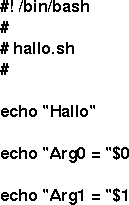C-KURS WS 01/02 - Theorie 1 - EinfuehrungAUTHOR: Gerd Döben-Henisch DATE OF FIRST GENERATION: Sept 7, 2001 DATE OF LAST CHANGE: Sept 27, 2001 EMAIL: Gerd Döben-Henisch |
|
Im Rahmen des Kurses Programmieren I werden noch keine Case
Tools benutzt. Um in einen 'direkten Kontakt mit der
Programmiersprache zu kommen, wird der Source-Code 'per Hand'
mittels eines Editors erstellt. Als Standard-Editor werden
wir xemacs benutzen. |
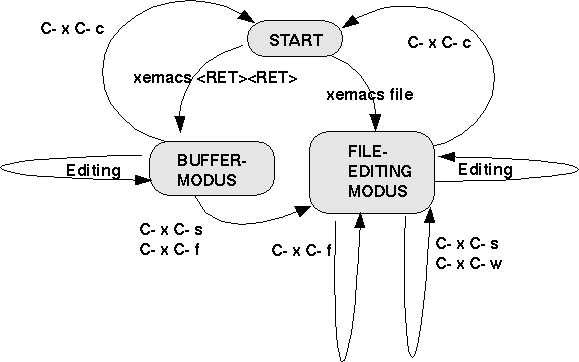
ProzesseDie Shell (in unserem Fall die Bash-Shell)
(Bash
für Windows) ist ein Programm, das unter dem
Betriebssystem Linux als ein permanenter Prozess läuft.
Sobald ein Benutzer sich anmeldet ('einlogged'), wird für
ihn eine Shell als Prozess mit eigener ID gestartet. Bei der
Abmeldung wird der Prozess wieder gestoppt. |
|
|
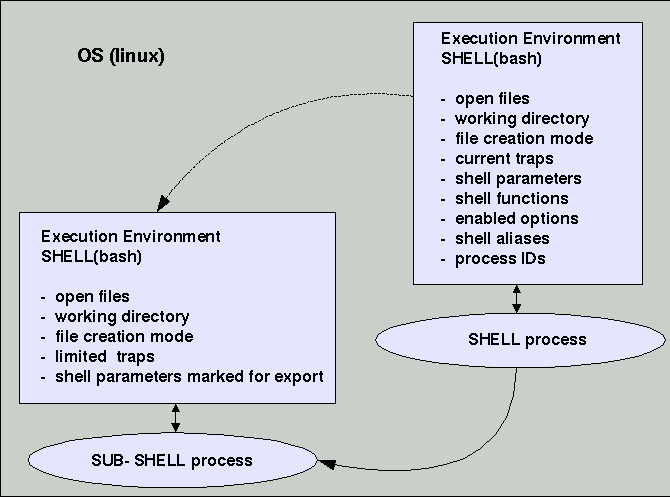
Startet eine Shell eine neue Sub-Shell, dann wird die Umgebung der aufrufenden Shell nur teilweise übernommen (siehe Schaubild). Insbesondere gilt, dass Veränderungen in der Sub-Shell nicht zurückwirken auf die Umgebung der aufrufenden Shell! Beispiel: Wenn man in der aufrufenden shell eine Variable V auf den Wert "wahr" setzt und die gleiche Variable in einer sub-Shell test1 auf den Wert "falsch", dann hat die Variable V im Bereich der Sub-Shell solange den Wert falsch, solange er nicht in der Sub-Shell geändert wird. Sobald die sub-Shell beendet wird und man die Variable 'V' wieder in der aufrufenden Shell benutzt, hat sie wieder den Wert "wahr". Man kann diese 'Abschottung' der Ausführungsumgebung dadurch aufheben, dass man eine Sub-Shell mit dem Befehl source sub-shell aufruft; dann übernimmt die Ausführungsumgebung der aufrufen Shell die Werte der Sub-Shell.
|
|
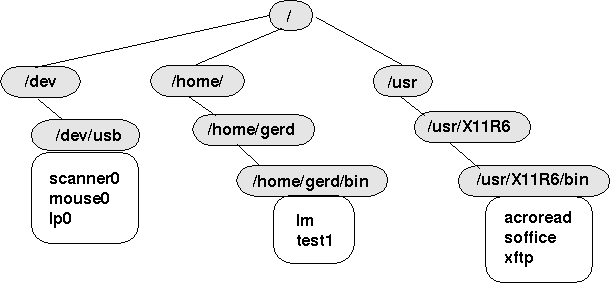
Zum Anzeigen des Inhalts eines
Verzeichnisses steht der Befehl ls mit diversen
Optionen zur Verfügung. Befände man sich im Verzeichnis
/home/gerd/bin, dann würde der Befehl ls die Ausgabe
liefern: lm test1.
