigene Headerdatei demo10.h ersetzt.Das Rahmenprogramm usage10 ruft die Funktion yylex() auf. Diese liefert bei jedem Aufruf die Kennzahl des nächsten von lex erkannten Tokens; sobald lex das Ende der Eingabe erreicht hat, liefert yylex() den Wert 0. Die Kennzahlen der Token werden in der Headerdatei demo10.h festgelegt.
/**************** * * demo10.h * * author: gdh * first: dec-01,02 * last: - * idea: Header for lex-example * *****************/ #include <stdio.h> #define WORT 256 #define ZEILENENDE 257
/*****************
*
* scan1.lex
*
* author: gdh
* first: dec-01,02
* last:-
* idea: Demo zur Nutzung von (f)lex als DFA
*
* compilation: flex scan1.lex
* output: lex.yy.c
*
************************/
%{
#include "demo10.h"
%}
%%
[ \t]+ ; /* Blanks und Tabs werden überlesen */
\n {return(ZEILENENDE);}
an[nk]e {return(WORT);}
abzug {return(WORT);}
ablage {return(WORT);}
%%
/****************
*
* usage10.c
*
* author: gdh
* first: dec-01,02
* last:-
* idea: Benutzung einer lex-datei
*
* compilation: gcc -o usage10 usage10.c lex.yy.c -lfl
* usage: usage10
*
****************/
#include "demo10.h"
int main(void){
int token;
while(token=yylex() ){
switch(token){
case WORT: {printf("WORT\n"); break; }
case ZEILENENDE: {printf("ZEILENENDE\n"); break; }
default: {printf("FEHLER\n"); break;}
}/* End of token */
}/* End of while */
return (1);
}
gerd@goedel:~/WEB-MATERIAL/fh/I-THINF/TH-THINF/VL10> ./usage10 anne WORT ZEILENENDE anke WORT ZEILENENDE abflug abflugZEILENENDE abzug WORT ZEILENENDE ablage WORT ZEILENENDE ww wwZEILENENDE
Man sieht, dass das programm usage10 alle Worte erkennt, die die Grammatiken g4 und g5 definiert haben. Bei anderen werden dise so durchgereicht, wie sie eingegeben wurden.
Werden in der Übung gegeben.