
|
|
I-ALGO SS03 - ALGORITHMS AND DATASTRUCTURES - Lecture with Exercices |
Because there are only 7 lectures left for a subject, which could easily fill up 50 and more lectures, we have to select some topics of special interest. In this lecture I will give an overview of the planned topics of the next lectures. Then everybody can organize his reading and experimenting with programming in better agreement with the lectures. Furthermore we will intensify the exercices because only there we have a chance for practical applications.
Before we make our decisions about which topics we want to study in more detail we have to look around and to try some evaluation of the field. The following --shurely idealized-- diagram of the field with the known problems shall serve as some guide.
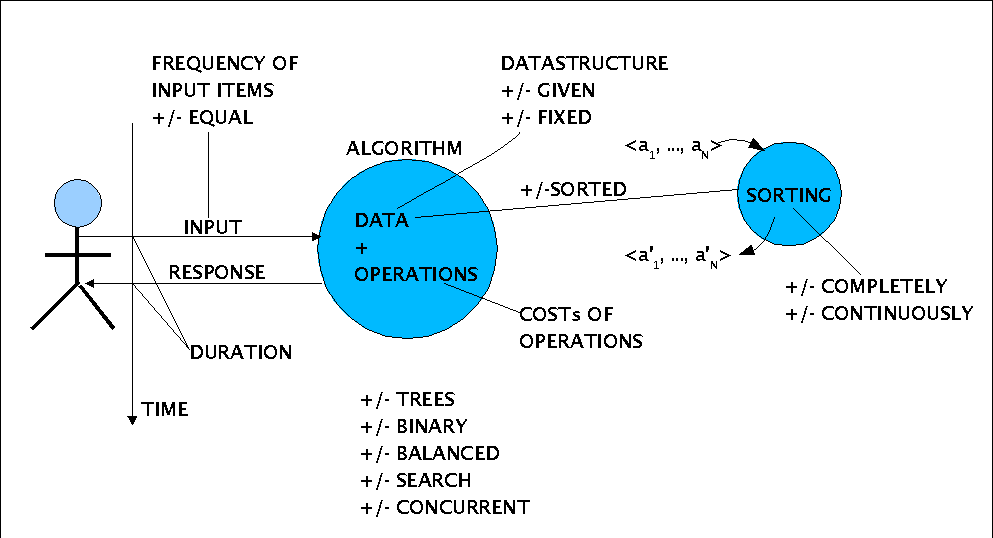
Problems to be solved
At the center we find the algorithms with datastructures and operations optimized for handling these datastructures. Any algorithm is interacting with an user which represents some kind of an environment. The environment provides input of the algorithm and the algorithm is responding. The time between input event at t and response event t+c represents the emprically observable responsetime c of the algorithm which can be measured and can be compared with the computed theoretical responstime c' of the algorithm.
The input d consist of commands like search(x,n), insert(x,n), delete(x,n) or others. The input can have different frequencies f(d) for every item or not.
The data of the algorithm can completely be given at the start or not; in the latter case the algorithm has to built up the data structure during runtime. The data can have the shape of trees or not, if trees, binary or not, balanced or not, with keys or not, together with the operations capable for concurrent operations or not, etc.
Some algorithms are presupposing the data to be given in a certain order, others not; they organize the needed order at run time. Ordering can be complete or only partial with an adaptive extension as needed.
From this simplified picture of the scenario we want wo select some subareas for the next 6 lectures.
I am assuming the following requirements as most interesting for further investigations:
The frequency of the input events is not evenly distributed but is usually uneven.
The algorithm has at the start time no or nearly no data at hand; the data have to be collected from the input stream.
The data have to be sorted during runtime.
As the main data structure we are assuming tree-like structures.
As the main typs of action-response pairs we assume
search - answer
insert - yes
delete - yes
stimulus - response yes/no with degree
forecast - yes/no with degree
From these assumptions we infer the following topics as interesting:
Have a look to Splay Trees because these assuming no equally disributed frequencies for their input and have to built up the datastructures at run time.
We will also have a look to AVL Trees, because these are the prototypes --also historically-- of balanced binary search trees. If time will allow, we will also analyze Red-Black Trees as a more advanced form of balanced binary search trees.