|
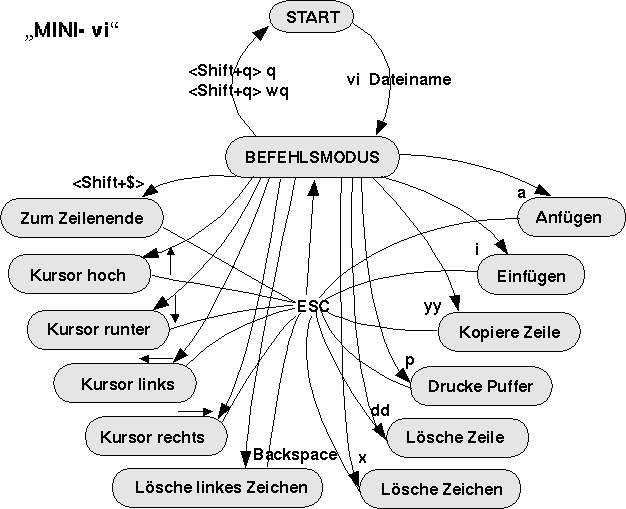
(ii) Mini xemacs
Für grössere Operationen mit Dateien bietet der
xemacs mehr Komfort als der vi. Da der tatsächliche
Befehlsumfang des xemacs sehr mächtig ist, seien hier
nur die wichtigsten Befehle kurz vorgestellt (siehe auch das
Schaubild).
|
|
|
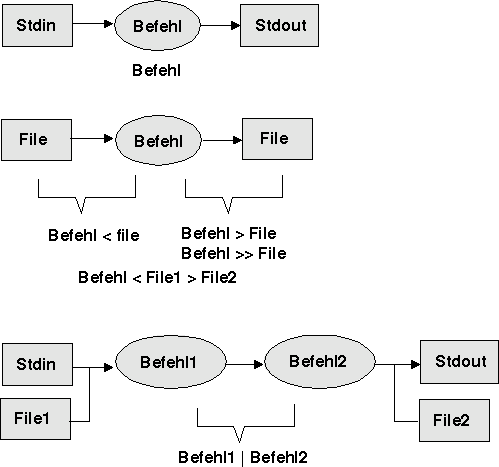
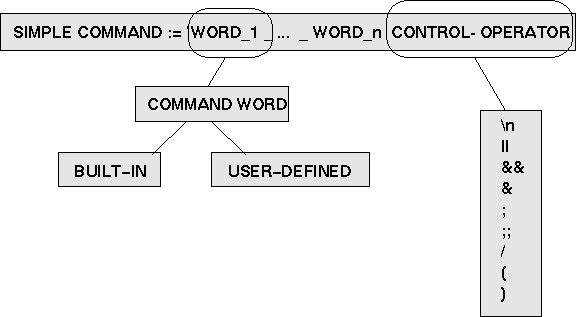
Ein einfacher Shell-Befehl ('simple command') besteht aus einer Folge von Worten, getrennt durch Leertasten, die durch einen Kontroll-Operator ('control operator') abgeschlossen werden (siehe Schaubild). Das erste Wort deines einfachen Befehls muss ein Befehlswort ('command word') sein. Als solche Befehlsworte stehen entweder die eingebauten ('built-in') befehlsworte zur Verfügung oder solche, die ein Benutzer definiert ('user defined') hat. Beispiele für eingebaute Befehlsworte sind: {cd, pwd, cp, rm, ls, ...}. Ein Benutzer kann eigene Befehlsworte definieren, indem er ein Shellscript file.sh schreibt, es als file.sh abspeichert und mittels chmod u+x file.sh dieser Datei Ausführungsrechte mittels des Befehls chmod zuweist. Den Befehl chmod u+x file.sh könnte man auch lesen: Ändere den Modus ('change mode' = 'chmod') der Datei file.h dahingehend, dass der Besitzer 'user' (= u) auf diese Datei auch Ausführungsrechte ('execute' = x) besitzt. Damit kann der Befehlsvorrat für die Shell beliebig erweitert werden. Das Ende der Wortkette wird durch die Kontrolloperatoren gebildet. Dabei ist der einfachste Kontrolloperator das Zeichen '\n' ('newline', 'Zeilenvorschub'). Dies wird beim Editieren des Shellscripts dadurch generiert, dass man am Zeilenende die <RET>-Taste drückt.
