|
|
RECHNERARCHITEKTUR WS 04 - Vorlesung mit Übung
|
In der letzten Vorlesung wurde sichtbar, dass die Abarbeitung eines Assemblerkodes durch den mic1-Simulator aus der Perspektive der Assemblerbefehle nur partiell verständlich war. Die Aktivierung eines einzigen Assemblerbefehls war jedesmal begleitet von einer ganzen Serie von Mikrobefehlen. M.a.W. um einen einzelnen Assemblerbefehl auszuführen war jeweils die Abarbeitung einer ganzen Serie von Mikrobefehlen notwendig. Um diese Verständnislücke zu schliessen werden wir uns jetzt der Mikroarchitektur und den darin kodierten Mikrobefehlen zuwenden. Wir folgen dabei dem Kap.4 des exzellenten Buches von Andrew S.TANENBAUM/ James GOODMAN [2001]
Für die Beantwortung der Frage, was denn der Mikrokode ist, kann man zunächst den Standpunkt der Organisationsebenen in einem Computer wählen. Aus dieser Sicht ist der Mikrokode im Bereich der Harware anzusiedeln, allerdings nicht als konkreter Zustand sondern als die charakteristische Weise, wie die Hardware von einem bestimmten Zustand in eine Folge von weiteren Zuständen übergeht. Eine bestimmte Zustandsfolge definiert einen Mikrobefehl. Aus Sicht der Software entsprechen diesen charakteristischen Zustandsfolgen der Hardware bestimmte Bitmuster im Speicher bzw. -eine Stufe höher-- bestimmte Bytesequenzen (vgl. Tabelle).
|
Hochsprache (z.B. C) |
Beschreibung von Algorithmen |
|
|---|---|---|
|
Assembler |
Beschreibung von Algorithmen |
|
|
Byte-Kode |
Unterste Kodierung von Programmiersprachen |
ISA |
|
Bitmuster |
||
|
Zustandsübergänge |
Potentialänderungen der Hardware |
Mikrokode |
|
Funktionsblöcke |
Zusammenschaltung von Gattern |
|
|
Digitale Gatter |
Kleinste Strukturen der Schaltungslogik |
|
Diejenige Menge von Bitmustern bzw. Bytesequenzen, die die charakteristische Zustandsfolgen einer bestimmten Hardware repräsentieren, definieren wiederum die sogenannte ISA-Schnittstelle (ISA := Instruction Set Architecture).
Aus der Sicht der Automatentheorie (vgl. parallele Vorlesung zur Theoretischen Informatik) wissen wir, dass ein Automat im wesentlichen durch seine Maschinentafel definiert ist (auch Systemfunktion oder Produktionsregel genannt). Eine Maschinentafel besteht aus einer geordneten Menge von Zuständen, für jeden Zustand festgelegt ist, wie seine möglichen Nachfolgezustände lauten.
Fragt man sich, wie man eine solche Menge von Zuständen mit den jeweiligen Übergängen mittels Hardware realisieren will, dann geht das nur dadurch (vgl. auch die vorausgehende Vorlesung über den sequentiellen Automaten), dass man Zustände als Menge von Potentialen auffasst, die sich aufgrund von logischen Schaltungen in einer festgelegten Weise ändern können. Definiert man einen Zustand also als eine charakteristische Menge von Signalen, dann kann man eine charakteristische Änderung dieser Signalmenge durch Vorgabe einer bestimmten binären logischen Schaltung festlegen.