Bayesian Networks are a practically very important form of trees which allow the representation of data in a way which allows the actions of asking for the probability of certain states in a described environment or about the probability of some outcome in the future.
Introductory to these more advances topics we will examine and practically use basic data types of the C++-Standard Library like que, Stack, Queue, Priority Queue, Set and Map. Set and Map are escpecially interesting because these data structures are implemented as balanced binary search trees and --according to [JOSUTTIS 1999:176]-- usually as Red-Black Trees! Thus we can use these data structures in some sense as reference implementations for testing our own software.
From mathematics one knows that mathematical objects are presented as (algebraic) structures like < A, + > representing a set A with an operation '+' on A. For algorithms such representions are not common. But we will do this. Starting with in the beginning rather abstract ideas we will try to apply the general concepts during the course more and more to the concrete cases we will encounter.
As basic setting we are assuming an algorithm with input and output and a systemfunction responding to the input through the output:
ALGO(a) iff a = << I,O,EXPR,T,D>, f >
with
I := input set with I C EXPR x Dn
EXPR := set of expressions
D := set of data items
T := set of timepoints
O := output set
fD: I x T ---> O x T (:= System function)
Thus an input element could be an item like <search,x> forcing the system to respond as fD(<search,x>) = <yes>.
During the following lectures we have to elaborate this concept step by step.
In the next lecture we will show, what are trees compared to general graphs, and what are the special properties transforming a tree in a binary tree, then into a binary search tree and finally into a balanced binary search tree.
We will motivated these decisions and we will show implementations of basic tree structures and basic tree operations.
Algorithms for splay trees will be our first example of a special tree type. Assuming unequal frequency distributions in the input and having no data structures at the beginning splay trees built their data structures at runtime and they try to optimize their response behaviour by moving the more often used items to the top of the tree. It has to be shown, how one can implement operations on the tree which keep the overall structure of the tree approximately 'balanced'. Further on one has to compute theoretical estimates about the response behavior. Additionally we have to do some empirical measurements to check the theoretical values.
AVL trees (Adelson - Velskij - Landis have been the names of the authors of this algorithm) have been created 1962 as the historically first example of a balanced binary search tree. The idea is to keep the the tree in some balance defined on the length of the different paths of the tree.If one node n on a path has length k then should the two subtrees of n not have a length bigger or smaller than {+/-1}. To indicate the actual situation at every node they used to attache to every node in the tree a label with the balance factor p in {-1, 0, +1}.
Because inserting or removing can destroy a balance, the algorithm has to provide some operations to reconstruct a balance again. These operations are so-called rotation operations which can change the shape of the tree with regard to the length of the individual paths but which are leaving untouched the order of the keys.
Red-black trees are a more 'modern' form of a balanced binary search tree. Compared to AVL-trees they are optimized because they have less costs during reordering of a tree which has lost it's balance. Instead of a balance factor p they are using colouring information, because every node has to be coloured either red or black. The way the nodes are coloured reflects a certain order of the nodes and implicitly the information about the existing balance. Destroying the balance causes the order of the coloring to become 'irregular'. Reordering does mean here reorder the coloring.
During the last year it could be shown that many different types of balanced binary search trees can be subsumed as subcases under the concept of red-black trees, therefore and because red-black trees are rather efficient, they have gained a good acceptance in the community (cf. the case mentioned above, that the data structures 'set' and 'map' of the C++-Standard Library are realized as red-black trees!).
Another interesting kind of algorithms are Bayesian networks. Instead of using binar trees they are using directed acycliy graphs (DACs) to represent items and their relationships. The nodes are variables which have certain states and probabilities and the edges are representing observed or assumed dependencies between the variables. Bayesian networks can be used to compute the likelihood that some event depending from others will happen in the future. Because the whole topic is rather large we can only present an introductory exampel to give some glance of the power and beauty of this concept.
The data structure deque of the C++-STL is like a vector, but you can add or remove elements at the front or the end of the structure (with a vector you can only add at the end!). The deque is used as basis to define the data structure stack, queue and priority queue. We will use it in the next exercice.
In the lecture a code-example has been shown.
The data structure stack of the C++-STL is a LIFO-structure allowing the known operations pop(), push() and top(). One has to keep in mind that pop() does remove one element but does'n show it, whereas top() shows the element but doesn't remove it. push() puts some elemet on the top. We will use this through are exercices.