|
|
|
Ein einfaches Shellscript mit dem Namen hallo.sh ist nebenstehend abgebildet. In der ersten Zeile wird gesagt, dass dieses Skript durch das Programm bash mit dem Pfad /bin abgearbeitet werden soll. Geschützt durch ein Kommentarzeichen '#' wird der Name des Programms mit hallo.sh angegeben. Dann folgenden drei einfache Befehle. Jeder dieser Befehle ist durch den Kontrolloperator '\n' abgeschlossen. Das Befehlswort ist in jedem Fall das Wort echo. Die nachfolgenden Worte bilden jeweils Argumente für das Befehlswort echo. Bei dem ersten Befehl besteht das Argument aus dem Wort "Hallo", beim zweiten Befehl aus dem Wort "Arg0" konkateniert mit dem Inhalt des Shellparameters $0; entsprechend beim dritten Befehl. Die Konkatenierung von zwei Worten W1 und W2 bedeutet, dass zwei Wort zu einem Wort zusammengefügt werden. Im Falle von "Arg0 ="$0 ist dies nicht auf den ersten Blick sichtbar. Es gilt hier: W1 := "Arg0 =" und W2 := Der Inhalt des Shellparameters $0. Variablen und deren Inhalte werden weiter unten noch behandelt.
|
|
|
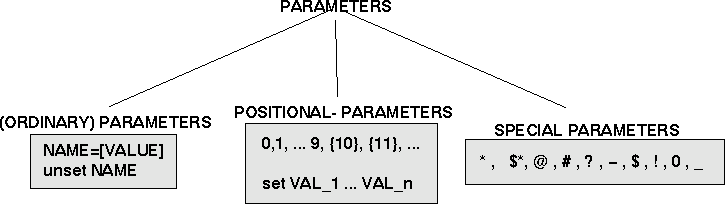
Shell-Parameter/ -Variablen Bezüglich der Verwendung der Terme Paramter bzw. Variable gibt es einen nicht ganz strikten Gebrauch im Kontext der Shell-Literatur. Deswegen hier kurze Bemerkungen zur Verwendung dieser Terme. In der Theorie der formalen Sprachen ist eine Variable normalerweise eine Zeichenkette, die im Rahmen von Substitutionsregeln durch bestimmte Werte eines Wertevorrates ersetzt ('substituiert') werden darf. Entsprechend wird der Begriff der Variablen auch in Programmiersprachen benutzt. In einer Variablen-Deklaration der Sprache C wird eine bestimmte Zeichenkette (der 'identifier', 'Variablenname') als Variable eingeführt und dieser ein Typ zugewiesen. Zusätzlich zu einer rein formalen Sprache (wie z.B. der Prädikatenlogik 1.Stufe) korrespondiert den Variablen einer Programmiersprache aber noch Speicherplatz ('storage allocation'). Dieser Speicherplatz ist zusätzlich charakterisierbar durch den Umfang und die zeitliche Dauer ('duration', 'extend'), weswegen Variablen von Programmiersprachen zusätzlich zum Datentyp auch noch hinsichtlich der Art und Weise der Speicherung ('Storage Classe Specifiers') definiert werden können (und müssen). Im Referenzpapier zur Bash-Shell wird nun statt von Variablen in manchen Kontexten auch von Parametern gesprochen. Wortwörtlich heisst es dort zu Parameter: "A parameter is an entity that stores values. It can be a name, a number, or one of the special characters listed below ( gemeint sind: {* , "$*", @ , # , ? , - , $ , ! , 0 , _ }). Diese Aussage ist schwer zu verstehen, denn einmal (i) wird gesagt, dass ein Parameter etwas sei, das Werte speichert; dies ist nach normalem Verständnis ein Speicherplatz. Zugleich (ii) wird aber auch von Zeichen ('characters') gesprochen, die Parameter repräsentieren. Und in der Tat sind Positional Parameters sowie Special Parameters bestimmte Zeichenketten, durch die Parameter repräsentiert werden. Im Text heisst es dann aber weiter: "For the shell's purposes, a variable is a parameter denoted by a name". Und "A parameter is set if it has been assigned a value. .... Once a variable is set, it may be unset only by using the unset builtin command. A variable may be assigned to by a statement of the form name=[value]...". Im weiteren Verlauf taucht der Term Variable dann garnicht mehr auf; es ist immer nur die Rede von Parametern. Von der Intention her 'scheint' es also so zu sein, dass mit dem Term Parameter ein Speicherplatz gemeint ist, der bestimmte Werte ('values') beinhalten kann, und dass die Kombination Name+Parameter eine Variable ergibt. Der tatsächliche Gebrauch des Terms ist nicht so klar. Man muss sich also entscheiden. Während ein Autor wie Rainer KRIENKE in seinem sehr lesenwerten Buch konsequent den Term Variable benutzt, wo das Bash-Shell Referenzpapier von Parametern spricht, wollen wir hier der Terminologie des Bash-Shell Referenzpapiers folgen und im Folgenden immer den Term Parameter benutzen. |