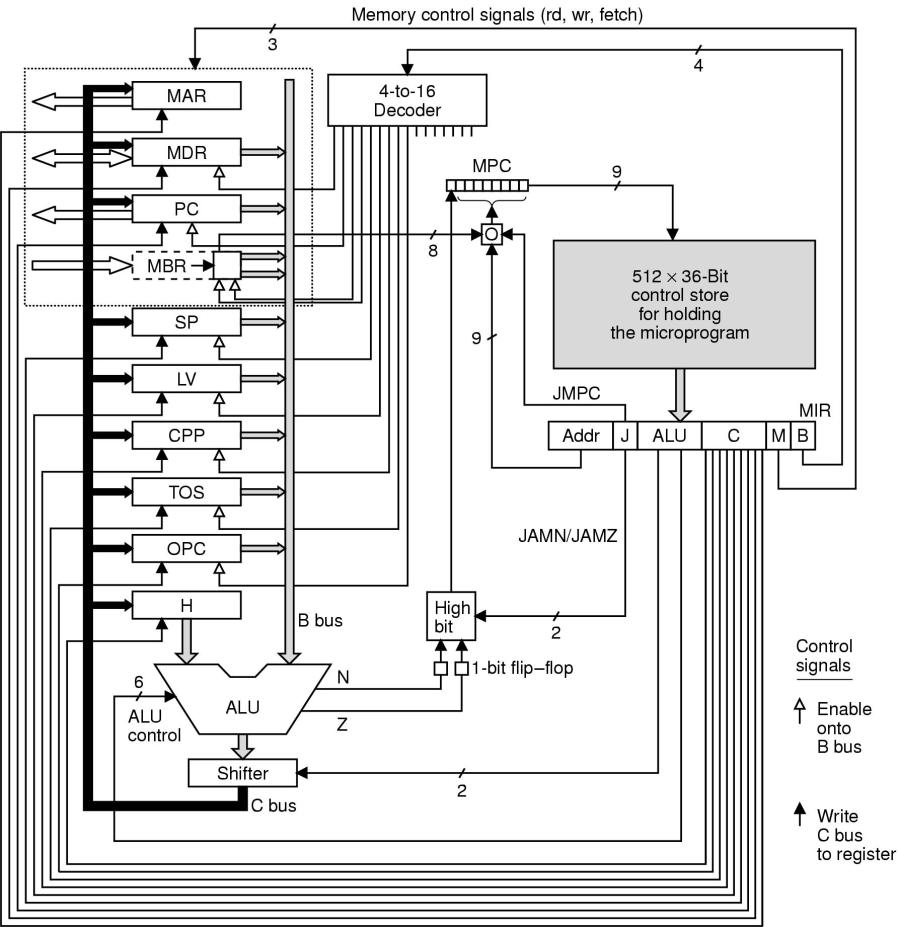
In der nachfolgenden Abbildung sieht man, wie der Mikrokode in der Modell-CPU in einem control store (Befehlsspeicher) --typischerweise ein ROM-Baustein-- als eine Folge von Bitmustern mit einer Breite von 36 Bit abgelegt ist.
Microarchitecture
Für eine ausführliche Darstellung siehe [Andrew S.TANENBAUM/ James GOODMAN 2001:247-263].
Der grundsätzliche Funktionszusammenhang zwischen Assemblerprogramm, Mikrokode und Hardware ist der, dass im Hauptspeicher (RAM) ein Programm als Bytefolge liegt. Der Befehlszähler (PC := Program Counter) adressiert die einzelnen Bytes des Programms und holt sie über das Byteregister (MBR := Memory Byte Register) in die CPU. Jedes Befehls-Byte repräsentiert eine Zahl, die eine Adresse im Mikrokode darstellt. Diese Adresse wird vom MBR in den Mikrokode Befehlszähler (MPC := Microcode Program Counter) kopiert und von dort dem Mikrokode zur Verfügung gestellt. Der Mikrokode selbst bildet eine grosse Befehlsschleife, die zu Beginn immer nach einem neuen Befehls-Byte fragt. Liegt ein solches Befehls-Byte vor, dann springt die Schleife an die Stelle im Mikroprogramm, auf die dieses Befehls-Byte verweist. An dieser Stelle wird dann die Abarbeitung fortgesetzt. Eine solche Abarbeitung umfasst entweder nur einen einzelnen Eintrag oder eine ganze Folge von solchen Einträgen. Im lezteren Fall ruft jeder Eintrag seinen eigenen Nachfolger auf.