In the lecture a code-example has been shown.
The data structure queue of the C++-STL is a FIFO-structure with the operations front(), back(), push(), and pop(). pop() removes an element from the front of the structure, back() and front() do only show the element at the end resp. at the front. push() inserts an element at the back.
In the lecture a code-example has been shown.
The data structure priority queue of the C++-STL is similar to a queue with the additional feature that the order of the inserted elements is changed by some automatic ordering function. Depending from the user of the data structure the system will arrange all items automatically according to this preset order relation. The result of this is that at the front will always appear that element, which according to the ordering ist the 'order-maximal element'.
In the lecture a code-example has been shown.
The data structure linked list of the C++-STL is accompanied by a rich set of operations on the list or between two lists. The drawback of a linked list is that one can not address a certain item directly; in any case one has to follow the order of the list from the beginning or end until one can reach the position of the wanted item. But inserting new items or removing items can be done with minimal costs because one has not to change all the other items which are not 'touched' through insertion or deletion.
In the lecture a code-example has been shown.
One of the most interesting data structures is certainly the data structure set/ multiset of the C++-STL. For a user this structure looks like a set because you can insert and delet freely items. But internally this data structure is realized as a balanced binary tree (type: red-black tree).
In the lecture a code-example has been shown.
Even more interesting is the data structure map/ multim,map of the C++-STL. This is like the datastructure set, but additionally one can edit for every data item a 'key'. This turns a balanced binary tree into a balanced binary search tree. Examples of interesting applications are dictionaries an phonebooks as instances of associative arrays.
In the lecture a code-example has been shown.
(Remark: For the following exercises you can find the necessary detailed information about C++-Library functions in the ISO/IEC-C++ Standard 14882).
Stack: A stack is also called 'push down list', 'cellar', 'pile' or very often 'LIFO'-Register (:= Last In First Out). The original operations are push() --put an element on the stack-- and pop() --remove an element from the stack. The STL provides additionally the operation top() --show the element on top of the stack without removing it. There are several situations where the usage of a stack-data-structure is recommended. One is the parsing of expressions.
Describe an algorithm which is able to parse arithmetic expressions of the following form: op(x,y), where 'x' and 'y' are variables or again expressions of the form op(a,b). The operation op should be from the set {'+', '-', '*', '\'}. If the parameters 'x', 'y', 'a', 'b' are not expressions 'op(...)', then they should be of type int. The result of the algorithm should be the result of the arithmetical computation in the usual interpretation.
Define your own operations and show how an algorithm can parse and compute your operations.
Queue: a queue means 'waiting in line', is also called 'circular store' or 'FIFO'-Register ('First In First Out). The usual operations are enqueue (:= push()) and dequeue (:= pop()). The C++-Library offers additionally back() and front(), to show the last and the first element.
In a network you have N-many clients which can send print-orders to a printer P. In a timeinterval Dt lasting R-many timeunits T this should be O-many orders per interval where every order oi has a mean size of K-many pages. The orders will be collected in a queue Q. The printer P can print S-many pages per timeunit T. Define a function which computes the number of orders O' which should not be surpassed that every order will not longer wait then U-many timeunits T. .
Priority Queue: In a priority queue the content of the queue will automatically be ordered according to some ordering relation (e.g. less '<', greater '>'). Let us assume as in the case of the normal queue above that we have a queue for the management of the print-orders. Additionally to the example above we assume that the print-orders have some priority-numbers in the range [1,5] with 5 as the highest priority. We assume that we have the following mean frequencies measured for the different priorities: priority 5 = 5%, priority 4 =10%, priority 3 =20%, priority 2 = 30%, priority 1 35%. Define a function which computes the number of orders O', which should not be surpassed, that every order of any degree will not longer wait then U-many timeunits T.
Double Linked Lists: a double linked list --which we call here only a 'list'-- consists of elements, which are connected to pointers in 'both' directions, 'forward' and 'backward'.
Give a function to compute the search-time in the worst case, if a list of N elements is not ordered.
Give a function to compute the search-time in the worst case, if a list of N elements is ordered.
How 'big' are the costs of ordering in a list in the worst case?