|
Die grobe Unterteilung bei den Parametern kann man dem nebenstehenden Schaubild entnehmen. Die (normalen) Parameter, das sind Zeichenketten ('Namen', 'identifier'), denen man durch das Gleichheitszeichen '=' einen Wert zuordnen kann. Gibt man keinen Wert an, wird automatisch eine leere Zeichenkette ('null string') als Wert angenommen. Mittels des Befehles unset kann man solche Wertzuweisungen wieder rückgängig machen. |
|
|
Positions Parameter werden von der Shell automatisch generiert, wenn einem Shellbefehl beim Aufruf Argumente übergeben werden. Die Zählung der übergebenen Argumente beginnt bei '1'. '1' ist also der Name des ersten Positionsparameters. Ab der Position '10' müssen die Ziffern, die Positionsparamter bezeichnen, mit geschweiften Klammern zusammengefasst werden, also '{11}' für das 11.Argument. Positionsparatern kann man zusätzlich nur durch set einen Wert zuweisen, z.B. set arg1 arg2 weisst dem Positionsparameter {1} den Wert 'arg1' zu und dem Positionsparameter {2} den Wert 'arg2'. Das Beispielskript parameter-demo.sh zusammen mit einer Wiedergabe der Shellausgabe daneben zeigt das Folgende: Zunächst wird mit echo zur Kontrolle der Wert der Positionsparameter 1 und 2 ausgegeben. Dann zum Vergleich der Wert der Spezial-Parameter '*' sowie '@'. Schliesslich werden die Werte der Positionsparameter 1 und 2 durch den Befehl set auf '111' bzw. '222' gesetzt. Ausserdem wird dem (gewöhnlichen) Parameter ''var' der Wert '333' zugewiesen. Mittels echo werden dann die Werte dieser Parameter erneut ausgegeben. Man sieht, dass die Werte der Positionsparameter verändert wurden; ebenfalls hat var den Wert '333' angenommen. Dann wird noch die Wirkung von unset bzgl. var demonstriert.
|
|
Die speziellen Parameter können nur gelesen werden. Ihre Werte werden ausschliesslich intern von der Shell selbst gesetzt. '*' Expandiert zu den Poitionsparametern, beginnend bei 1. "$*" ist gleichbedeutend mit "$1c$2c...", wobei c dem ersten Zeichen der IFS-Variablen entspricht. '@' Expandiert zu den Poitionsparametern, beginnend bei 1. "$@" ist gleichbedeutend mit "$1" "$2" . Wenn es keine Positionsparameter gibt, wird nichts expandiert. '#' Expandiert zur Anzahl der Positionsparameter (Dezimal) '?' Expandiert zum Exit-Status der zuletzt im Vordergrund ausgeführten Pipeline '-' Expandiert zu den aktuellen Options-Flags, entweder gesetzt durch den 'set'-Befehl oder durch die Shell selbst. '$' Expandiert zur Prozess-ID der Shell. In einer Subshell zur Prozess-ID der aufrufenden Shell. '!' Expandiert zur Prozess-ID des zuletzt im Hintergrund ausgeführten Befehls. '0' Expandiert zum Namen des Shellskripts. Wenn die Shell mit der '-c'-Option gestartet wird, dann ist $0 auf das erste Argument hinter der Zeichenkette gesetzt, die ausgeführt werden soll, falls vorhanden. '_' Beim Starten der Shell gesetzt auf den absoluten Dateinamen des auszuführenden Skripts entsprechend der Argumentliste. Anschliessend expandiert '_' zum letzten Argument des letzten Befehls; ebenfalls expandiert zum vollen Pfadnamen jedes ausgeführten Befehls. Beim Prüfen der Mail hält dieser Parameter den Namen der Mail-Files.