Alle Daten werden im Gegensatz zu den Befehlen nicht über die Register PC und MBR abgearbeitet sondern werden mittels dem Adressregistr (MAR) adressiert und mittels dem Datenregister (MDR) gelesen bzw. geschrieben.
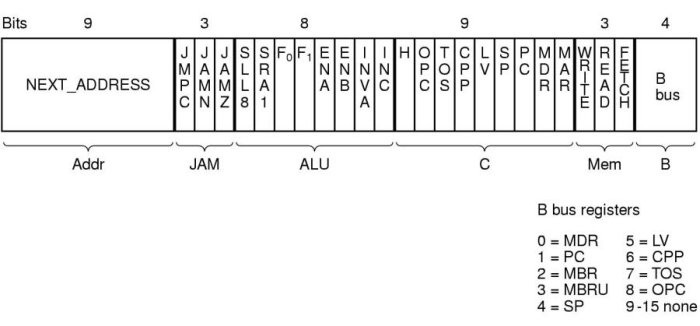
Bei jeder Aktivierung eines Mikrobefehls wird ein 36-Bit-Wort in das Mikrobefehls-Register (MIR := Micro Instruction Register) geschrieben. Diese Bits werden dazu benutzt, über Leitungen bestimmte Hardwarekomponenten zu steuern.
Mikrobefehls-Register (MIR)
So steuern die Leitungen für den C-Bus, welches Register vom C-Bus lesen kann und die Leitungen für den B-Bus, welches Register auf den B-Bus schreiben kann. Während zum Lesen mehr als ein Register aktiviert sein kann, darf beim Schreiben nur genau ein Register einen Schreibzugriff besitzen. Zu beachten ist, dass das H-Register ständig aktiviert ist!
Eine spezielle Rolle ergibt sich für das MBR. Es liest 32-Bit Daten vom C-Bus oder 8-Bit Daten aus dem Memory. Im Falle der 32-Bit vom C-Bus werden aber nur die niederwertigen 8-Bit beruecksichtigt. Werden die 8-Bit Daten auf den 32-Bit breiten B-Bus ausgegeben, dann muessen die 8 Bit des MBR auf 32 Bit erweitert werden (extended). Dabei muss entschieden werden ob die 32-Bit vorzeichenlos sind (unsigned) oder vorzeichenbehaftet (signed). Welche dieser beiden Möglichkeiten zutrifft hängt von den beiden Steuerleitungen ab, die vom 4-aus-16-Dekodierbaustein kommen, der wiederum seine Daten aus dem B-Feld des Mikrobefehls-Registers (MIR) empfängt. In beiden Fällen wir das höchstwertige Bit in die höherwertigen 24 Bit kopiert.
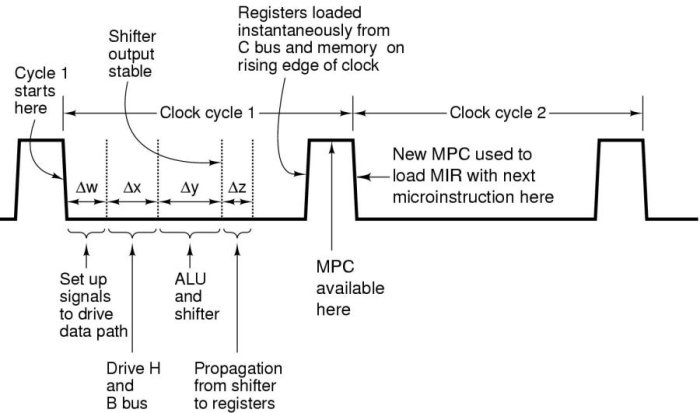
Da aus den ersten Vorlesungen über die Grundlagen der digitalen Schaltungen bekannt ist, dass die verschiedenen digitalen Signale minimale Signallaufzeiten beötigen, stellt sich hier die Frage, wie denn das Zusammenspiel all der verschiedenen Hardwarekomponenten funktionieren kann. Dies geht natürlich nur, wenn es ein klares Zeitmanagement gibt, dem alle Komponenten unterwofen sind und das diese unterschiedlichen Signallaufzeiten in Rechnung stellt. Ein solches Zeitmanagement ist im folgenden Schaubild dargestellt.