|
|
Shell-Funktionen Shell-Funktionen bilden ein Mittel, um Shell-Befehle so zu gruppieren, dass man sie wie einen einzigen Shell-Befehl nutzen kann. Dieser Befehl wird dann in der aktuellen Shellumgebung ausgeführt. Es wird kein eigener neuer Prozess erzeugt. Die Syntax des Befehls (siehe Schaubild) ist einfach. Das Keyword function (das optional ist) gefolgt von einem Namen, einem runden Klammerpaar und einer Liste von Befehlen in geschweiften Klammern mit einem abschliessenden Semikolon. Wird das Keyword function benutzt, dann sind die runden Klammern überflüssig. Wird die Funktion mit ihrem Namen aufgerufen, dann werden die Befehle aus der Befehlsliste ausgeführt. Der Exit-Status der Funktion ist entweder der Exit-Status des zuletzt ausgeführten Befehls oder jener Wert, der dem Befehl return als letztes übergeben wird. Wenn beim Aufruf der Funktion Argumente übergeben werden, dann werde diese den Positionsparametern der Fuktion übergeben. Der spezielle Parameter '#' wird zur Anzahl der Argumente expandiert. Variablen innerhalb einer Funktion können mit dem Keyword local als lokale Variablen deklariert werden. Ferner sind Funktionen rekursiv. Es gibt keine Begrenzung bzgl. der Anzahl der wiederholten Aufrufe.
|
|
|
Das nebenstehende Shell-Skript demonstriert auf einfache Weise, wie die Definition einer neuen Funktion mit Namen antwort im Text vor dem eigentlichen Shellskript stehen muss, damit die Funktion antwort im nachfolgenden Aufruf auch als neue Funktion erkannt wird. Da es normalerweise wichtig ist, über die Rückgabewerte von Funktionen informiert zu sein, muss es eine Möglichkeit geben, diese auszuwerten. Eine Variante wird im Skript demonstriert. Man fragt den speziellen Parameter $? unmittelbar nach der Ausführung der Funktion antwort ab, da dieser Parameter immer den Exitstatus der zuletzt ausgeführten Funktion repräsentiert. |
|
Nach dem Bash-Referenz Dokument finden nach der Aktivierung eines Shell-Befehls die folgenden Verarbeitungsschritte statt:
|
(1) Aufspaltung der Befehlszeile in Tokens |
|
(2) Klammer -Expansion ('brace-expansion') |
|
(3) Tilde-Expansion |
|
(4) Parameter-Expansion |
|
(5) Befehls-Substitution |
|
(6) Arithmetische Substitution |
|
(7) Aufspaltung von Worten |
|
(8) Dateinamen-Expansion |
|
Falls verfügbar, parallel zu (4) - (7) Prozesse-Substitution |
|
(9) Beseitigung von Anführungszeichen |
Für Details dieser Prozesse sei wieder auf das Bash-Referenz Dokument verwiesen. Hier nur einige erste Informationen.