Zeitdiagramm für mic1
Nachdem ein Mikrobefehl auf dem High-Level des Takt-Signals verfügbar ist, stehen diese Bits bei der abfallenden Flanke zur Verfügung und können in der Phase Δw eingerichtet werden (damit ist gemeint, dass ein 36-Bit Wort aus dem Mikrobefehlsspeicher in das Mikrobefehlsregister geladen wird). Danach werden Inhalte von Registern in der Phase Δx auf den B-Bus geschrieben. In der folgenden Phase Δy verarbeitet die ALU mit dem Schieberegister die am H- und B-Bus anliegenden Daten. Das Ergebnis der ALU und des Schieberegisters wird dann in der Phase Δz über den C-Bus an die Register weitergeleitet; desgleichen die N- und Z-Flags in die entsprechenden N- und Z-Flip-Flops. Während der ansteigenden Flanke des nächsten Taktzyklus werden dann die Register vom C-Bus geladen. Dies ist auch die Zeit, während der der MPC eine neue MPC-Adresse lädt.
Im Falle einer Datenoperation bedeutet dieses Zeitmanagement, dass man einen Zyklus (1) benötigt, um Daten nach MAR zu bringen, dann benötigt man mindestens Zyklus (2) um mit den Daten von MAR den Speicher zu aktivieren und die Datenausgabe zu erreichen; diese können dann mit steigender Flanke in einem weiteren Zyklus (3) vom MDR übernommen und im Verlauf dieses Zyklus (3) zur ALU weitergereicht werden. Sollte das Memory aber einen ganzen Zyklus benötigen, dann würden die Memorydaten erst zu Beginn von Zyklus 4 für MDR zur verfügung stehen und erst in Zyklus 5 könnten die Daten dann über B-Bus und ALU weiter verarbeitet werden.
Aus diesem Beispiel kann man ersehen, dass die Eigenschaften der Hardware in das Zeitmanagement eingehen.
Ob die Adressierung des Mikrobefehlsspeichers durch MBR oder NEXT_ADDRESS von MIR erfolgt, hängt vom JAMC-Bit ab: bei JAMC = 1 wird MBR mit NEXT_ADDRESS ge-odert, andernfalls wird NEXT_ADRESS an MPC weitergegeben. Bei JAMN oder JAMZ = 1 wird zusätzlich das höherwertige Bit von NEXT_ADDRESS ge-odert.
SOURCE = Quellen für die ALU am B-Bus = {MAR, MDR, PC, MBR, MBRU, SP, LV, CPP, TOS, OPC} (MBRU := unsigned MBR). Zusätzlich kann die ALU natürlich H direkt lesen.
DEST = Mögliche Ziele für die ALU-Ausgabe am C-Bus = {MAR, MDR, PC, SP, LV, CPP, TOS, OPC, H }
Zusätzliche Qualifikationen: rd := read, wr := write von Wörtern, fetch := Holen eines Bytes. Dabei ist zu beachten, dass das Lesen/ SChreiben von Wörtern sowie das Holen eines Bytes parallel ablaufen können!
Die Ausgaben der ALU können vor Erreichung des Zieles (DEST) auch noch geshiftet werden ('<<8').