|
(2) Klammer -Expansion ('brace-expansion') Dieser Expansion ist rein textuell. Bsp.: bash$ echo a{d,c,b}e ade ace abe Anwendungen: mkdir /usr/local/src/bash/{old,new,dist,bugs} chown root /usr/{ucb/{ex,edit},lib/{ex?.?*,how_ex}} |
|
(3) Tilde-Expansion '~' als Wert von $HOME führt zu folgenden Expansionen: ~/foo `$HOME/foo' '~+' als Wert von $PWD '~-' als Wert von $OLDPWD '~N' mit N als eine Zahl verweist auf das N-te element im Verzeichnis-Stack `dirs +N' '~+N' entpricht `dirs +N' '~-N' entspricht `dirs -N' |
|
(4) Parameter-Expansion ${parameter} ist die Grundform ${parameter:-word} Wenn der Parameter keinen Wert hat, dann wird dafür der Wert von Wort substituiert ('substituted'). ${parameter:=word} Wenn der Parameter keinen Wert hat, dann wird ihm der Wert von Wort zugeordnet ('assigned'). ${parameter:?word} Wenn der Parameter keinen Wert hat, dann wird die Expansion des Wortes nach Standard-Error und zur Shell geschrieben. Falls nicht interaktiv, dann Exit. ${parameter:+word} Wenn der Parameter keinen Wert hat, dann wird nichts substituiert. ${parameter:offset} ${parameter:offset:length} Beginnend beim Zeichen gekennzeichnet durch 'offset' wird der Parameter entweder um die Anzahl 'length' exandiert oder, falls 'length' fehlt, bis zum Ende. ${#parameter} Liefert die Länge der Zeichenkette, die als Wert im Parameter gespeichert ist.ubstituted is the number of elements in the array. ${parameter#word} ${parameter##word} Es wird das in 'word' gegebene Muster vom Wert des Parameters von links her entfernt. Bei '#' wird das kleinste passende, bei '##' das grösste passende Muster entfernt. ${parameter%word} ${parameter%%word} Analog zu '#' bzw. '##', nur von rechts nach links. ${parameter/[#,%]pattern/string} Das erste Vorkommnis von pattern im Wert von Parameter wird durch string ersetzt. ${parameter//[#,%]pattern/string} Alle solche Vorkommnisse werden ersetzt. Bei '#pattern' muss das Muster vom Anfang her matchen, bei '%pattern' vom Ende her. |
|
(5) Befehls-Substitution $(Befehl) oder `Befehl` Der Name des Befehls wird durch das Ergebnis der Befehlsausführung ersetzt. Bei Benutzung der Form $(Befehl) wird kein Zeichen zwischen den Klammern speziell behandelt. |
|
(6) Arithmetische Substitution $(( expression )) Alle Token innerhalb der Klammern durchlaufen Parameter-Expansion, Befehls-Substitution sowie Anführungszeichen-Entfernung. |
|
(7) Aufspaltung von Worten Die Shell analysiert die Ergebnisse der Parameter-Expansion, Befehls-Substitution und der arithmetischen Expansion, die nicht innerhalb doppelter Anführungszeichen vorkamen. Die Shell behandelt dabei jedes Zeichen von $IFS als ein Begrenzer, und spaltet das Ergebnis der anderen Expansionen in Worte zwischen den Begrenzern. Wenn der Wert von IFS Null ist, findet keine Aufspaltung von Worten statt. Explizite Null-Argumente ("" bzw. '') bleiben erhalten. Aufspaltung in Worte findet nicht statt, wenn es zu keiner Expansion kam. |
|
(8) Dateinamen-Expansion Sofern nicht mit 'set -f' Dateinamen-Expansion ausgeschaltet wurde, sucht die shell die Zeichenketten ab nach den Zeichen `*', `?', `(', and `['. Wird eines dieser Zeichen gefunden, dann wird das ganze Wort als ein Muster angesehen und durch eine alphabetisch sortierte Liste von Dateinamen, die dieses Muster matchen. Werden keine passenden Dateinamen gefunden und die Option ' nullglob' ist nicht aktiv, dann wird nichts getan. Ist ' nullglob' aktiv, dann wird das Wort entfernt. Mit der Option ' nocaseglob' kann man die Berücksichtigung von Gross-/Kleinschreibung ausschalten. Weitere wichtige Zeichen oder optionen sind '.', 'dotglob', 'nocaseglob', 'nullglob' , ' GLOBIGNORE'. |
|
Falls verfügbar, parallel zu (4) - (7) Prozesse-Substitution (list) oder >(list) oder <(list) Prozess-Substitution wird unterstützt von Systemen, die named pipes (FIFOs) oder die /dev/fd-Methode zur Benennung von offenen Dateien zur Verfügung stellen. Die Liste der Prozesse wird abgearbeitet und ihr Input wie auch ihr Output sind entweder an ein FIFO oder an eine Datei in '/dev/fd' gebunden. Der Name dieser Datei wird als Argument zum aktuellen Befehl als Ergebnis der Expansion durchgereicht. Wenn die form >(list) benutzt wird, dann liefert das Schreiben in die Datei Input für die Liste. Bei der Form <(list) muss der Dateiname, der durchgereicht wird, gelesen werden, um den Output der Liste zu bekommen. |
|
(9) Beseitigung von Anführungszeichen Nach Ausführung aller zuvor erwähnten Expansionen werden alle nicht durch Anführungszeichen gekennzeichnete Vorkommnisse der Zeichen `\', `'' und `"', die nicht das Ergebnis einer der zuvor ausgeführten Expansionen sind, entfernt. |