Z und N sind zwei imaginäre Register:
Z = TOS; if (Z) goto L1; else goto L2
goto (MBR OR Wert)
|
ALLE ZULÄSSIGEN OPERATIONEN |
|
DEST = H |
|
DEST = SOURCE |
|
DEST = ¬(SOURCE) |
|
DEST = H + SOURCE |
|
DEST = H + SOURCE + 1 |
|
DEST = H + 1 |
|
DEST = SOURCE + 1 |
|
DEST = SOURCE - H |
|
DEST = SOURCE - 1 |
|
DEST = -H |
|
DEST = H AND SOURCE |
|
DEST = H OR SOURCE |
|
DEST = 0 |
|
DEST = 1 |
|
DEST = -1 |
Das folgende Programm ist das aktuelle Mikroprogramm der simulierten IJVM-Mikroarchiektur, deassembliert aus der Binär-Datei, die der Simulator mic1sim liest, bevor er seine Simulation startet.
gerd@goedel:~/WEB-MATERIAL/fh/I-RA/MIC1SIM> java mic1dasm mic1ijvm.mic1 mic1dasm V0.0 0x0: goto 0x2 0x1: PC=PC+1;goto 0x40 0x2: PC=PC+1;fetch;goto (MBR) 0x3: H=TOS;goto 0x4 0x4: TOS=MDR=H+MDR;wr;goto 0x2 0x5: H=TOS;goto 0x6 0x6: TOS=MDR=MDR-H;wr;goto 0x2 0x7: H=TOS;goto 0x8 0x8: TOS=MDR=H AND MDR;wr;goto 0x2 0x9: H=TOS;goto 0xA 0xa: TOS=MDR=H OR MDR;wr;goto 0x2 0xb: MDR=TOS;wr;goto 0x2 0xc: goto 0xD 0xd: TOS=MDR;goto 0x2 0xe: MAR=SP;goto 0xF 0xf: H=MDR;wr;goto 0x11 0x10: SP=MAR=SP+1;goto 0x16 0x11: MDR=TOS;goto 0x12 0x12: MAR=SP-1;wr;goto 0x14 0x13: PC=PC+1;fetch;goto 0x27 0x14: TOS=H;goto 0x2 0x15: H=LV;goto 0x18 0x16: PC=PC+1;fetch;goto 0x17 0x17: TOS=MDR=MBR;wr;goto 0x2 0x18: MAR=H+MBRU;rd;goto 0x19 0x19: SP=MAR=SP+1;goto 0x1A 0x1a: PC=PC+1;wr;fetch;goto 0x1B 0x1b: TOS=MDR;goto 0x2 0x1c: MAR=H+MBRU;goto 0x1D 0x1d: MDR=TOS;wr;goto 0x1E 0x1e: SP=MAR=SP-1;rd;goto 0x1F 0x1f: PC=PC+1;fetch;goto 0x20 0x20: TOS=MDR;goto 0x2 0x21: H=MBRU<<8;goto 0x22 0x22: H=H OR MBRU;goto 0x23 0x23: MAR=H+LV;rd;goto 0x19 0x24: H=MBRU<<8;goto 0x25 0x25: H=H OR MBRU;goto 0x26 0x26: MAR=H+LV;goto 0x1D 0x27: H=MBRU<<8;goto 0x28 0x28: H=H OR MBRU;goto 0x29 0x29: MAR=H+CPP;rd;goto 0x19 0x2a: MAR=H+MBRU;rd;goto 0x2B 0x2b: PC=PC+1;fetch;goto 0x2C 0x2c: H=MDR;goto 0x2D 0x2d: PC=PC+1;fetch;goto 0x2E 0x2e: MDR=H+MBR;wr;goto 0x2 0x2f: PC=PC+1;fetch;goto 0x30 0x30: H=MBR<<8;goto 0x31 0x31: H=H OR MBRU;goto 0x32 0x32: PC=H+OPC;fetch;goto 0x33 0x33: goto 0x2 0x34: OPC=TOS;goto 0x35 0x35: TOS=MDR;goto 0x37 0x36: H=LV;goto 0x1C 0x37: N=OPC;if (N) goto 0x101; else goto 0x1 0x38: OPC=TOS;goto 0x39 0x39: TOS=MDR;goto 0x3A 0x3a: Z=OPC;if (Z) goto 0x101; else goto 0x1 0x3b: SP=MAR=SP-1;goto 0x3C 0x3c: H=MDR;rd;goto 0x3D 0x3d: OPC=TOS;goto 0x3E 0x3e: TOS=MDR;goto 0x3F 0x3f: Z=OPC-H;if (Z) goto 0x101; else goto 0x1 0x40: PC=PC+1;fetch;goto 0x41 0x41: goto 0x2 0x42: H=MBRU<<8;goto 0x43 0x43: H=H OR MBRU;goto 0x44 0x44: MAR=H+CPP;rd;goto 0x45 0x45: OPC=PC+1;goto 0x46 0x46: PC=MDR;fetch;goto 0x47 0x47: PC=PC+1;fetch;goto 0x48 0x48: H=MBRU<<8;goto 0x49 0x49: H=H OR MBRU;goto 0x4A 0x4a: PC=PC+1;fetch;goto 0x4B 0x4b: TOS=SP-H;goto 0x4C 0x4c: TOS=MAR=TOS+1;goto 0x4D 0x4d: PC=PC+1;fetch;goto 0x4E 0x4e: H=MBRU<<8;goto 0x4F 0x4f: H=H OR MBRU;goto 0x50 0x50: MDR=H+SP+1;wr;goto 0x51 0x51: SP=MAR=MDR;goto 0x52 0x52: MDR=OPC;wr;goto 0x53 0x53: SP=MAR=SP+1;goto 0x54 0x54: MDR=LV;wr;goto 0x55 0x55: PC=PC+1;fetch;goto 0x56 0x56: LV=TOS;goto 0x2 0x57: SP=MAR=SP-1;rd;goto 0xC 0x58: goto 0x5A 0x59: SP=MAR=SP+1;goto 0xB 0x5a: LV=MAR=MDR;rd;goto 0x5B 0x5b: MAR=LV+1;goto 0x5C 0x5c: PC=MDR;rd;fetch;goto 0x5D 0x5d: MAR=SP;goto 0x5E 0x5e: LV=MDR;goto 0x61 0x5f: MAR=SP-1;rd;goto 0xE 0x60: SP=MAR=SP-1;rd;goto 0x3 0x61: MDR=TOS;wr;goto 0x2 0x62: OPC=H+OPC;goto 0x63 0x63: MAR=H+OPC;goto 0x65 0x64: SP=MAR=SP-1;rd;goto 0x5 0x65: H=OPC=1;goto 0x66 0x66: H=OPC=H+OPC;goto 0x67 0x67: H=OPC=H+OPC;goto 0x68 0x68: H=OPC=H+OPC;goto 0x69 0x69: H=OPC=H+OPC+1;goto 0x6A 0x6a: H=OPC=H+OPC;goto 0x6B 0x6b: MDR=H+OPC+1;wr;goto 0x6C 0x6c: H=OPC=1;goto 0x6D 0x6d: H=OPC=H+OPC;goto 0x6E 0x6e: H=OPC=H+OPC+1;goto 0x6F 0x6f: H=OPC=H+OPC;goto 0x70 0x70: H=OPC=H+OPC;goto 0x71 0x71: H=OPC=H+OPC+1;goto 0x72 0x72: MDR=H+OPC;wr;goto 0x73 0x73: goto 0x74 0x74: MDR=H+OPC;wr;goto 0x75 0x75: H=OPC=1;goto 0x76 0x76: H=OPC=H+OPC;goto 0x77 0x77: H=OPC=H+OPC;goto 0x78 0x78: H=OPC=H+OPC+1;goto 0x79 0x79: H=OPC=H+OPC+1;goto 0x7A 0x7a: H=OPC=H+OPC+1;goto 0x7B 0x7b: MDR=H+OPC+1;wr;goto 0x7C 0x7c: H=OPC=1;goto 0x7D 0x7d: H=OPC=H+OPC;goto 0x7F 0x7e: SP=MAR=SP-1;rd;goto 0x7 0x7f: H=OPC=H+OPC+1;goto 0x80 0x80: H=OPC=H+OPC;goto 0x81 0x81: H=OPC=H+OPC;goto 0x82 0x82: H=OPC=H+OPC+1;goto 0x83 0x83: MDR=H+OPC;wr;goto 0x85 0x84: H=LV;goto 0x2A 0x85: goto 0xFF 0x86: OPC=H+OPC;goto 0x87 0x87: MAR=H+OPC;goto 0x88 0x88: MDR=TOS;wr;goto 0x89 0x89: goto 0x8A 0x8a: SP=MAR=SP-1;rd;goto 0x8B 0x8b: goto 0x8C 0x8c: TOS=MDR;goto 0x2 0x8d: OPC=H+OPC;goto 0x8E 0x8e: MAR=H+OPC;rd;goto 0x8F 0x8f: SP=MAR=SP+1;goto 0x90 0x90: TOS=MDR;wr;goto 0x2 0x91: goto 0xFE ... 0x98: goto 0xFE 0x99: SP=MAR=SP-1;rd;goto 0x38 0x9a: goto 0xFE 0x9b: SP=MAR=SP-1;rd;goto 0x34 0x9c: goto 0xFE ... 0x9e: goto 0xFE 0x9f: SP=MAR=SP-1;rd;goto 0x3B 0xa0: goto 0xFE ... 0xa6: goto 0xFE 0xa7: OPC=PC-1;goto 0x2F 0xa8: goto 0xFE ... 0xab: goto 0xFE 0xac: SP=MAR=LV;rd;goto 0x58 0xad: goto 0xFE ... 0xaf: goto 0xFE 0xb0: SP=MAR=SP-1;rd;goto 0x9 0xb1: goto 0xFE ... 0xb5: goto 0xFE 0xb6: PC=PC+1;fetch;goto 0x42 0xb7: goto 0xFE ... 0xc4: PC=PC+1;fetch;goto (MBR OR 0x100) 0xc5: goto 0xFE ... 0xfc: H=OPC=-1;goto 0x8D 0xfd: H=OPC=-1;goto 0x86 0xfe: H=OPC=-1;goto 0x62 0xff: goto 0xFF 0x100: goto 0xFE 0x101: OPC=PC-1;fetch;goto 0x2F 0x102: goto 0xFE ... 0x114: goto 0xFE 0x115: PC=PC+1;fetch;goto 0x21 0x116: goto 0xFE ... 0x135: goto 0xFE 0x136: PC=PC+1;fetch;goto 0x24 0x137: goto 0xFE ... 0x1ff: goto 0xFE
Was sind die Quellen für die ALU am B-Bus? (SOURCE)
Was sind die Ziele der ALU am C-Bus? (DESTINATION)
Welche Operationen kann die ALU mit den empfangenen Daten ausführen?
Welche Signale kann die ALU erzeugen?
Auf welche Weise kann das Ergebnis der ALU nochmals beeinflusst werden?
Wie können die Ergebnisse der ALU die Adressierung des nächsten Mikrocode-Befehles beeinflussen?
Welche Komponenten bestimmen die Adresse des nächsten Mikrocode-Befehles im MPC?
Was ist ein Mikro-Zyklus?
Was passiert mit den Signalen, die von einem Mikrobefehl gesetzt werden, innerhalb eines Mikro-Zyklus?
Wie greift die Hardware auf den Speicher zu?
Was ist der Unterschied zwischen Wortadressierung und Byteaddressierung? Welche Register sind bei der Wortadressierung beteiligt und welche bei der Byteadressierung?
Welche Funktion haben die Register CPP, LV, SP und PC?
Welche Funktion haben die Register MBR und MPC
Welche Funktion hat das Register H?
Welche Funktion haben die Register MAR und MDR?
Was muss passieren, damit ein IJVM-Assemblerbefehl im RAM, der in Byteformat vorliegt, über das MPC-Register einen bestimmten Mikrobefehl aktiviert?
Nehmen Sie sich die Mikroassemblerbefehle vor und versuchen sie zu verstehen, welche Vorgänge diesen im Bereich der Hardware-Architektur entsprechen.